And another open-weight release. Nemotron 3 Ultra has an ultra impressive capability:efficiency ratio!
Design-wise, it carries forward the Mamba-2-attention hybrid stack and LatentMoE introduced in the previous Super variant. But everything is a bit bigger.
In last interview they asked me about
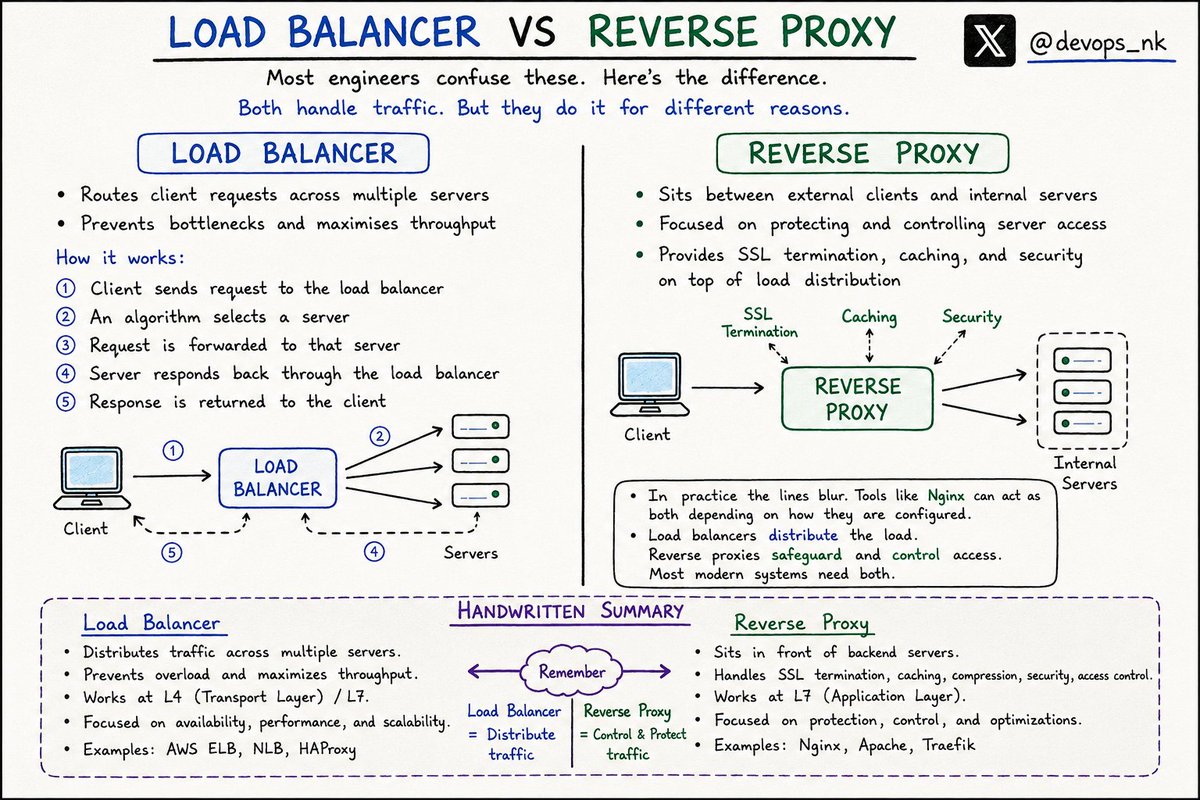
𝗟𝗼𝗮𝗱 𝗕𝗮𝗹𝗮𝗻𝗰𝗲𝗿 vs 𝗥𝗲𝘃𝗲𝗿𝘀𝗲 𝗣𝗿𝗼𝘅𝘆
Let's understand in simple words:
𝗟𝗼𝗮𝗱 𝗕𝗮𝗹𝗮𝗻𝗰𝗲𝗿:
• Distributes traffic across multiple servers
• Prevents overload & improves availability
• Focused on scalability and performance
𝗥𝗲𝘃𝗲𝗿𝘀𝗲 𝗣𝗿𝗼𝘅𝘆:
• Sits between clients and backend servers
• Handles SSL termination, caching, security & access control
• Protects internal infrastructure
In modern systems, tools like Nginx can act as both depending on configuration.
Simple way to remember:
Load Balancer = distribute traffic
Reverse Proxy = control & protect traffic
cant avoid learning MoEs anymore. most of the llm architectures now are MoEs. heres a great article by maarten on mixture of experts with tons of illustration.
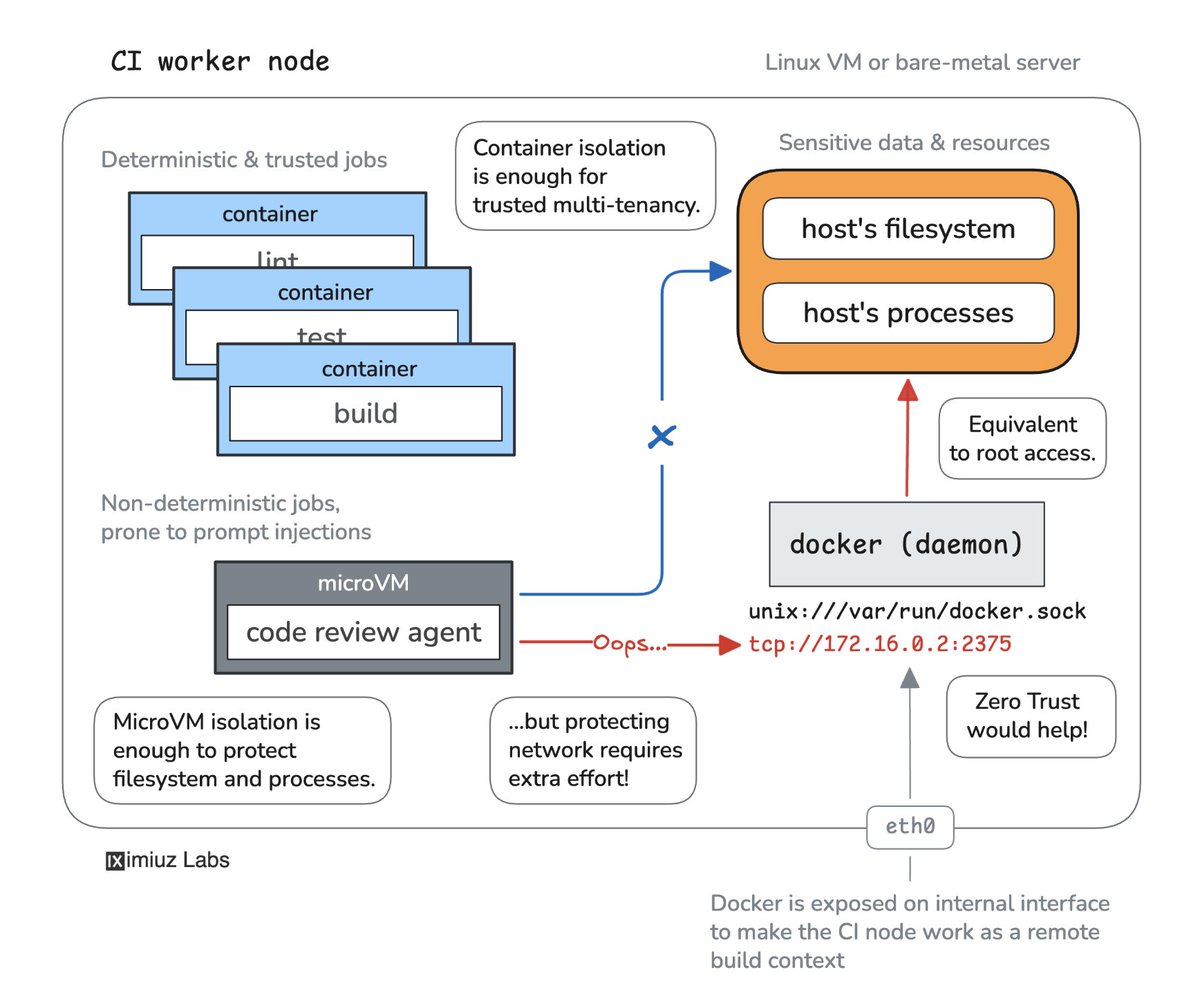
A microVM is not a sandbox. It's an important integral part, but the isolation it provides is not sufficient. Agent confinement is a complex problem that requires a complex solution.
A quick example of how running an agent in a microVM doesn't prevent a breakout: https://t.co/gHPTBCNhP5
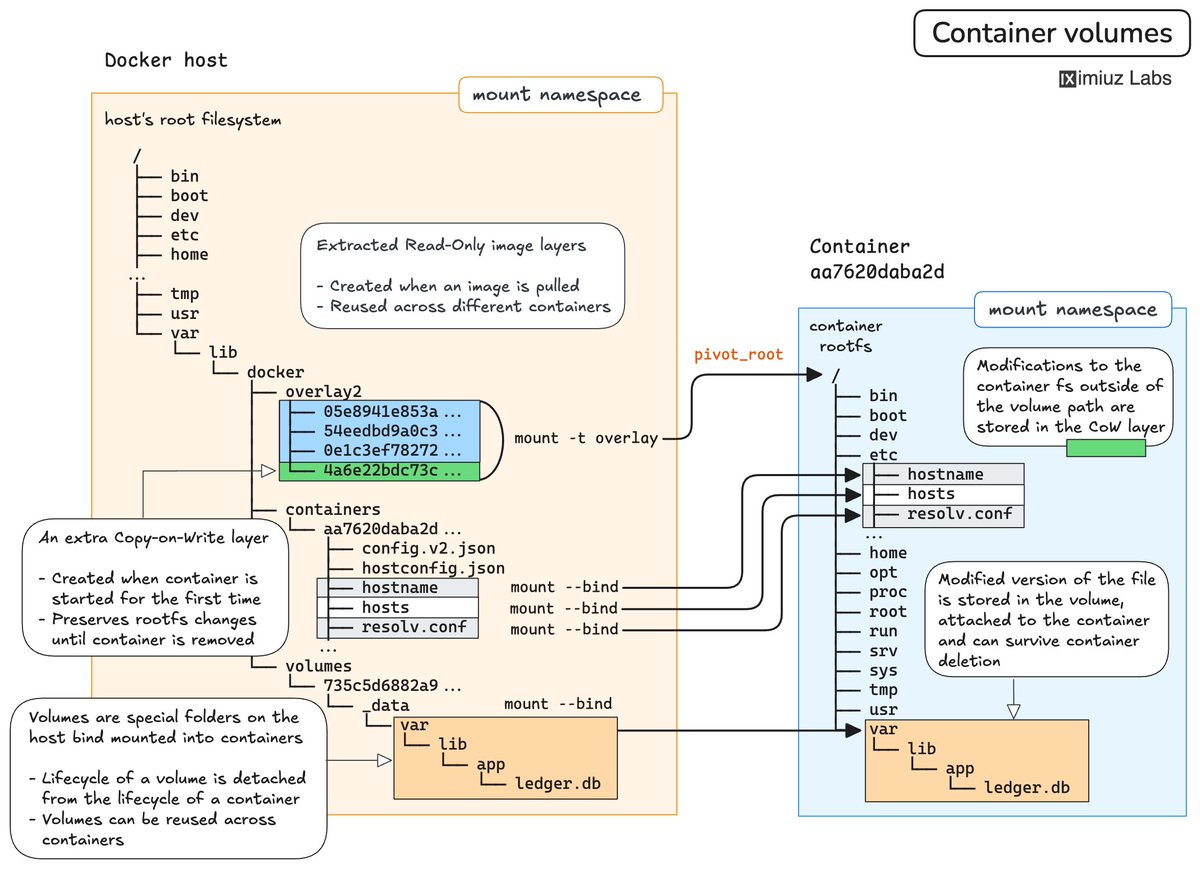
I keep talking about iximiuz Labs' Docker Roadmap, but I just realized the word "roadmap" might be misleading. The actual experience it provides is much closer to that of a self-paced course with a heavy focus on learning by doing.
Yes, scope-wise, this project is a comprehensive learning path that takes you from no Docker knowledge to basic familiarity with the main commands, then to fluency in the key workflows, and, optionally, to full mastery (by covering the "under-the-hood" topics).
However, unlike most roadmaps that I've seen, iximiuz Labs' Docker Roadmap doesn't merely list topics. The roadmap consists of a series of hands-on problems, called Challenges, and "supplementary" deep dives, called Tutorials. All grouped into (larger) modules and (smaller) blocks.
You start at the top, with the most basic Docker tasks like running a container, reading logs, or building an image, and work your way down to more advanced topics like setting up container networking, hardening images for production use, or troubleshooting failing containers.
This way, you learn Docker the only right way - by actually using it, while the roadmap outlines the path and provides hands-on materials to build muscle memory, along with theoretical materials to fill knowledge gaps.
Give it a shot: https://t.co/r6Mjmbc39r
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. Now, we got a technical report with some interesting tidbits. I summarized some of them below:
1. Full attention as an anti-trend?:
They tried hybrid sliding-window attention variants (like so many others, like Xiaomi MiMo, Laguna, Gemma 4, Arcee, Olmo 3, etc.). But even though there were efficiency gains, they said that the production-quality tradeoffs were not worth it for M2.
2. Linear and sparse attention deployment issues:
They found that linear and sparse attention are attractive on paper because they reduce the cost of long-context attention, but they are harder to make work well in a production agent system.
In particular, they found that these efficient attention variants may be more fragile when KV-like state or intermediate memory is stored in lower precision.
Also, they have worse prefix caching support, which matters a lot when using coding agents (which reuse a lot of the context).
3. Fine-grained Mixture-of-Experts (MoEs) are useful:
Finally a recent MoE ablation study! It's only on the 2B-active parameter scale, but hey, better than nothing.
Concretely, they compare a baseline with 32 experts and top-2 routing against a fine-grained setup with 128 experts and top-8 routing.
The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5. That's clearly a win for more fine-grained experts (confirming what the DeepSeek MoE paper reported ~2 years ago).
4. Sophisticated agent pipeline
It's probably no surprise, but this papers confirms that training for agent-like behavior on software engineering task is now a big component of the training pipeline.
They mine GitHub pull requests, builds runnable Docker environments, extracts task-specific test rewards, etc.
5. Interleaved thinking for context management
Interestingly, they found that removing reasoning blocks from previous turns results in worse performance, especially in multi-step agent tasks. (Another point why long-context support is so important these days).
6. Speed rewards
It's common to have token usage penalties, but what's interesting is that the MiniMax team adds a task-completion-time reward that depends on wall-clock time. This is to minimize unnecessary (slow) tool calls. Also, I'm thinking that this would encourage agent parallelization (if supported by the harness)
7. Self-evolution
Looks like self-evolution is also already a big design component of open-weight LLMs. E.g., the paper says that M2.7 already handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.
Linux 101: Mount a Drive and Read Its Contents 🛠️
A CTF-style challenge: discover an unmounted device, mount it, and read the flag file from it. Practicing Linux can be fun!
https://t.co/iHn3t1dbeF
1. Dense Models - Slow and Smart
Example: Qwen3.6-27B / Gemma-4-31B
What it means:
- when a prompt is sent
- it gets tokenised (words are mapped to tokens)
- token generation starts
- the 27B means 27 billion parameters
- each of those parameters will be activated
- 27 billion matrix multiplications
- for every token generated
Active parameter counts are positively correlated with intelligence. That's why Gemma-4-31B is able to compete with Mixture of Experts (MoEs) 10 times their size.
2. Mixture of Expert models - Fast and Efficient
Example: Deepseek-V4-Flash / Qwen3.5-397B
What it means:
- when a prompt is sent it's tokenised
- it's sent to a router
- a router was trained to match prompts with experts
- experts are sub-networks of the model
- when found the experts are activated
- tokens are generated with only a fraction of the params
For example: Deepseek-v4-flash has 284 billion params 11x larger than the dense Qwen3.6-27b.
But only 13B of those 284B will activate per token, which is less than half of the size of Qwen3.6-27B
----
Dense Pros:
- Dense models are easier to train
- They tend to be smaller overall
- They can be very smart per token
Dense Cons:
- Competitive dense models are on average slower than their MoE peers.
- Less parameters to train and specialise.
MoE Pros:
- Can be much larger and be trained longer
- Faster token generation
MoE Cons:
- Larger vram requirements
- Harder to train
--------
Lmk if there's anything i'm wrong with or missing
New article: a visual tour of recent LLM architecture advances, from Gemma 4 to DeepSeek V4.
I focus on long-context efficiency tweaks like KV sharing, per-layer embeddings, layer-wise attention budgets, compressed attention, and mHC.
Link: https://t.co/KO81y3kTH7
To secure Docker, you first need to understand what Docker actually consists of.
A "docker run" may look like a single command, but it kicks off a chain of interactions between the client, the daemon, the host OS, and the lower-level container runtime (runc). Each link in that chain comes with its own trust assumptions and failure modes.
This tutorial by Rory McCune is a practical intro to Docker's moving parts - and to the security risks caused by the lack of awareness: https://t.co/hicMEYNDS8
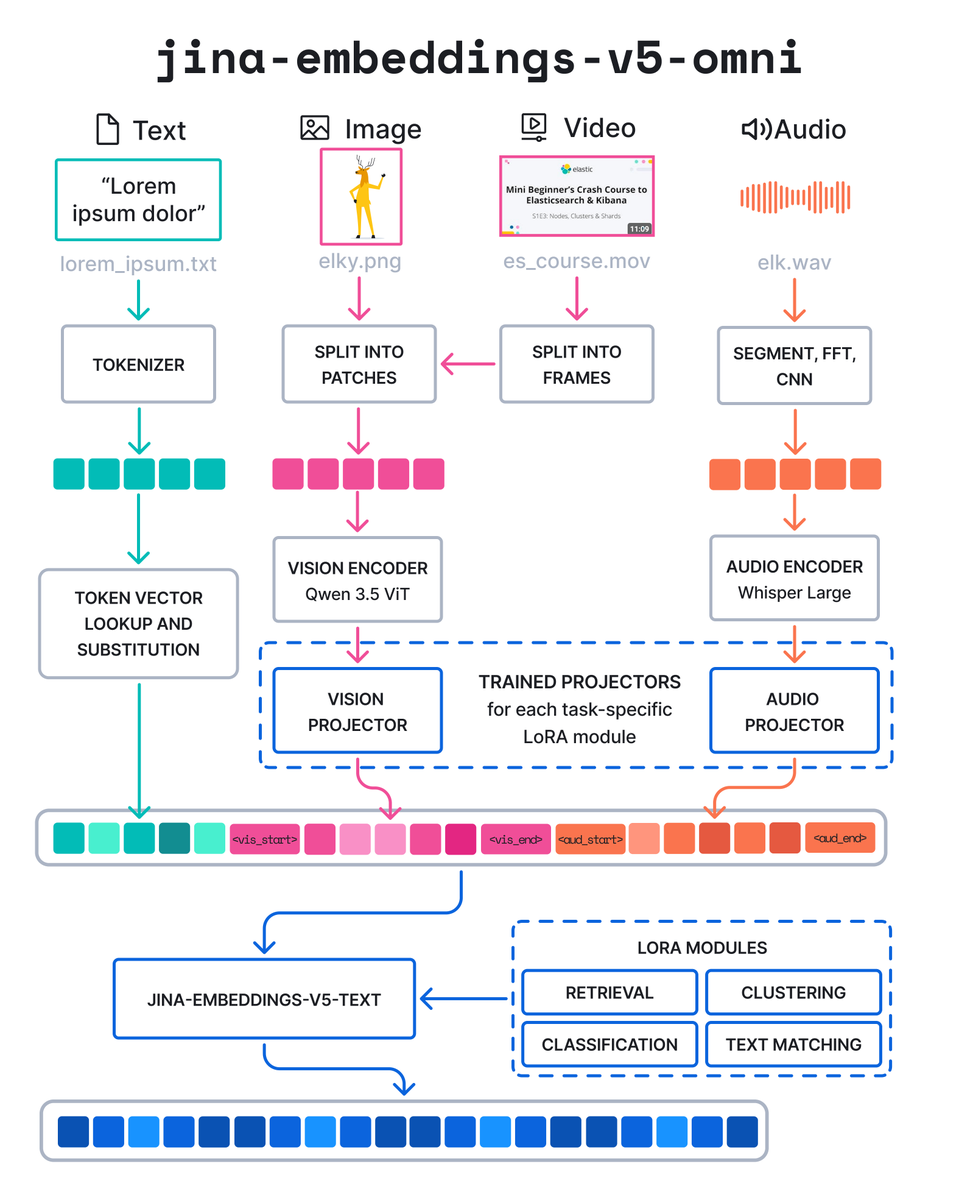
The jina-embeddings-v5-omni family is here!
Multimodal embeddings for text, image, audio, video, and PDF:
• Matryoshka dimensions from 32 to 768 (for nano), and 1024 (for small)
• Supported tasks: retrieval, text matching, clustering, and classification
• nano: 1B parameters, 8K input tokens
• small: 1.7B parameters, 32K input tokens
Available on @elastic inference service (EIS), Jina API, and @huggingface.
Learn more: https://t.co/5ZOmfGFoAe
There are lots of Docker tutorials and courses out there. And ChatGPT and Claude know it well. So what's the point of creating yet another Docker Roadmap?
In my opinion, the important part is the story it tells. The information has always been available - Docker's official docs are solid. But it's not enough for efficient learning. For the best experience, the learning materials should:
- Get the dosage of theory & practice right
- Line up topics into a consistent learning path
- Connect the dots between Docker's functionality and real-world problems
- Keep you in the flow and help preserve the momentum
On top of that, I'm also a strong believer in learning by doing. Tutorial hell is real, but you're not risking getting stuck in it if you start with practice right away and only add the theory when absolutely needed.
Last but not least - quality visual materials. Nobody likes a wall of text, so combining textual explanations with good-looking diagrams makes the overall learning experience so much more pleasant.
This is what I hope differentiates iximiuz Labs' way of learning Docker: https://t.co/mO28eR5xZL
Connection pooling in Postgres.
Postgres uses a process-per-connection model
not thread-per-connection.
That means every connection is expensive :
memory, file descriptors, process overhead.
Now the connection math matters.
A default pool of 100 connections is roughly ~1GB of RAM before queries even run.
4 app servers x 100 connections = 400 connections.
Postgres defaults to max_connections = 100.
Now the database starts refusing connections.
The fix usually isn’t “add more connections.”
It’s a connection pooler.
PgBouncer in transaction mode is the standard answer.
Apps connect to PgBouncer (cheap).
PgBouncer multiplexes them onto a much smaller pool of real Postgres connections (expensive).
1,000 app connections can fan into 20 actual DB connections.
Before reaching for it, read the caveats.
Prepared statements, session-level state, advisory locks.. all behave differently.
If your scaling plan is just increasing max_connections, you probably don’t need a bigger database.
You need PgBouncer.
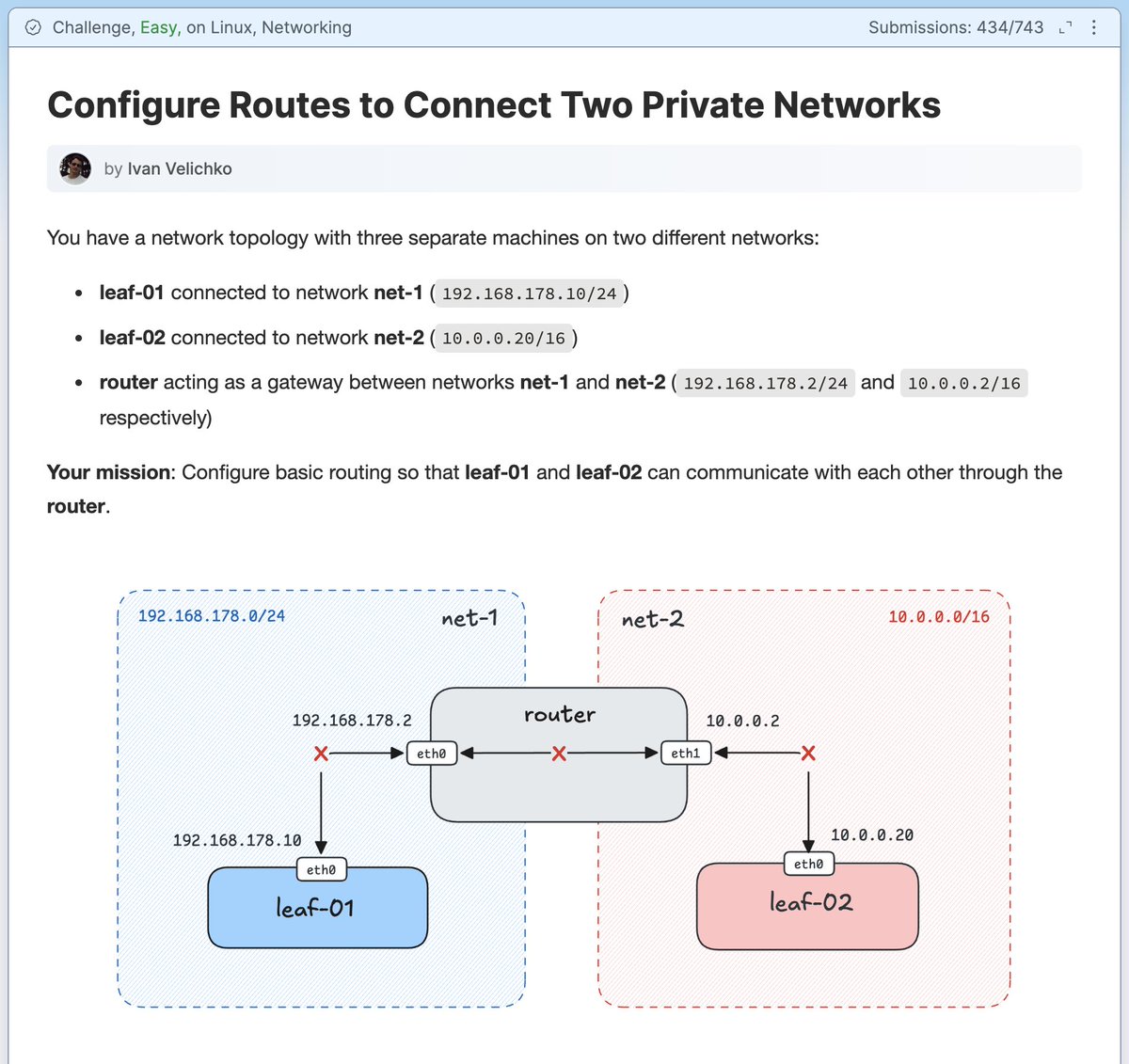
Networking 101: IP and Routing 🛠️
Prepared a hands-on exercise to practice configuring connectivity between two subnets with a shared router node.
Can you solve this problem? https://t.co/k2seN25Ewe
cloud networking in 60 seconds, no fluff:
VPCs are walls. Nothing talks across them by default - you wire it up yourself or it stays silent. Inside, you slice into subnets. "public" vs "private" isn't a checkbox btw, it's literally one route in a route table pointing at the internet gateway. that's the whole trick.
IGW is the front door - traffic both ways. NAT gateway is the side exit: private workloads call out, internet can't call in. one-way mirror basically.
now firewalls - and ppl mess this up constantly. security groups = stateful, wrap the resource, allow out → reply just works. NACLs = stateless, sit at the subnet, you write BOTH directions or you're debugging at 2am. SGs do 95% of the job. NACLs are the bouncer at the door, not your daily driver.
connecting VPCs? peering is fine for 2-3. past that you're building a mesh and N×(N-1)/2 will haunt you. transit gateway = hub, every VPC plugs in once. done.
works the same everywhere - AWS calls it VPC, Azure says VNet + NSG + vWAN, GCP says VPC + firewall rules + Network Connectivity Center. different stickers, same box.
steal this:
https://t.co/V2Z6hHXZLh
Btw, I'm open for b2b remote projects from Armenia. Let's talk
#cloudcomputing #devops #aws #azure #gcp #networking
Just found this awesome free tool for generating Kubernetes diagrams automatically.
KubeDiagrams turns your manifests, Helm charts, and even live clusters into clean architecture diagrams in seconds.
→ Generates diagrams from YAML, Helm, Helmfile, and Kustomize
→ Can visualize live cluster state
→ Supports custom resources
→ Exports to PNG, SVG, PDF, and https://t.co/jwODNqMckk
→ Free and open source
Super useful for docs, onboarding, and understanding cluster architecture fast.
Repo: https://t.co/wk0v5WJUvy
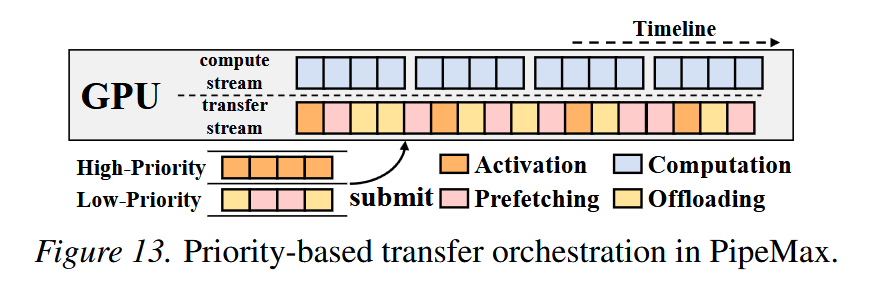
In this paper is proposed PipeMax, a high-throughput LLM inference system that integrates pipeline parallelism with offloading to overcome interconnect and memory constraints on GPU servers.
https://t.co/6xw6J1BMKm