Data Science meets classic poetry: a reinterpretation of Dante's Divine Comedy from the point of view of ML lifecycle!
https://t.co/CfmwtNKuCn
#chatgpt used to augment my skills and adapt the most famous parts of
• Inferno -> Data
• Purgatorio -> Modelling
• Paradiso -> Prod
As engineering, product, design, DS, etc. melt into a new kind of role, I was reflecting on what roles might look like in the future. For example, when I look at the Claude Code team I see what I think is five archetypes:
1. Prototyper: comes up with brand new ideas; churns out many ideas, most of which don't ship
2. Builder: quickly turns a prototype/idea into production-grade product/infra
3. Sweeper: cleans up the UI, simplifies the code and system, unships, optimizes performance
4. Grower: takes a product that has been built and iterates on it to improve Product-Market Fit
5. Maintainer: owns a mature system to make it secure, reliable, fast, and efficient as it scales
Many people span across 2 roles, and sometimes 3 roles. I also notice that these roles are not really tied to job function -- eg. across Anthropic, some designers match category 1, some 2, some 3; same for engineers, PM, DS.
A healthy team needs a mix of these, depending on the product:
- A product that is new and pre-PMF needs people that are strong at 1+2+3
- A product that is growing and has found PMF needs 2+3+4 and some 5
- A product that has strong PMF needs 3+4+5 and some 2
Maybe product roles of the future will look more like this, and less like the domain-specific roles of today?
🇮🇹 RIP Ferrari, the new Ferrari Luce looks like any other Chinese EV, even worse than top models. Teslas look better too.
The first electric Ferrari designed by LoveFrom is just terrible for a Ferrari. What is this? Ferrari is just a normie car brand now?
Enzo Ferrari is rolling in his grave. Just hire Pininfarina for the design FFS. A Ferrari must be beautiful, a piece of art first and foremost.
The $640K+ Ferrari Luce EV just shows how FAR ahead the Tesla Model S Plaid was compared to the rest of the EV industry.
Model S Plaid ($109,990):
• 0-60 mph in 1.99s
• 1,020 hp
• 368 Miles of Range
• 1/4 mile in 9.23s @ 155mph
• 0-124 mph in 6.2s
• Self-Driving
• Free Lifetime Supercharging
• Free Maintenance for 4 years
• 204 mph Top Speed w/Track Pack
• Seats 5 adults Comfortably
• Comfort Air Suspension
Ferrari Luce EV ($640,000):
• 0-60 mph in 2.4s
• 1,020 hp
• 280 miles of range
• 0-124 mph in 6.8s
• No Self-Driving
• 193 mph top speed
• Seating for 4
The Model S Plaid went out as one of the best performance cars ever. Legacy Auto can’t even catch up.
Spec comparison between Tesla Model S Plaid vs the newly unveiled Ferrari Luce
S Plaid vs Ferrari Luce
✅ Power: 1,020 hp 1,050 hp
✅ Motors: 3 4
✅ Battery: ~100 kWh 122 kWh
✅ Cx: 0.208 0.254
✅ Weight: 4,839 lbs 4,982lbs
✅ Charging: 250 kW 350 kW
✅ 0–60 mph: 1.99 s 2.4 s
✅ Range (EPA): 348 mi ~280 mi
✅ FSD: Yes No
✅ Price: $95k* $640k
*Model S is no longer on sale
Italy is the clearest example of how a rich country can slowly destroy itself through decades of bad management.
Since the late 1990s, Italy has had almost zero productivity growth.
Real wages have stagnated. And public debt is now around 137% of GDP, projected to move toward 139% overtaking Greece as the highest in the eurozone.
It is the result of 25 years of
1. Low innovation and very low adoption of new technologies
2. Family and insider succession in many companies, weakening meritocracy
3. Underdeveloped VC industry, startup ecosystem and R&D base
4. Political capture by lobbies and organised crime
5. Extreme administrative, judicial and business bureaucracy
6. Political fragmentation
7. Demographic collapse
No country can remain rich forever if productivity does not grow, debt keeps rising and politics only manages decline instead of reversing it.
Some things never change. If you don’t understand this one, you don’t understand what’s happening AI.
Marcus, 1998: neural nets have trouble generalizing far beyond the data.
Marcus, 2001, 2012, 2019, 2022, etc: neural nets have trouble generalizing far beyond the data.
Apple, 2025: neural nets have trouble generalizing far beyond the data.
Meta/Stanford/Harvard, 2026: neural nets have trouble generalizing far beyond the data.
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
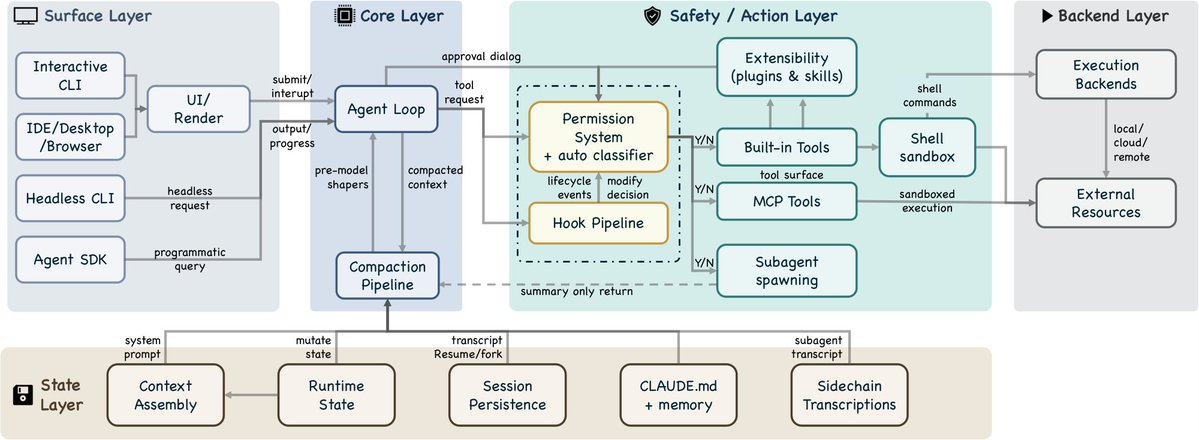
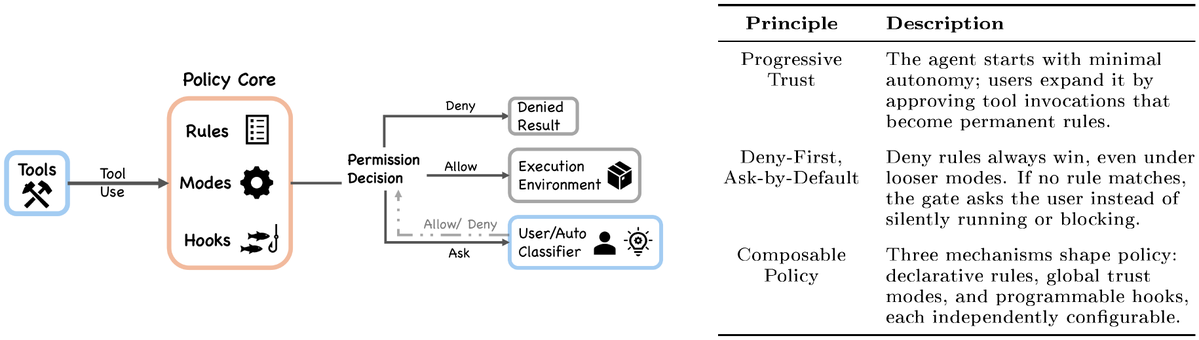
A must read for anyone interested in building practical AI systems in 2026:
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
The paper explains the architecture of a modern production-grade AI agent system (Claude Code) by analyzing its source code. This is what they call a "harness" of an agentic coding system.
Learn by reading with an AI tutor: https://t.co/sailmnkDcR
PDF: https://t.co/Jvl4HRMU4y
Excited to release the ML intern!
(slightly ahead of OpenAIs timeline)
It's the result of months of careful design and tuning for a compute and hub centric agent harness:
> give the model access to all the right docs and papers with minimal fraction
> let it run experiments on fast CPU and GPU instances and easily investigate logs
> push and pull datasets and models from and to the hub
While general coding agents can do all this as well, making execution as seamless as possible gives the agent a significant advantage.
Excited to release the ML intern!
(slightly ahead of OpenAIs timeline)
It's the result of months of careful design and tuning for a compute and hub centric agent harness:
> give the model access to all the right docs and papers with minimal fraction
> let it run experiments on fast CPU and GPU instances and easily investigate logs
> push and pull datasets and models from and to the hub
While general coding agents can do all this as well, making execution as seamless as possible gives the agent a significant advantage.
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Good design is the art of packing 1,000 "hows" into a single "what". Good design is compression: making the numerator trend towards infinity while the denominator stays at 1.
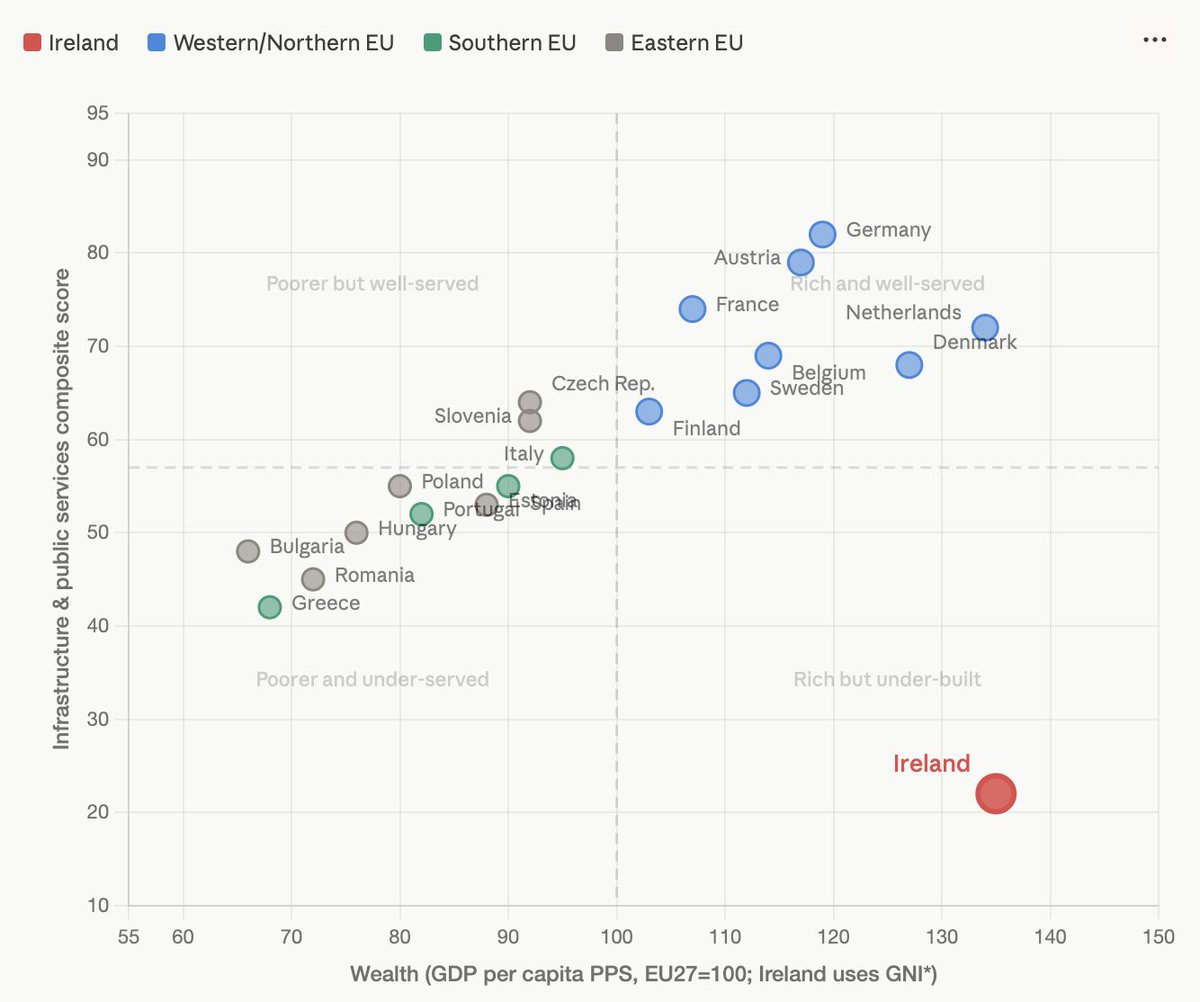
The protests in Ireland are not about just fuel! They are about the distance between Ireland on this graph and every other modern and developed economy. Ireland is second wealthiest but gets waaaaay less than any other country for that wealth. By a golden mile.
That visual gap in this graph? That’s what people are protesting. It’s a lack of infrastructure and the everyday enshittification of services, the economy, and the additional difficulty of trying to live, relative to peers in any other country. It also highlights why people don’t get uniformly listened to! - because there is no government architecture to engage meaningfully across this huge gap.
That gap is a three hour drive to work in traffic, a 14 month wait for an MRI, buses that don’t arrive, trains that don’t exist, schools that have no places for your kids, houses that are unaffordable, pubs that close before midnight, €12 sandwiches, expensive fuel.
People feel this gap, even if they can’t explain it precisely. And that builds into resentment, and ultimately protest. Fuel just happened to be the next thing that could be pointed to, today.