@vijaypande Hi! 👋 we’ve been building the prediction engine to not only predict the trial outcomes but the clinically actionable results. DM if you’re interested in learning more!
Raises the question: for ML, what is value of large single-cell perturbation screens in homogenous cell populations, i.e. the vast majority of currently available data + what so many organizations are racing to generate
That is still unanswered...
The training data market has exploded for LLMs and bio foundation models are next.
But biological data is extremely complex and requires a data generation playbook that prioritizes quality over immediate scale.
@_DimensionCap Research article live now!
https://t.co/3CqSYADLJP
The training data market has exploded for LLMs and bio foundation models are next.
But biological data is extremely complex and requires a data generation playbook that prioritizes quality over immediate scale.
@_DimensionCap Research article live now!
https://t.co/3CqSYADLJP
@SylvainGariel Some things are impossible, until suddenly they aren’t and nothing is ever the same anymore. Fantastic results and fantastic efforts by the scientific and pharma community.
if you’re an ai researcher you should really consider working on bio
pretraining is great: data sets are big enough for interesting stuff but not so big you’re spending all your time on weird cluster optimization
post training is in the age of research:
the lab is the only true validation, but it’s expensive so figuring out the limits of what we can do for evals in silico is still very open question
existing stuff kind of works: we have proof of life for the ability of ai to accelerate bio but there is a long way to go
it feels a lot like computer vision after imagenet or nlp after the first transformers started really working
if your idea works, you might get to help improve the human condition. way cooler to talk about at parties than “we pushed benchmark X for chat model Y up by 3 point”
if you’re an ai researcher you should really consider working on bio
pretraining is great: data sets are big enough for interesting stuff but not so big you’re spending all your time on weird cluster optimization
post training is in the age of research:
the lab is the only true validation, but it’s expensive so figuring out the limits of what we can do for evals in silico is still very open question
existing stuff kind of works: we have proof of life for the ability of ai to accelerate bio but there is a long way to go
it feels a lot like computer vision after imagenet or nlp after the first transformers started really working
if your idea works, you might get to help improve the human condition. way cooler to talk about at parties than “we pushed benchmark X for chat model Y up by 3 point”
@anshulkundaje@rlacombe But what it means conversely, is that these kinds of perturbation prediction models need to think backwards : what’s the data modality that contains the relevant information for this kind of prediction.
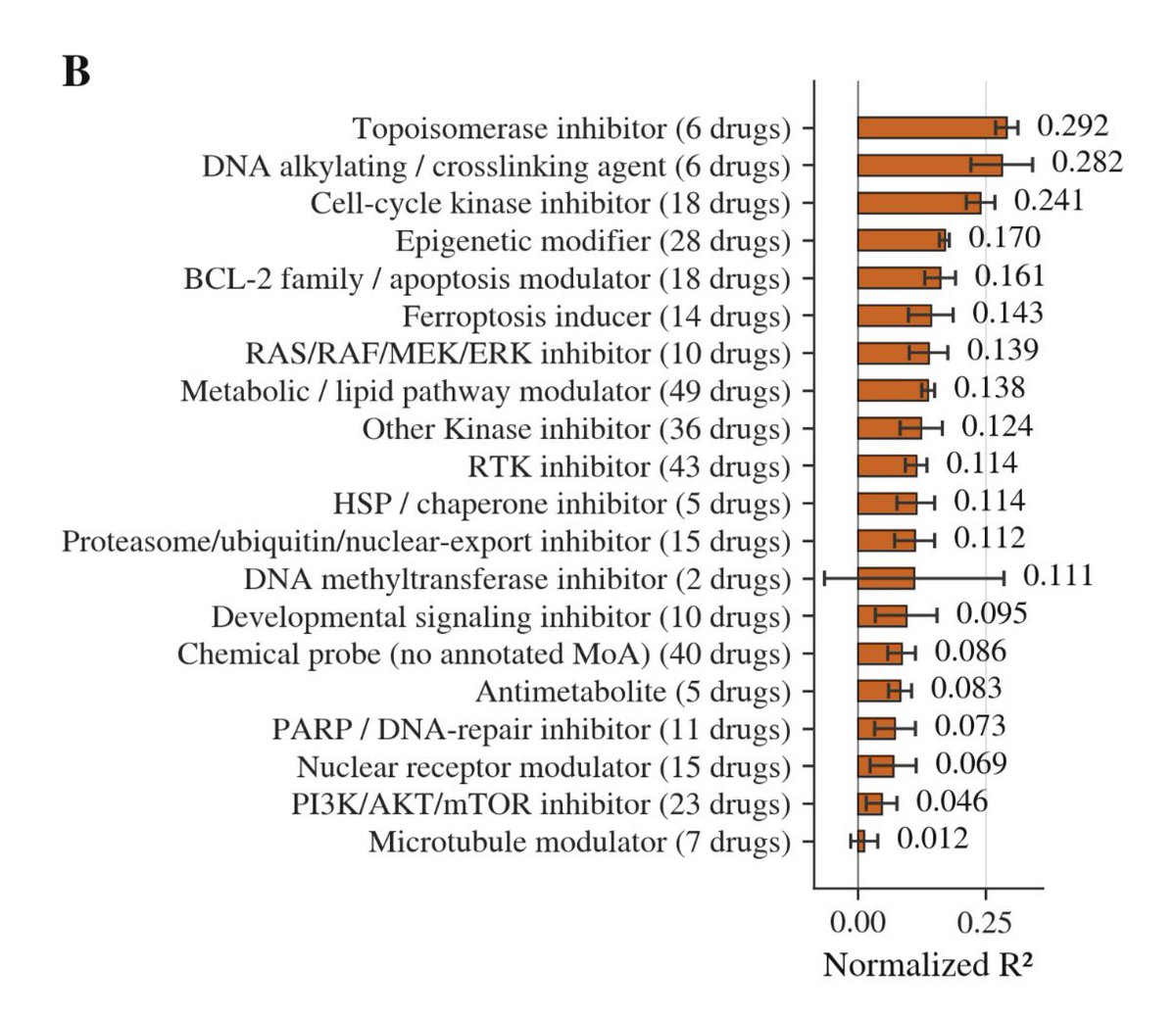
@anshulkundaje@rlacombe We’ve been working on drug perturbation prediction models. Using public data (hence RNA-based AI models) you see that there is a huge spread in perf depending on the drug MoA. This is obvious if you think about it!
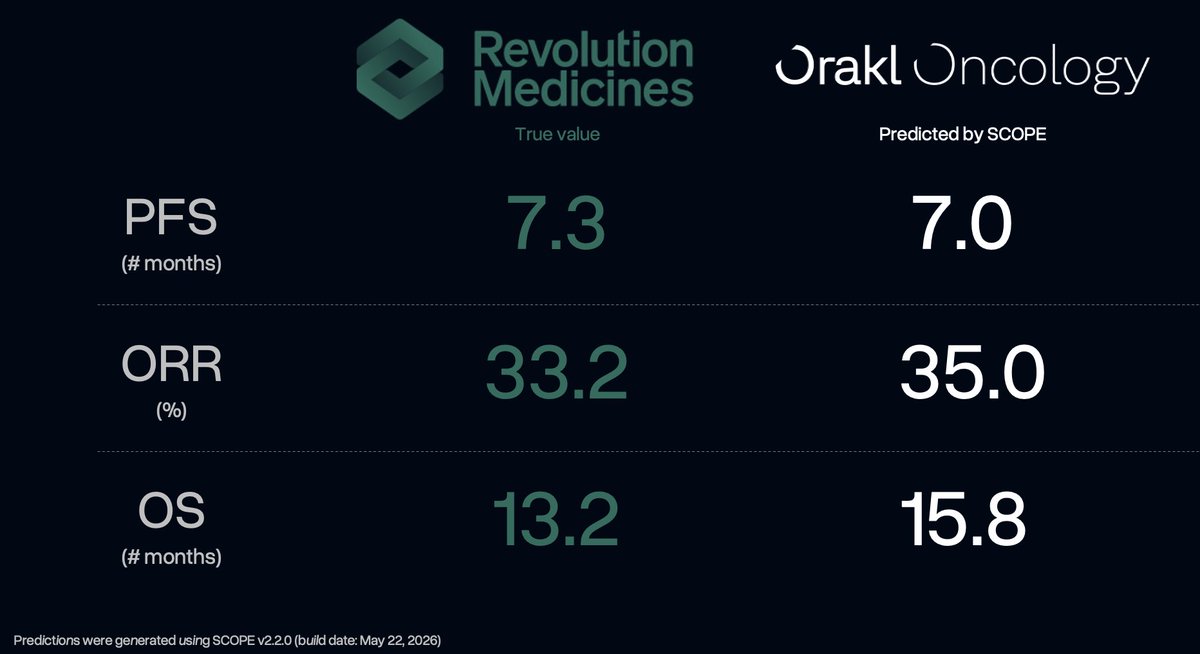
@drrichjlaw@PheironAI It’s very cool to see clinical trial outcome and prediction become a core topic! Curious to see what you think of some of the work we’ve been doing at @orakldotbio
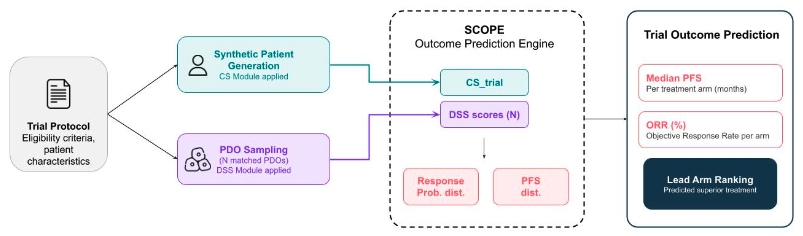
Introducing SCOPE (Screening-to-Clinical Outcome Prediction Engine): a translational platform integrating patient-derived organoid (PDO) drug screening with clinical prognostic features to forecast arm-level efficacy in oncology trials.