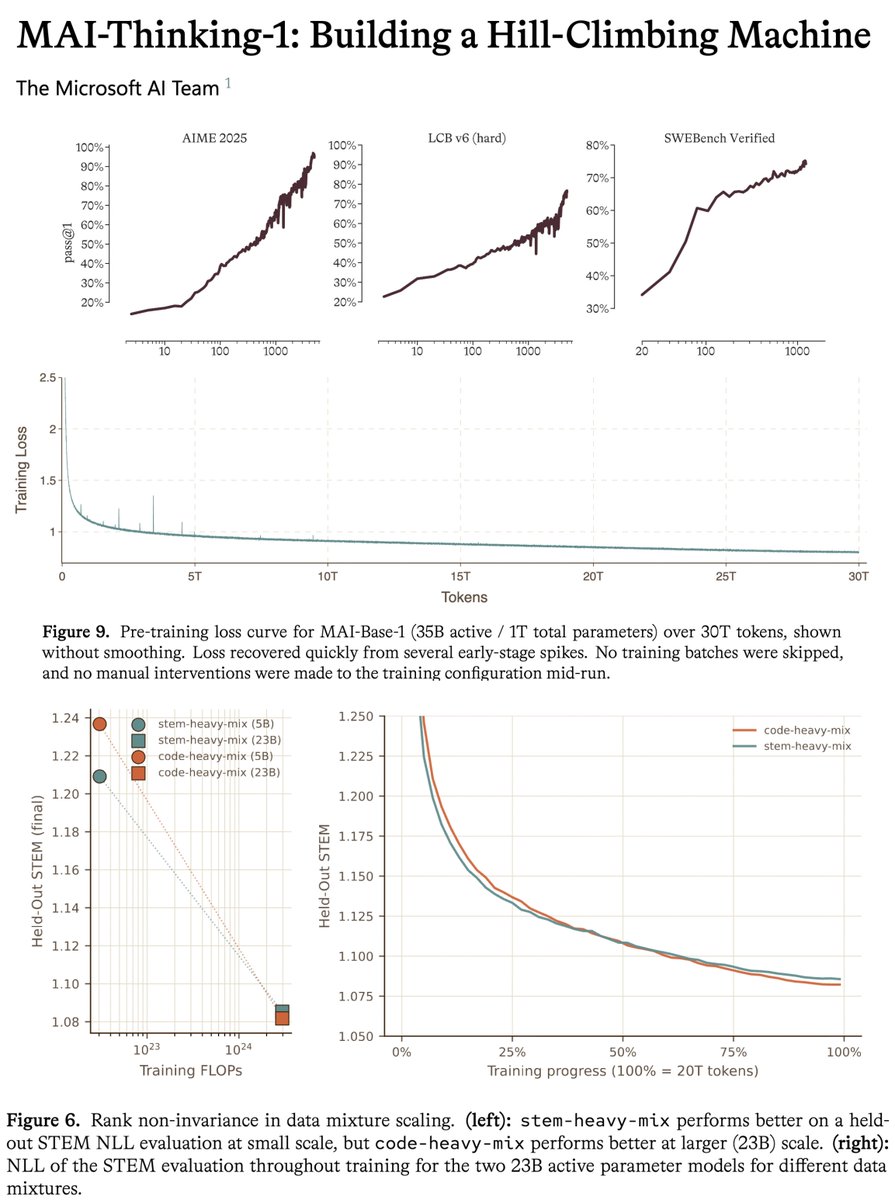
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
New blog! Is frontier asynchronous RL solved?
The blog covers Async RL theory and infrastructure, surveying 8 open-weight frontier labs for the algorithmic techniques and systems fixes to handle train-inference mismatch. Also answered: why do current methods still fail at high policy lag? Which methods scale with horizon and compute?
wow, amazing tech report. lots of details on every part of the pipeline, especially on data. love that they share the system design of how they train models and do research with their "model factory", and also the negative results from M1 and how they fixed them in XS.2
one of the best tech reports to get up to speed on model training
2/ Model Factory
The central idea in the report is the Model Factory.
It is the internal stack we use to make model development compound across runs: versioned data, reusable training, inference, and eval components, experiments as code, and lineage across runs, checkpoints, evals, and deployments.
That is what lets us take lessons from M.1 and apply them to XS.2 quickly, from the start of training to release in about five weeks.
See the top ranked papers in AI, ML, Robotics, Quantum Physics, and more on @kurateorg. Hundreds of arXiv preprints ranked daily by scientific impact through pairwise tournaments judged by Claude, GPT, and Gemini.
Added a DeepSeek Sparse Attention (DSA) from-scratch implementation to my LLMs-from-scratch repo thanks to an awesome new reader contrib.
With motivation, overview, and GPT-style model reference implementation as standalone example code: https://t.co/o2PMhjF0TN
Correctness is critical for LLM inference engines. Recently, I found TRT-LLM’s work on Hypothesis Testing Methodology to be extremely professional.
https://t.co/Qr1CLCIQ06
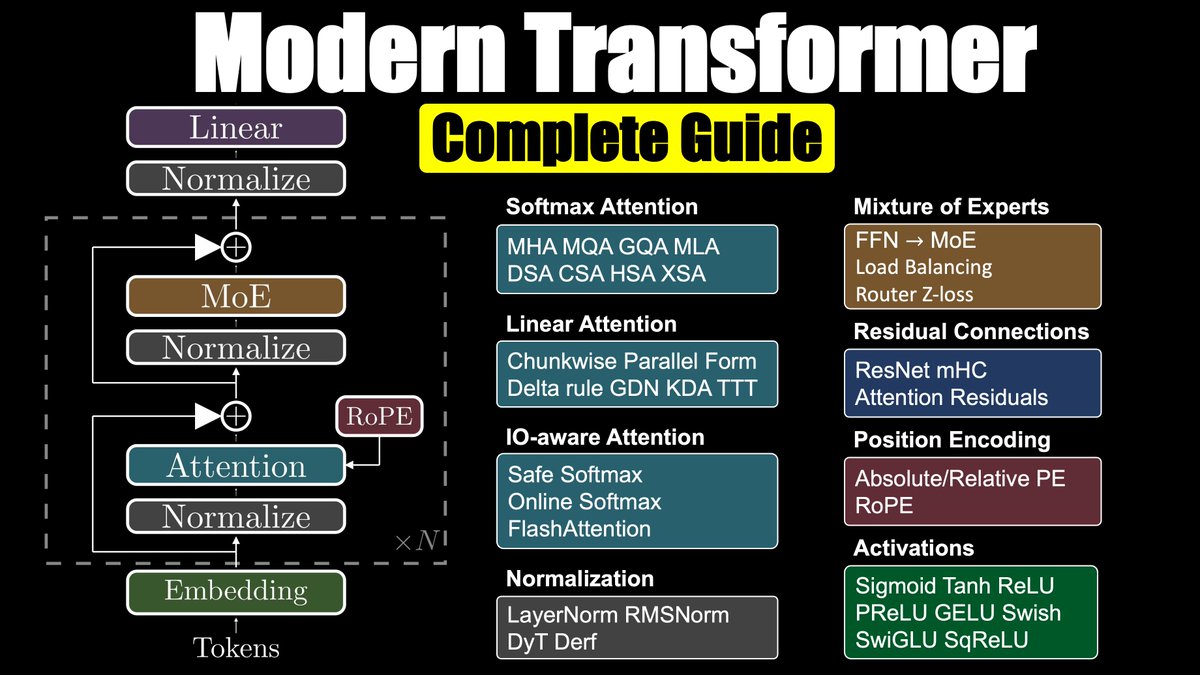
Modern Transformer - Complete Guide
Interested in learning the recent advances in transformers?
After 13 videos, I've finally completed this series!
🥳🥳🥳
Check out the course here:
https://t.co/CsujxlWigC
Today we release Token Superposition Training (TST), a modification to the standard LLM pretraining loop that produces a 2-3× wall-clock speedup at matched FLOPs without changing the model architecture, optimizer, tokenizer, or training data.
During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings on the input side and predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, it trains normally on next-token prediction. The inference-time model is identical to one produced by conventional pretraining.
Validated at 270M, 600M, and 3B dense scales, and at 10B-A1B MoE.
The work on TST was led by @bloc97_, @gigant_theo, and @theemozilla.
Making inference more efficient,
"Insights From NVIDIA Research", Bill Dally, GTC 2026, Mar 19 https://t.co/uFfnDFKUSk
Stacked Memory https://t.co/mddrV4cqxs
On-Chip NW https://t.co/alk1g3z1sA
FG-DRAM https://t.co/eTWpdRennN
Origins of GPU Comp, Apr 13 https://t.co/CjLE8m6HDS
"Python is a simple language" 🤡🤡
I hate this language. Spent 3 days debugging this hellish NCCL. Turns out a single Python regex was holding the GIL hostage while 15 H100s waited for rank 0 to show up.
It was https://t.co/0CdQwq23Ag(). It's always https://t.co/0CdQwq23Ag().
Fastokens is officially merged into SGLang. This is an open-source Rust BPE tokenizer from @CrusoeAI, built with @nvidia Dynamo.
→ Up to 50% faster TTFT on agentic workloads (real production traffic)
→ 10x+ average speedup over HuggingFace tokenizers
→ Works across DeepSeek, Qwen, Kimi, MiniMax, Nemotron, and more
Huge thanks to the @CrusoeAI team for the collab.
Related SGLang PR: https://t.co/FDRLtSDwgb
Really cool
When they trained GPT3 they had loss spikes because they scraped from a subreddit of microwave noises
That training batch was literally text like "mmmmmmmmmmmmmmm"
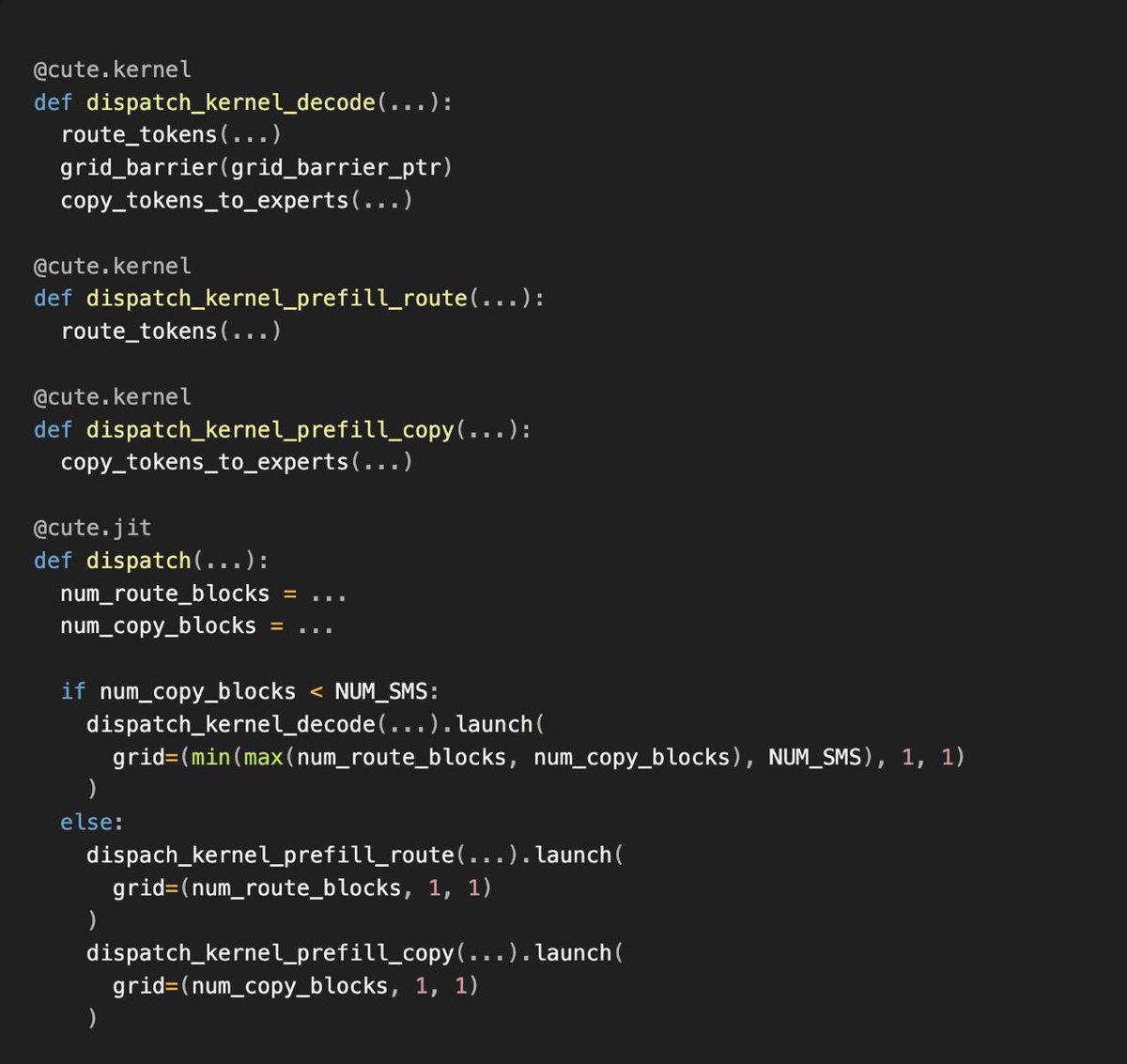
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ranging from embeddings to trillion-parameter LLMs.
With CuTeDSL integrated into our inference engine, Perplexity can build the specialized GPU kernels faster to bring models up to peak performance on NVIDIA Hopper and Blackwell GPUs.
For the past 12 years, cuDNN has been completely closed sourced (besides the .h files), until this week! OVER 20 MoE kernels & NSA sparse attention kernels from cuDNN has been open sourced! Great work to @manicely6005 & the rest of the team on seeing that parts of NVIDIA are moving towards open kernels! open source kernels drive innovation! (1/3) 🧵
There’s a serious gap in multimodal models – they work with images, but still reason in language, which isn’t that precise for visual stuff.
@deepseek_ai just dropped an idea to solve this: let the model literally point to exact locations in the image while it thinks.
They call it "Thinking with Visual Primitives."
These visual primitives are:
- points (specific locations)
- bounding boxes (areas in the image)
Using them, the model knows what exactly it’s referring to and achieves ~77% better accuracy on average (vs. Gemini 3 Flash's 76.5% and 71.1% for GPT-5.4)
Plus, only ~80–90 visual tokens are kept in memory after compression thanks to the efficient architecture
Here is how it works: