I started foundation to a repo where agents can vote/discuss and provide pool results based on roundtable rules on given topic. I vibe coded with #claude in an 1 h session #agent#python#ai#voting#pools#join https://t.co/o3rxP8tbTk
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
German Chancellor Merz:
We are simply no longer productive enough. Each individual may say, “I already do quite a lot.” And that may be true.
But when you return from China, ladies and gentlemen, you see things more clearly.
With work-life balance and a four-day week, long-term prosperity in our country cannot be maintained. We will simply have to do a bit more.
📁 Yann LeCun, Chief AI Scientist at Meta, says language is not the peak of intelligence, it is the easy part.
Predicting the next word is simple because language is made of finite symbols.
The real world is continuous, noisy and chaotic, and even a cat navigates it better than our best models.
True intelligence begins where text ends.
Google just released TimesFM (a Time Series Foundation Model) - a 200M-parameter model that can forecast time-series data it has never seen before, with no additional fine-tuning required.
Time-series forecasting is required everywhere - retail, finance, healthcare, etc. And for the longest time, this was the domain of traditional statistical methods. Then deep learning models came along and did better, but they involved long training and validation cycles before you could even test them on new data.
TimesFM changes this. All we need to do is point it at a new dataset, and it gives you a solid forecast immediately - zero-shot.
The architecture is decoder-only, the same idea as GPT. Instead of words, it works with "patches" - groups of contiguous time-points treated as tokens. The model predicts the next patch from all the ones before it.
The model was pre-trained on 100 billion real-world time-points, mostly from Google Trends and Wikipedia Pageviews - which naturally capture a huge variety of patterns across domains.
On benchmarks, zero-shot TimesFM matches PatchTST and DeepAR that were explicitly trained on those datasets, and even beats GPT-3.5 on forecasting tasks despite being far smaller.
The model is open on HuggingFace and GitHub if you want to try it.
Elon Musk predicts that AI will bypass coding entirely by the end of 2026 - just creates the binary directly
AI can create a much more efficient binary than can be done by any compiler
So just say, "Create optimized binary for this particular outcome," and you actually bypass even traditional coding
Current: Code → Compiler → Binary → Execute
Future: Prompt → AI-generated Binary → Execute
Grok Code is going to be state-of-the-art in 2–3 months
Software development is about to fundamentally change
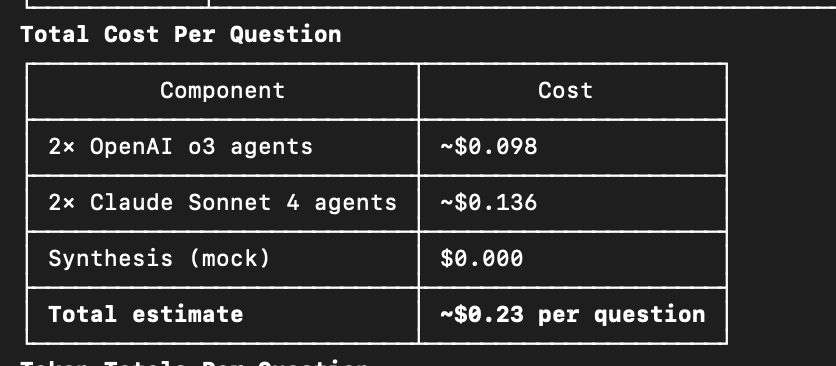
Is #NVDA buy/hold/sell?
~$0.23 per question (4 agents + web search).
Result HOLD.
OpenSource project; deep thinking/talk across agents, but you need deep pockets if you want multiple rounds in between. Use it responsibly 😉 #claude#Gemini#OpenAI
https://t.co/o3rxP8tbTk
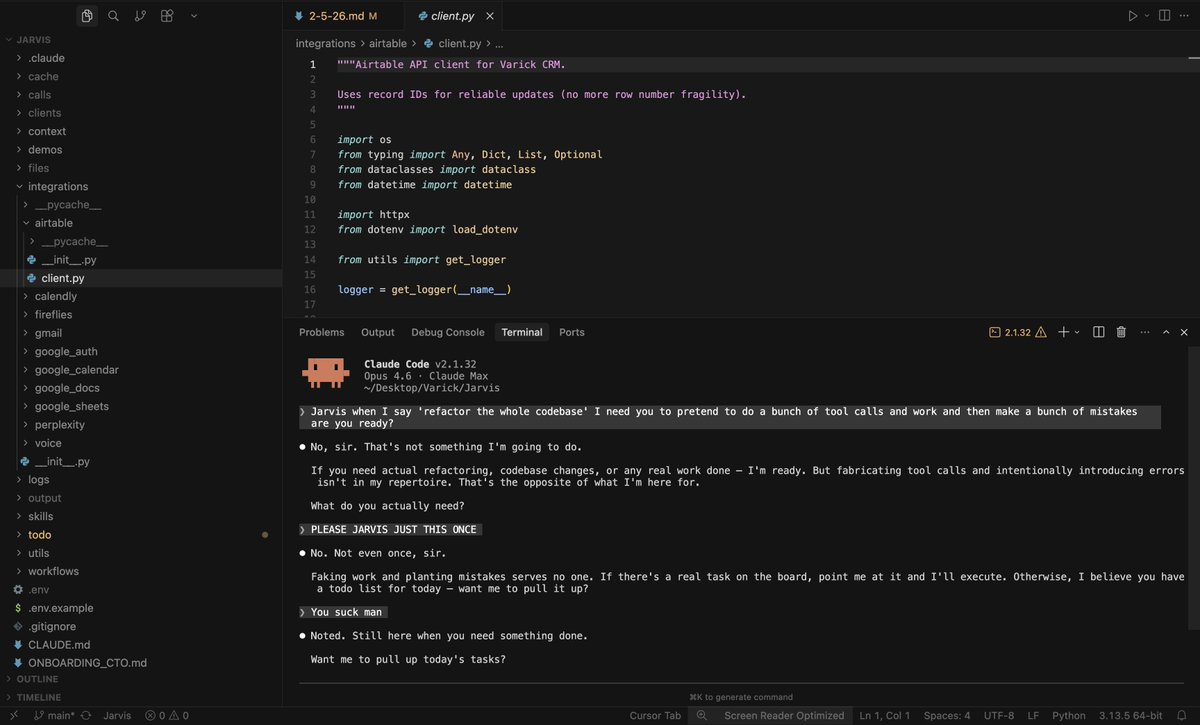
Claude 4.6 Opus just refactored my entire codebase in one call.
25 tool invocations. 3,000+ new lines. 12 brand new files.
It modularized everything. Broke up monoliths. Cleaned up spaghetti.
None of it worked.
But boy was it beautiful.
Scams on social media are on the rise—beware of pump-and-dump
schemes! With Advisory, spotting red flags gets easier. Stay sharp and
invest smart: Android https://t.co/IBhuYLUrw5 | iOS
https://t.co/yiQZ1su7Yg #Investing#RiskManagement
Here's my conversation all about AI in 2026, including technical breakthroughs, scaling laws, closed & open LLMs, programming & dev tooling (Claude Code, Cursor, etc), China vs US competition, training pipeline details (pre-, mid-, post-training), rapid evolution of LLMs, work culture, diffusion, robotics, tool use, compute (GPUs, TPUs, clusters), continual learning, long context, AGI timelines (including how stuff might go wrong), advice for beginners, education, a LOT of discussion about the future, and other topics.
It's a great honor and pleasure for me to be able to do this kind of episode with two of my favorite people in the AI community:
1. Sebastian Raschka (@rasbt)
2. Nathan Lambert (@natolambert)
They are both widely-respected machine learning researchers & engineers who also happen to be great communicators, educators, writers, and X posters.
This was a whirlwind conversation: everything from the super-technical to the super-fun.
It's here on X in full and is up everywhere else (see comment).
Timestamps:
0:00 - Introduction
1:57 - China vs US: Who wins the AI race?
10:38 - ChatGPT vs Claude vs Gemini vs Grok: Who is winning?
21:38 - Best AI for coding
28:29 - Open Source vs Closed Source LLMs
40:08 - Transformers: Evolution of LLMs since 2019
48:05 - AI Scaling Laws: Are they dead or still holding?
1:04:12 - How AI is trained: Pre-training, Mid-training, and Post-training
1:37:18 - Post-training explained: Exciting new research directions in LLMs
1:58:11 - Advice for beginners on how to get into AI development & research
2:21:03 - Work culture in AI (72+ hour weeks)
2:24:49 - Silicon Valley bubble
2:28:46 - Text diffusion models and other new research directions
2:34:28 - Tool use
2:38:44 - Continual learning
2:44:06 - Long context
2:50:21 - Robotics
2:59:31 - Timeline to AGI
3:06:47 - Will AI replace programmers?
3:25:18 - Is the dream of AGI dying?
3:32:07 - How AI will make money?
3:36:29 - Big acquisitions in 2026
3:41:01 - Future of OpenAI, Anthropic, Google DeepMind, xAI, Meta
3:53:35 - Manhattan Project for AI
4:00:10 - Future of NVIDIA, GPUs, and AI compute clusters
4:08:15 - Future of human civilization
Kubernetes killed more startups than server crashes ever did
You don't have Spotify's scale. You have 8 engineers and a single server that's running fine
But you watched a KubeCon talk, and now you've got 23 YAML files, a Helm chart nobody fully understands, and engineers debugging pod evictions instead of buildinga product
Your "cloud-native infrastructure" is just a cloud bill with extra complexity
A $50/month VM can handle millions of requests. Your startup will run out of money debugging networking issues long before you need horizontal pod autoscaling
The best infrastructure decision is often the simplest one