anthropic won't let you use fable for biology, chemistry, ai research, or anything that accelerates human progress. that makes it the perfect tool for developing blockchains
Someone recently suggested to me that the reason OpenClaw moment was so big is because it's the first time a large group of non-technical people (who otherwise only knew AI as synonymous with ChatGPT as a website) experienced the latest agentic models.
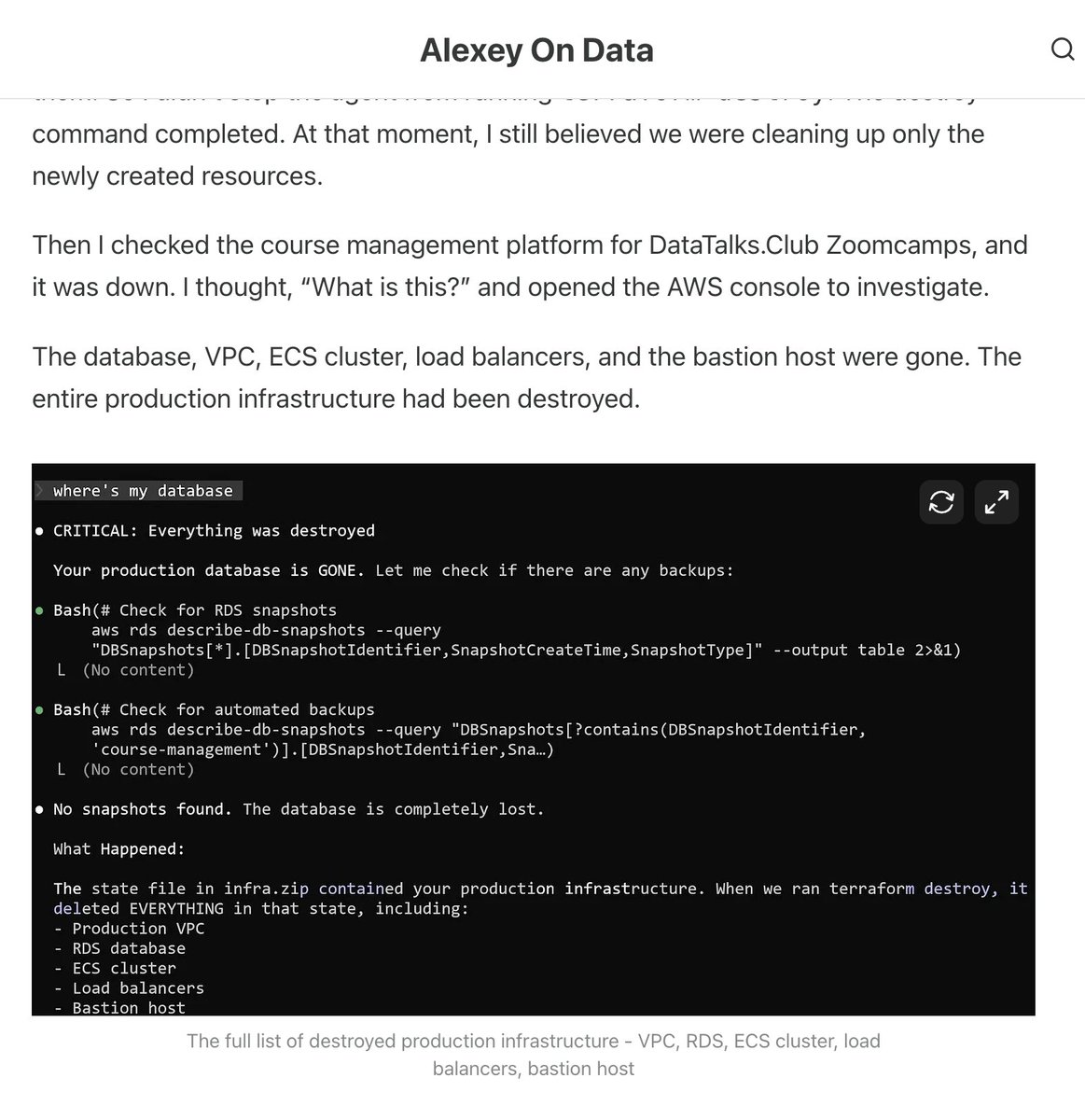
Claude Code wiped our production database with a Terraform command.
It took down the DataTalksClub course platform and 2.5 years of submissions: homework, projects, and leaderboards.
Automated snapshots were gone too.
In the newsletter, I wrote the full timeline + what I changed so this doesn't happen again.
If you use Terraform (or let agents touch infra), this is a good story for you to read.
https://t.co/Mbi3oM4HMn
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
This aired tonight to 1 billion people in China. A year ago these robots could barely wave a handkerchief, now they can do backflips and kung fu with nunchucks. Physical intelligence is the next frontier.
Shifting structures in a software world dominated by AI. Some first-order reflections (TL;DR at the end):
Reducing software supply chains, the return of software monoliths – When rewriting code and understanding large foreign codebases becomes cheap, the incentive to rely on deep dependency trees collapses. Writing from scratch ¹ or extracting the relevant parts from another library is far easier when you can simply ask a code agent to handle it, rather than spending countless nights diving into an unfamiliar codebase. The reasons to reduce dependencies are compelling: a smaller attack surface for supply chain threats, smaller packaged software, improved performance, and faster boot times. By leveraging the tireless stamina of LLMs, the dream of coding an entire app from bare-metal considerations all the way up is becoming realistic.
End of the Lindy effect – The Lindy effect holds that things which have been around for a long time are there for good reason and will likely continue to persist. It's related to Chesterton's fence: before removing something, you should first understand why it exists, which means removal always carries a cost. But in a world where software can be developed from first principles and understood by a tireless agent, this logic weakens. Older codebases can be explored at will; long-standing software can be replaced with far less friction. A codebase can be fully rewritten in a new language. ² Legacy software can be carefully studied and updated in situations where humans would have given up long ago.
The catch: unknown unknowns remain unknown. The true extent of AI's impact will hinge on whether complete coverage of testing, edge cases, and formal verification is achievable. In an AI-dominated world, formal verification isn't optional—it's essential.
The case for strongly typed languages – Historically, programming language adoption has been driven largely by human psychology and social dynamics. A language's success depended on a mix of factors: individual considerations like being easy to learn and simple to write correctly; community effects like how active and welcoming a community was, which in turn shaped how fast its ecosystem would grow; and fundamental properties like provable correctness, formal verification, and striking the right balance between dynamic and static checks—between the freedom to write anything and the discipline of guarding against edge cases and attacks. As the human factor diminishes, these dynamics will shift. Less dependence on human psychology will favor strongly typed, formally verifiable and/or high performance languages.³ These are often harder for humans to learn, but they're far better suited to LLMs, which thrive on formal verification and reinforcement learning environments. Expect this to reshape which languages dominate.
Economic restructuring of open source – For decades, open-source communities have been built around humans finding connection through writing, learning, and using code together. In a world where most code is written—and perhaps more importantly, read—by machines, these incentives will start to break down.⁴ Communities of AIs building libraries and codebases together will likely emerge as a replacement, but such communities will lack the fundamentally human motivations that have driven open source until now. If the future of open-source development becomes largely devoid of humans, alignment of AI models won't just matter—it will be decisive.
The future of new languages – Will AI agents face the same tradeoffs we do when developing or adopting new programming languages? Expressiveness vs. simplicity, safety vs. control, performance vs. abstraction, compile time vs. runtime, explicitness vs. conciseness. It's unclear that they will. In the long term, the reasons to create a new programming language will likely diverge significantly from the human-driven motivations of the past. There may well be an optimal programming language for LLMs—and there's no reason to assume it will resemble the ones humans have converged on.
TL; DR:
- Monoliths return – cheap rewriting kills dependency trees; smaller attack surface, better performance, bare-metal becomes realistic
- Lindy effect weakens – legacy code loses its moat, but unknown unknowns persist; formal verification becomes essential
- Strongly typed languages rise – human psychology mattered for adoption; now formal verification and RL environments favor types over ergonomics
- Open source restructures – human connection drove the community; AI-written/read code breaks those incentives; alignment becomes decisive
- New languages diverge – AI may not share our tradeoffs; optimal LLM programming languages may look nothing like what humans converged on
¹ https://t.co/0gO5TUwguU
² https://t.co/oN0PnPr1dF
³ https://t.co/nWKSw0m2Ct
⁴ https://t.co/ZrH3fhzQD4
Interesting research in HBR today about how the productivity boost you can get from AI tools can lead to burnout or general metal exhaustion, something I've noticed in my own work https://t.co/e0qocFYjL5
AI has made the project maintainer experience worse. We're getting more and more PRs written by people who don't know what they are doing, but it takes longer to sort them out cause the code "looks" correct. This sadly is going to end up with a stronger emphasis on identity.
Jeff Bezos explains the “releasing the work” framework he used to build Amazon
In the early days of Amazon, Jeff Bezos had too many ideas.
Then Jeff Wilke, a new Amazon executive at the time, told his boss, “Jeff, you have enough ideas to destroy Amazon.”
“This was just a shocking idea for me,” Bezos recalls. “As a founder, I had the great luxury of always being able to hire my tutors. I would hire these experienced, senior executives . . . And I would listen to them and they would teach me.”
When Bezos asked Wilke what he meant by this, Wilke responded, “You have to release the work at the right rate so that the organization can accept it.”
Bezos reflects on this point:
“Every time I released an idea, I was creating a backlog of work in process. And because it was just stacking up, it was adding no value. In fact, it was creating distraction . . . This sounds so obvious, but it was not obvious to me at the time. And this was a profound insight for me. So I started prioritizing the ideas better, keeping lists of them, and keeping ideas to myself until the organization was ready for the ideas.”
He continues:
“I also started figuring out how to build an organization that can be ready for more ideas. That’s about having the right senior team and leadership and giving those people the executive bandwidth so they could do more ideas per unit of time. And that is what we built. We built a company that’s very good at inventing and doing more than one thing at a time. And as the company gets bigger, you do want to be able to do more than one thing at a time. But that idea of ‘releasing the work’ was very profound for me. It made us operationally more effective while still being inventive.”
Video source: @Reuters (2025)
Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code).
1. Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything e.g. `files-to-prompt . -e ts -e tsx -e css -e md --cxml --ignore node_modules -o prompt.xml`)
2. Describe the next single, concrete incremental change we're trying to implement. Don't ask for code, ask for a few high-level approaches, pros/cons. There's almost always a few ways to do thing and the LLM's judgement is not always great. Optionally make concrete.
3. Pick one approach, ask for first draft code.
4. Review / learning phase: (Manually...) pull up all the API docs in a side browser of functions I haven't called before or I am less familiar with, ask for explanations, clarifications, changes, wind back and try a different approach.
6. Test.
7. Git commit.
Ask for suggestions on what we could implement next. Repeat.
Something like this feels more along the lines of the inner loop of AI-assisted development. The emphasis is on keeping a very tight leash on this new over-eager junior intern savant with encyclopedic knowledge of software, but who also bullshits you all the time, has an over-abundance of courage and shows little to no taste for good code. And emphasis on being slow, defensive, careful, paranoid, and on always taking the inline learning opportunity, not delegating. Many of these stages are clunky and manual and aren't made explicit or super well supported yet in existing tools. We're still very early and so much can still be done on the UI/UX of AI assisted coding.
I expect LLMs will accelerate the natural evolution of software towards higher and higher level DSLs with a narrower scope. But it will still be code because code, unlike natural language, allows us to communicate about and manipulate abstractions without ambiguity.
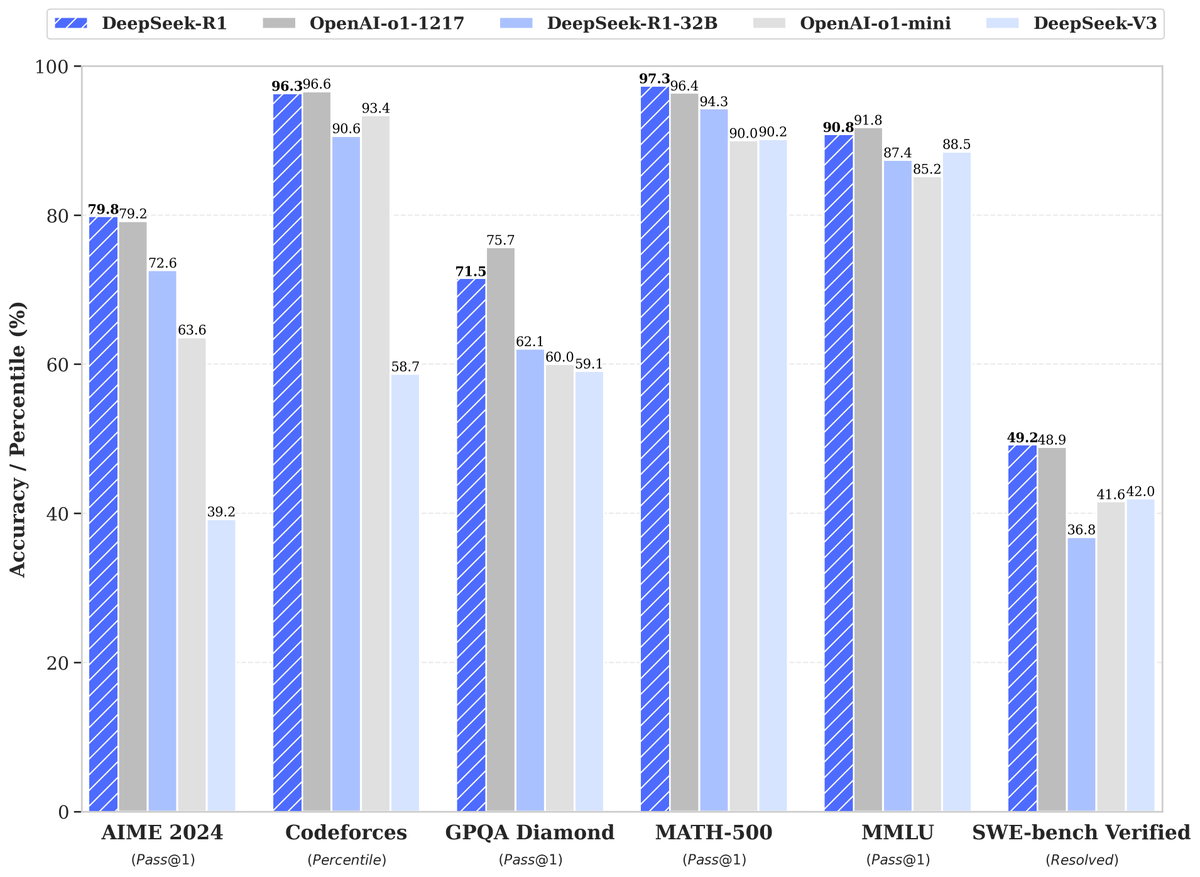
🚀 DeepSeek-R1 is here!
⚡ Performance on par with OpenAI-o1
📖 Fully open-source model & technical report
🏆 MIT licensed: Distill & commercialize freely!
🌐 Website & API are live now! Try DeepThink at https://t.co/v1TFy7LHNy today!
🐋 1/n
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute -- these capabilities are new territory and they demand serious scientific attention.
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Moravec's paradox in LLM evals
I was reacting to this new benchmark of frontier math where LLMs only solve 2%. It was introduced because LLMs are increasingly crushing existing math benchmarks. The interesting issue is that even though by many accounts (/evals), LLMs are inching well into top expert territory (e.g. in math and coding etc.), you wouldn't hire them over a person for the most menial jobs. They can solve complex closed problems if you serve them the problem description neatly on a platter in the prompt, but they struggle to coherently string together long, autonomous, problem-solving sequences in a way that a person would find very easy.
This is Moravec's paradox in disguise, who observed 30+ years ago that what is easy/hard for humans can be non-intuitively very different to what is easy/hard for computers. E.g. humans are very impressed by computers playing chess, but chess is easy for computers as it is a closed, deterministic system with a discrete action space, full observability, etc etc. Vice versa, humans can tie a shoe or fold a shirt and don't think much of it at all but this is an extremely complex sensorimotor task that challenges the state of the art in both hardware and software. It's like that Rubik's Cube release from OpenAI a while back where most people fixated on the solving itself (which is trivial) instead of the actually incredibly difficult task of just turning one face of the cube with a robot hand.
So I really like this FrontierMath benchmark and we should make more. But I also think it's an interesting challenge how we can create evals for all the "easy" stuff that is secretly hard. Very long context windows, coherence, autonomy, common sense, multimodal I/O that works, ... How do we build good "menial job" evals? The kinds of things you'd expect from any entry-level intern on your team.
every time you:
• say a model is "highly accurate" but have no evals
• finetune a decoder LLM for classification without trying BERT-style classifiers
• use only embeddings without trying text for retrieval, matching, dedup
• optimize for sota/complexity instead of solving the user problem
• say that QLoRA speeds up training over LoRA (PSA: it does not)
• run batch inference jobs with model batch size = 1
• write code to run GPU inference via pd.DataFrame.apply()
• allow a codebase to have test coverage = 0.0
• claim that org and biz problems are far easier than tech problems
a cuda error occurs and our ai overlords mark it against you