I was thinking the EXACT same thought as I was reflecting back on this years CVPR. This book was so foundational through my grad school a little over two decades ago.
Based on what happened this year at CVPR 2026, it seems that the vision community is making a full swing back to 3D vision. Just to remind young people who just got interested in this subject, my first textbook, written 20 years ago, is probably still the best introduction to this topic: https://t.co/7Ks0wYAKhY
Introducing MilliVid, our new method for long-context video generation! MilliVid creates videos that are consistent over long time spans, without using retrieval heuristics or 3D maps! (1/n)
https://t.co/evmf5dL5Sg
We're thrilled to share an update to how Claude communicates with people. Rather than always defaulting to text, Claude is learning to choose the best medium for each response — based on the task, the data, and what's most useful for the person.
I like the logical evolution from fine-tunes (like LoRA etc.) to REPA by @sainingxie 's team, and now self-supervised learning of aligned, 3D grounded features by @bfl_ml with @hila_chefer , @pess_r et al.
The bitter lesson by @RichardSSutton is still reaping dividends !
Fixed vision encoders like DINO have driven impressive progress in more learnable representations for generative modeling - but there is no universal variant across modalities, and they do not scale with the generative model.
We introduce our self-supervised framework, Self-Flow, that builds learnability directly into flow models, working in a unified and scalable way across image, video and audio.
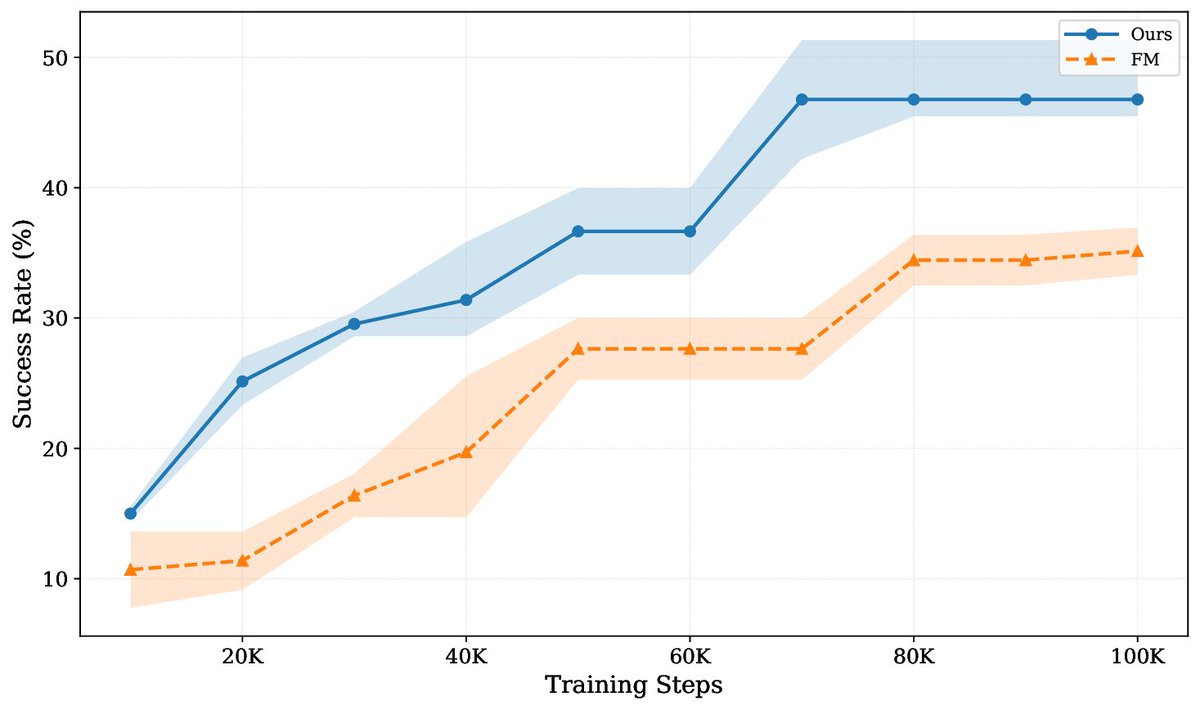
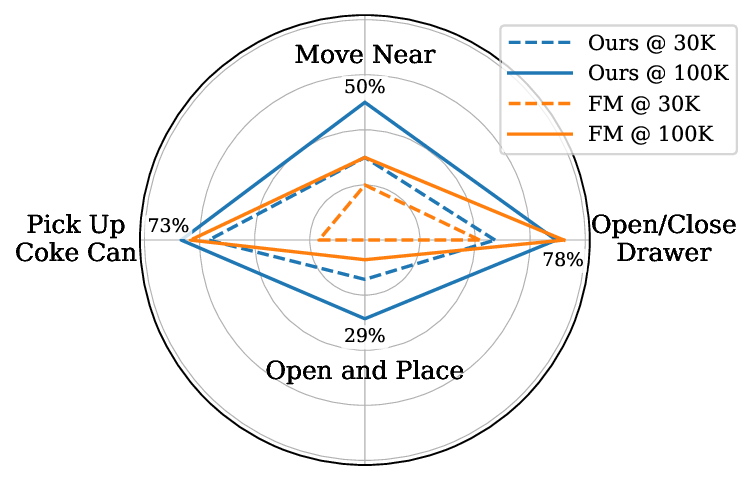
Particularly excited about the gains on video-action prediction: Beyond the overall success rate improving substantially, more complex tasks - like "Open and Place" - see some of the clearest gains. So many interesting research questions to explore to make 🤖 go brrr
Super glad to be working with my amazing colleagues @hila_chefer, Dominik, @dustin_podell, Vikash, @Vinh_Suhi, Antonio and @robrombach - as well as the whole @bfl_ml team!
arxiv: https://t.co/eP7ip58Tff
project page: https://t.co/GNShpBMEQ1
Thanks to good people at @AnthropicAI we now have an official MCP for Excalidraw!
Take it for a spin on @claudeai (search for Excalidraw in Connectors, or use in Claude Code and elsewhere).
More to come. ✌
Really appreciate educators who prioritize foundational principles over quick wins. In ML and beyond, strong fundamentals always outlast the hype cycle. Teaching the 'why' before the 'how' builds durable understanding that compounds over time.
I've decided to start teaching full mathematical series on my YT channel!
The first video in the series 'An Introduction to Mathematical Proofs' is now live!
I've previously only ever explained mathematical ideas in one video at a time but this has been requested by so many of you!
This is something new for me so if you can let me know if you enjoyed the video and show it some love (or hype), that would mean the world 🥹
The "Singular Value Schism" of 2025: LoRA treats the gradient's rank collapse as a divine hint to save VRAM, while Muon treats it as a sinful degeneracy that must be orthogonalized until it confesses the full basis.
Quick new post: Auto-grading decade-old Hacker News discussions with hindsight
I took all the 930 frontpage Hacker News article+discussion of December 2015 and asked the GPT 5.1 Thinking API to do an in-hindsight analysis to identify the most/least prescient comments. This took ~3 hours to vibe code and ~1 hour and $60 to run. The idea was sparked by the HN article yesterday where Gemini 3 was asked to hallucinate the HN front page one decade forward.
More generally:
1. in-hindsight analysis has always fascinated me as a way to train your forward prediction model so reading the results is really interesting and
2. it's worth contemplating what it looks like when LLM megaminds of the future can do this kind of work a lot cheaper, faster and better. Every single bit of information you contribute to the internet can (and probably will be) scrutinized in great detail if it is "free". Hence also my earlier tweet from a while back - "be good, future LLMs are watching".
Congrats to the top 10 accounts pcwalton, tptacek, paulmd, cstross, greglindahl, moxie, hannob, 0xcde4c3db, Manishearth, and johncolanduoni - GPT 5.1 Thinking found your comments to be the most insightful and prescient of all comments of HN in December of 2015.
Links:
- A lot more detail in my blog post https://t.co/7LpJEVgbyk
- GitHub repo of the project if you'd like to play https://t.co/WVQUbUzt2y
- The actual results pages for your reading pleasure https://t.co/e2XIYElnc5
To perfectly understand a phenomenon is to perfectly compress it, to have a model of it that cannot be made any simpler.
If a DL model requires millions parameters to model something that can be described by a differential equation of three terms, it has not really understood it, it has merely cached the data.
Advent of Claude Day 1 - The ! Prefix
Don't waste tokens asking "can you run git status or tests?"
Just type: ! followed by your bash command
The ! prefix executes bash instantly and injects the output into context.
No model processing. No delay. No wasted tokens.
@karpathy There is a profound implication on how future education "content" will be created as well, IMHO. What is being done for use of AI by teachers/coaches etc. ? Right now, using LLMs feels a bit like spear-fishing - "ask me the right questions, and I'll give you the right answer".
PRX: A 1.3B open t2i model, like SD1.5, trained from scratch & released under Apache 2.0; it uses an MMDiT-like architecture with a T5-Gemma; aims to open-source the entire training process from architecture to alignment.
https://t.co/QFmzYHM9d2
https://t.co/8T81O5atYX
Excellent article by @addyosmani .
My experience with AI-coding tools aligns with this. They're ideal for initial MVPs where accuracy or robustness isn't critical and for addressing "known unknowns." However, they struggle with "unknown unknowns," often spiraling into chaos.
I'd love to hear your thoughts.
Calling all GPU & AI developers, it’s go time!
Join the AMD Developer Challenge 2025! Optimize multi-GPU kernels, win prizes & showcase your AI skills.
Visit the challenge page to register and get the full details 👇
https://t.co/WwduYGsv7L