Research Scientist @GoogleDeepMind | PhD @UofT 🇨🇦 ex-@MetaAI @MSFTResearch | efficient ML · data · lifelong learning · AI agents |🏃♀️🎸🧘♀️🧋| made in 🇺🇦
Happy to share that I started a new role as a Research Scientist at Google DeepMind Toronto working with amazing @kswersk and the team! Looking forward to new adventures 🥳🤩🚀🇨🇦
DR Tulu has been selected for an oral presentation at ICML 2026 (0.7% of all submissions) 🥳
Check out our latest version, featuring additional ablations and a deeper analysis of RL with evolving rubrics for unverifiable open ended tasks!
Training multi-agent teams is hard.
#AgentFlow comes to the rescue. We introduce Flow-GRPO, an efficient method to train multi-agent teams. Improves planning and tool use.
Selected as an #ICLR2026 Oral (top 1%)🚀
"Why We Think" by Lilian Weng is a serious look at how LLMs reason. The argument: more thinking time doesn't automatically mean better reasoning. The inference strategy is what actually moves the needle. Technical and worth the 40 minutes.
https://t.co/ZJ6vwGN34p
Today we're releasing Gemma 4, our new family of open foundation models, built on the same research and technology as our Gemini 3 series. These models set a new standard for open intelligence, offering SOTA reasoning capabilities from edge-scale (2B and 4B w/ vision/audio) up to a 26B parameter MoE model and a 31B dense model. By releasing Gemma 4 under the Apache 2.0 license, we hope to enable more innovation across the research and developer communities. Our earlier Gemma 3 models were downloaded 400M times and over 100,000 variants of those models have been published, so we're excited to see what the community will do with the even better Gemma 4 models!
Learn more at https://t.co/BW6O3Gr8bc and https://t.co/8M0XSQSP4u
Great work by everyone involved!
#Gemma4 #AI #OpenSource #ML
It's my favorite kind of work: linear algebra insight + fast kernels.
When playing w Muon a while ago, we were thinking why not speed it up by operating on the small square matrix X X^T instead of the large rectangular matrix X. Jack, Noah, and Berlin spent many months understanding eigenvalues/vectors of the intermediate matrices in Muon, and finally came up with a simple and elegant algo to make this work.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
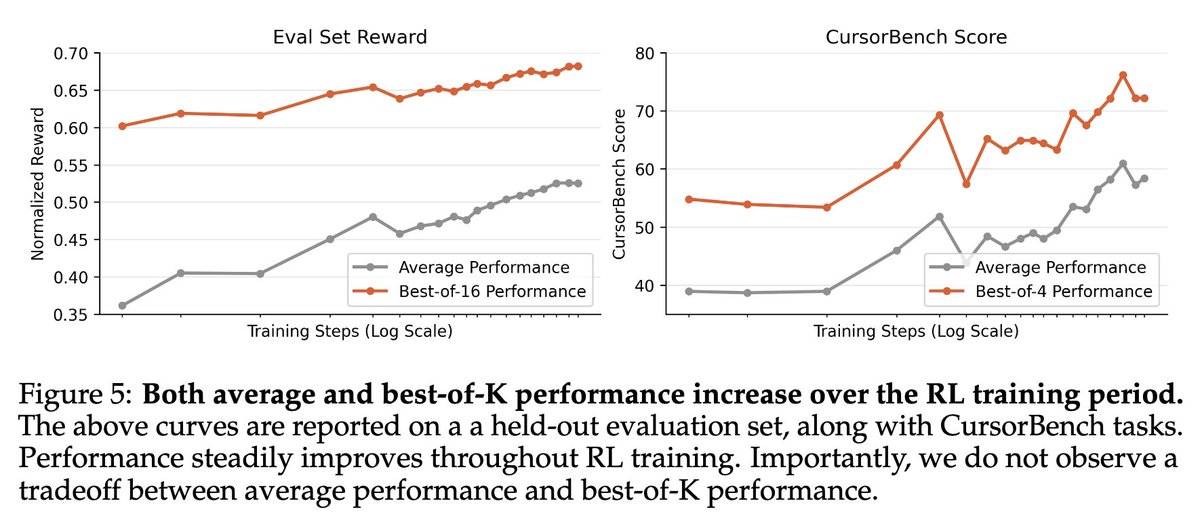
One gem from Composer paper is that RL improved both pass@k & pass@1. Suggests RL does not just reweigh existing capabilities but also teaches new ones? 💎
Google was just named #1 in the @FastCompany 2026 World’s Most Innovative Companies list. 🎉 Google is also ranked #1 in their Artificial Intelligence category. See the full story. https://t.co/SJYa8hgJVm
Really excited for the things @rosstaylor90 has been building to go out into the world. He's been one of the people I can always rely on to have non-cope takes on what we need to do to make the open ecosystem great.
What a great time in RL.
@jennyzhangzt@jennyzhangzt great work! So the improvement loop operates over programs and the meta-level improvement strategy without updating LLM weights. Do you see a viable extension where the system could safely incorporate gradient-based updates of the LLM itself?
Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself.
The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve.
We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving.
We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs.
This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).