Congratulations to U of A computing science professor Richard Sutton, a trailblazer in reinforcement learning, on receiving the 2024 A.M. Turing Award—often called the "Nobel Prize of computing"!
His groundbreaking work continues to shape the future of AI. Read more: https://t.co/iJfeisEVga
@AmiiThinks@ualbertaScience@TheOfficialACM
BREAKING: Amii Chief Scientific Advisor, Richard S. Sutton, has been awarded the A.M. Turing Award, the highest honour in computer science, alongside Andrew Barto! Read the official @TheOfficialACM announcement: https://t.co/JXDhdEsQv7
#TuringAward#AI#ReinforcementLearning
📢 It's here! The second edition of my book "Performance Analysis and Tuning on Modern CPUs" is out NOW!
Dive into low-level optimizations and learn to write fast code like a pro.
Grab your copy: https://t.co/E5wGVuuV36
Please RT to spread the word!
#NewBook#BookRelease
🧵1/3
Sun glint off the Mediterranean Sea (infrared and converted to black and white). When the sun reflects off the ocean, watery details unseen with normal lighting shows up. Small centimeter differences in ocean height become visible, revealing hidden currents.
Here, naturally swirling vortices are seen, about a kilometer in diameter, often lasting for days. Ship wakes cutting through the swirls show up as black lines and can last for hours (second photo shows the ship). Amazing how an orbital vantage can give new observations about our world impossible to see when feet are on the ground (or on a ship).
Nikon Z9 IR modified, Nikon 200mm lens, 1/10000 second, f11, ISO 500.
Announcing the Luiz André Barroso Award!
The award recognizes and celebrates researchers from historically underrepresented communities who have made fundamental contributions to computer science.
Learn how to nominate here: https://t.co/EwjpZj2P7m
#ACMAwards#Computing
Breakthrough discoveries rarely happen overnight. Innovation is powered by iteration—it's the desire to dig deeper, test more and explore beyond the surface that pushes us to achieve the unthinkable and pave the way toward a better tomorrow.
I wasted a bunch of time trying to figure out why xterm starts so slowly on Windows... and solved it with a dumb LD_PRELOAD hack 😆 https://t.co/1CJSTb6fxB
Performance tip: avoid unnecessary copies
Copying data in software is cheap, but it is not at all free. As you start optimizing your code, you might find that copies become a performance bottleneck.
Let me be clear that copies really are cheap. It is often more performant to copy that data than to track the same memory across different threads. The case I am interested in is when copies turn a trivial operation into one that is relatively expensive.
Recently, the fast JavaScript runtime (Bun) optimized its base64 decoding routines.Base64 is a technique used to represent binary data, like images or files, as ASCII text. It is ubiquitous on the Internet (email formats, XML, JSON, HTML and so forth). In Node.js and in Bun, you can decode a base64 string Buffer.from(s, "base64").
Importantly, when decoding base64 strings, you can be almost certain that you are dealing with a simple ASCII string. And systems like Node.js and Bun have optimized string representations for the ASCII case, using one byte per character.
We had optimized base64 decoding in Node.js some time ago (credit to Yagiz Nizipli for his work)… but I was surprised to learn that Bun was able to beat Node.js by a factor of three. Because both Node.js and Bun use the same base64 decoding, I was confused.
I mistakenly thought, based on quick profiling, that Node.js would copy the base64 data from an ASCII format (one byte per character) to a UTF-16 format (two bytes per character) despite our best attempt at avoiding copies.
It turns out that the copy was not happening as part of base64 decoding but in a completely separate function. There is an innocuous function in Node.js called StringBytes::Size which basically must provide an upper on the memory needed by the Buffer.from function. Since the early versions of Node.js, it would allocate memory to compute the size of the output:
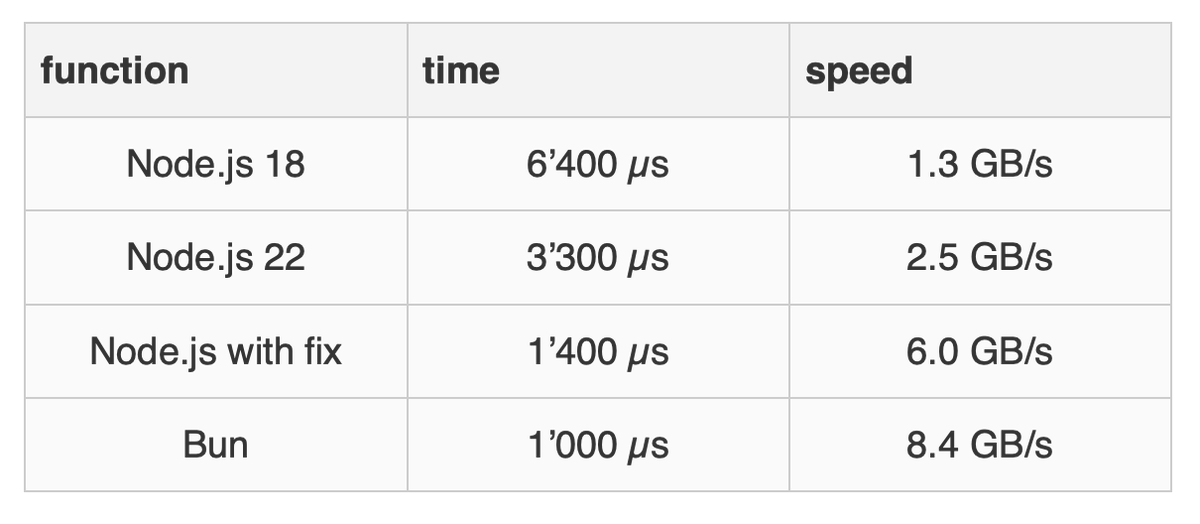
I install the latest version of Bun (bun upgrade --canary). I compare Node.js 22 with a patched version. I use my Apple MacBook for testing (ARM-based M2 processor). You can see that by simply avoiding the unnecessary copy, I boosted the base64 decoding from 2.5 GB/s to 6.0 GB/s. Not bad for removing a single line of code.
Sometimes people observe at this point that the performance of Node.js 18 was already fine: 1.3 GB/s is plenty fast. It might be fast enough, but you must take into account that we are measuring a single operation that is likely part of a string of operations. In practice, you do not just ingest base64 data. You do some work before and some work after. Maybe you decoded a JPEG image that was stored in base64, and next you might need to decode the JPEG and push it to the screen. And so forth. To have an overall fast system, every component should be fast.
You may observe that Bun is still faster than Node.js, even after I claim to have patched this issue. But there are likely other architecture issues that Bun does not have. Remember that both Node.js and Bun are using the same library in this instance: simdutf.
It is maybe interesting to review Bun’s code (in Zig):
It is far simpler than the equivalent in Node where memory is allocated in one function, and then the resulting buffer is passed to another function where the decoding finally happens. It is likely that Bun is faster because it has a simpler architecture where it is easier to see where the unnecessary work happens.