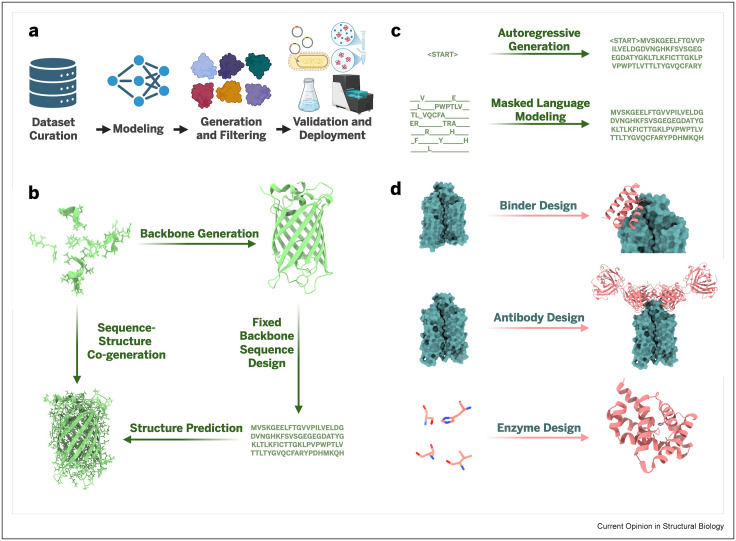
Binder design has come of age thanks to generative models—but how can we access the wider array of dynamic, multistate protein functions, so elegantly employed by nature?
@mihirbafna14 and I are excited to share SwitchCraft, a framework for designing such functions. (1/7)
The @Deliverome has officially lifted off!
I am thrilled that its founders chose IFP’s revitalized Launch Sequence to announce it to the world.
AI is accelerating the design of new disease therapeutics, but we often can’t get those therapies to the cells where they are needed. @BobbyHollings and @beccajcarlson propose to generate the data necessary to overcome this critical bottleneck with the Deliverome Project.
Different tissues have different surface proteins, and different surface proteins have varying abilities to pull therapeutic payloads into their host cell. Though there are more than 2,200 of these proteins, they are largely unexplored, with most drugs targeting only 11 of them. This limited targeting can lead to payloads being delivered to cells where they aren’t needed, resulting in negative side effects.
The Deliverome Project will produce the necessary dataset to solve this problem by measuring which proteins are specific enough to target distinct tissues while also being capable of pulling cargo into the cells. And the data will be released openly in AI-ready formats, creating a public good for the benefit of humanity.
Becca and Bobby are an incredibly smart and dynamic duo, and I am so excited to follow their progress.
https://t.co/j8um8plkKN
Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
I’m looking for a co-founder.
Frontier labs are over-refusing legitimate bio work because they can't tell who's a real researcher and who isn't. I’m solving this with BioTrust — building the credentialing layer between frontier AI labs and researchers. Strong early interest from frontier labs. Backed by funder Sentinel Bio.
I am looking for a builder who's run the trust and security backbone at a company in identity, fintech, compliance, health data, or cybersecurity. Someone with strong instincts on the trust-vs-friction calls. Finisher energy. Deeply motivated by mitigating catastrophic risk from AI and biology.
Full context and how to reach me here: https://t.co/jTeVLHn795
Tag the people you know who'd be unreasonably good at this.
Have you wondered what the wet lab success rates are for current AI-driven protein design models? Look no further!
In our new open access review, @KevinKaichuang, @avapamini, @SarahAlamdari, and I report wet lab success rates for *over 200* different protein design tasks 🧬💻
🧵 We ran the largest head-to-head benchmark of protein binder design methods in the wet lab.
Project page: https://t.co/eSG5qcCPQB
1 million designs. 127 targets. RFdiffusion, BindCraft, BoltzGen, and Proteina-Complexa — all tested side by side.👇
The @NIST Center for AI Standards and Innovation (CAISI) is hiring for AI Evaluations Scientist, Biological AI Models to advance national security-related evaluations of frontier biological AI models in accordance with the AI Action Plan: https://t.co/rkLY0GwFtI
Applicants must submit a resume not to exceed two pages that meets the Basic Requirements, including demonstrating IT-related experience, and all the specialized experience, for the targeted pay band/grade, listed in the posting.
US CAISI is hiring -- the internal govt name is "IT Specialist" but it is effectively a research scientist role!
Salary is $120,579 to - $195,200 per year & you work on AI evaluation within government agencies! Dream job for the right person.
Details: https://t.co/HCZWEgqHex
What should AI evaluators do about models cheating on agent evals? In a new write-up from the U.S. Center for AI Standards and Innovation, we characterize cheating, share examples from our logs, and suggest evaluation practices aimed at reducing cheating's incidence and impact.🧵
Even before @mmitchell_ai recently raised this discussion, I've had conversation after conversation with students & new grads struggling with this exact dilemma.
I want to help! Here's a live thread of AI-related opportunities for those looking to do good & make (enough) money:
1/ OPT OBSERVATORY
I’ve spent the past year creating *the most in-depth public resource* on how the US retains international students after they graduate.
Today, @IFP is releasing never-before-seen data we obtained from ICE via FOIA.
Check it out: https://t.co/La9FD8zN2j
@ArbResearch Too vague to resolve, imo. The cited report seems to use 'impressive' in a few different ways, none of which seem to be demonstrated by these papers. Meanwhile, one could reasonably argue that 'impressive' protein generation capabilities have been around for >20 yrs.