we’re hiring. founding ai & hardware engineers, surgical partners.
if you’re looking for hard problems and wonderful purpose, join us 🚀
https://t.co/sXVrkZtnwB
КОЛИЧЕСТВЕННАЯ ЭКОНОМИКА
Рекомендую, совсем коротко, "Количественную экономику" Джесси Шапиро (https://t.co/yGXnEe8eCD). Любому преподавателю микроэкономики - однозначно нужно. Студентам, которые хотят заниматься микро, будет очень полезно. Тем, кто микроэкономику не слушал, нужно прочитать любой стандартный учебник (например, Гулсби-Сайверсон-Лист или Асемоглу-Лейбсон).
Она такая необычная - я очень удивился, когда её прочитал. В ней очень подробно разбираются пять конкретных ситуаций, самых стандартных из учебника микроэкономики, но упор делается не на теорию, а на понимание того, что можно извлечь из данных. Я это объясняю на своих лекциях по микро - у нас на рисунке есть кривые спроса и предложения, но в данных-то мы видим не кривые, а точки. Какие кривые можно восстановить по точкам? Какие показатели выпуска можно восстановить, если мы знаем часть кривых?
Этот подход к анализу поведения фирм и потребителей в 1950-е развивал Яков Маршак [студентом слушавший лекции Слуцкого в дорево��юционном Киеве]. В Чикаго эту традицию потом наследовал Гэри Бэккер. Джесси Шапиро - один из крупнейших экономистов нашего времени, один из создателей целой отрасли в экономической науке - экономики средств массовой информации. Здорово, что он нашёл время написать такой учебник.
I’m an AI researcher turned brain tumor patient, and recently I used the models to crack my mystery fatigue faster than my PCP could.
I believe everyone can do the same with their own symptoms. Here’s how:
AMD ACABA DE MATAR LAS SUSCRIPCIONES DE IA
La CEO de AMD Lisa Su presento oficialmente una PC del tamaño de una lonchera y ejecuto en vivo un modelo de 235 mil millones de parametros
Sin centro de datos. Sin nube. Sin GPU alquiladas
El chip en su interior es el AMD Ryzen AI Max+ 395
Es el primer chip x86 en el que la CPU y la GPU comparten el mismo bloque de memoria
Hasta 128 GB de memoria unificada
Una RTX 5090 te ofrece 32 GB de memoria de video
Una 4090 te da 24 GB
Pero esta pequeña maquina te ofrece mas de tres veces la memoria de cualquiera de ellas
Y cabe en una mochila
En inferencia con DeepSeek R1 le gano a una RTX 5080 por 3x
Una desktop del tamaño de un libro grueso superando una tarjeta grafica de mas de mil dolares en una carga de trabajo real de IA
Ahora haz las cuentas de tus suscripciones
Claude Code Max: $200 al mes
ChatGPT Pro: $200
Cursor: $20
Gemini: $20
Son $5,280 al año antes de construir una sola cosa
La version de 128GB de esta maquina cuesta entre $1,800 y $2,500
A ese ritmo se paga sola en menos de un año
Y despues corre sin costes adicionales, GRATIS
> Instalas Ollama
> Bajas Qwen3 235B
> Apuntas Claude Code a localhost
> La misma interfaz que ya usas
> Nada sale de tu maquina
> Nada cuesta por request
> Sin limitaciones a las 3am cuando por fin tienes tiempo para construir
Los abogados dejan de preocuparse por lo que OpenAI hace con sus archivos
Los developers dejan de ver el contador de tokens
Los founders dejan de matar prototipos porque la factura de la nube los asusta
La IA local ya no es solo una opcion mas economica
Es la unica IA que nadie puede quitarte
Y la pregunta ya no es si la IA local es lo suficientemente buena
Esta claro que si lo es
La verdadera pregunta es por que seguir pagando suscripciones cada mes cuando puedes correrla tu mismo
Elon Musk explains his 5-step algorithm for solving any problem:
"The most common mistake of smart engineers is to optimize a thing that should not exist."
"I have this very basic first principles algorithm that I run as a mantra."
Elon breaks it down:
Step 1: Question the requirements.
"Make the requirements less dumb. The requirements are always dumb to some degree, no matter how smart the person who gave you those requirements. You have to start there, because otherwise you could get the perfect answer to the wrong question."
Step 2: Try to delete it.
"Try to delete the part or the process step entirely. If you're not forced to put back at least 10% of what you delete, you're not deleting enough. Most people feel like they've succeeded if they haven't been forced to put things back in. But actually they haven't, they've been overly conservative and left things in that shouldn't be there."
Step 3: Optimize or simplify.
"The most common mistake of smart engineers is to optimize a thing that should not exist. So you don't optimize until after you've tried to delete."
Step 4: Speed it up.
"Any given thing can be done faster than you think. But you shouldn't speed things up until you've tried to delete it and optimize it otherwise, you're speeding up something that shouldn't exist."
Step 5: Automate.
"And then the fifth thing is to automate it."
Elon explains why the order matters:
"I've gone backwards so many times where I've automated something, sped it up, simplified it, and then deleted it. I got tired of doing that. So that's why I have this mantra."
There's a new generation of filmmakers earning a good living with low-cost, highly-targeted content on free streaming services like Tubi and Roku. I profiled an incredibly interesting guy whose work is making $2M per year with zero help from Hollywood.
https://t.co/9lnrvJkk78
People replace their phones every ~4 yrs. This means there are hundreds of millions of old phones discarded each year that are still perfectly usable as computing devices. @Google in collabration with @UCSD is exploring how to turn these old phones into cloud-computing “phone clusters”. Putting phones back in service in this way can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction, and taking advantage of the embodied carbon already incurred from manufacturing these devices, and modern phones actually are already quite powerful computers. Read more in the blog below ⬇️
🚨 New opportunity for recent grads: Anthropic is hiring 1,000 fellows (paid, full time) to help nonprofits apply AI to their work.
Applications close July 17th: https://t.co/7HdEKtV35H
Qualia has been selected for the @GoogleDeepMind Robotics Program.
We train embodied models that put a robot on a real manual task and make it work, on the floor, not in a demo.
Foundation models and reasoning are where robotics is heading, and doing that work alongside DeepMind, who are pushing this frontier, is exactly where we want to be.
If you are a company looking to see how a new generation of robots can help your manual tasks, contact us at [email protected]
More soon
If you've adopted AI at your company but haven't seen any tangible results, read this 1990 article: "The Dynamo and the Computer" by Paul David.
When electricity first arrived, factories that "adopted" it barely got faster. They just swapped the steam engine for an electric one and ran everything else exactly as before: same machine layout, same workflow, same management. Electricity in, no real gains out.
The most common mistake with any new technology is to drop it into the old organization and then declare the transformation done.
The real leap came decades later, when each machine got its own small motor. Suddenly machines no longer had to be lined up around one central drive shaft. They could be rearranged around the actual flow of work.
The productivity gains didn't come from electricity. They came from REDESIGNING THE ENTIRE FACTORY around it.
AI is the same. Bolting it onto your existing process gets you a faster steam engine. The payoff comes when you redesign the work itself.
(link to paper in comments)
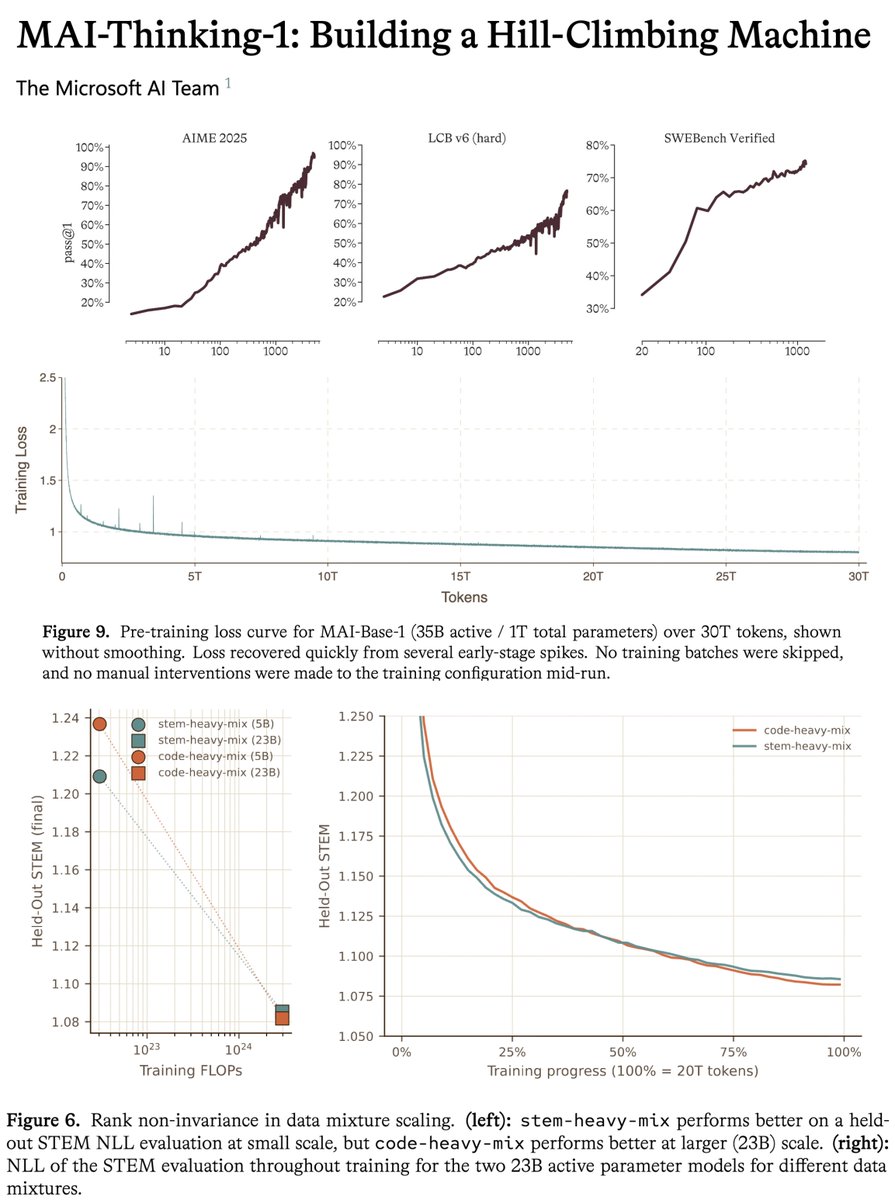
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
*UBER SETS $1,500 MONTHLY CAP ON SOME AI CODING TOOLS FOR STAFF
$UBER officially reeling in the Claude budget after blowing their AI budget earlier this year.
Undoubtedly more companies to follow
Swiggy is in damage-control mode after shareholders rejected its proposal to give more board seats to the founders and management team last week.
The company said in an exchange filing last night that the proposed changes were not about “concentration of power”, but part of an effort to make Swiggy an Indian-owned and controlled entity (IOCC).
Swiggy added that board rights are not in perpetuity and were approved by its independent directors.
Co-founder and Group CEO Sriharsha Majety admitted in an interview with The Economic Times that the company could have “handled this better through engagement” and “communicated more effectively”.
Majety has also said he wants to put the proposal to a vote again and believes it will eventually pass.
Let’s understand Swiggy’s board structure right now.
- Sriharsha Majety is currently the only management representative on the board after co-founder Nandan Reddy stepped down earlier this year.
- Amsterdam-listed Prosus, which owns over 21% in Swiggy, now has two representatives on the board - India head Ashutosh Sharma and Renan Pinto (who joined last week).
- The board also has four independent directors, including chairman Anand Kripalu.
However, independent directors, even if they are Indian residents, are not counted toward Indian control norms.
This meant Swiggy needed at least three management representatives on the board to outweigh the two directors representing foreign investor Prosus.
Proxy advisory firms argued that board representation should be linked to shareholding. Majety and co-founder Phani Kishan Addepalli together own less than 5% of Swiggy.
Failure to become an Indian-controlled entity could delay Swiggy Instamart’s shift from a marketplace structure to an owned-inventory model similar to Blinkit.
The owned-inventory model has given market leader Blinkit several advantages.
By owning inventory directly, Blinkit captures the full retail spread, improving gross margins already by 3% and is expected to improve net margin by 1%.
Owning the goods also allows Blinkit to book the full value of sold items as revenue instead of earning only a marketplace commission.
It will be interesting to see how this impacts Swiggy’s profitability and break-even ambitions from now on.
All the best startup accelerators to apply in 2026 (below FULL spreadsheet):
[ Top-Tier ]
1. Y Combinator (~$500k, 7% on $125k + uncapped SAFE)
2. a16z Speedrun (~$500k for 10% + $500k follow-on)
3. Techstars (~$220k, bumped from $120k in fall 2025)
4. Founders Inc (~$100-250k for 4-7%)
5. Sequoia Arc (~$1M, terms per company)
6. South Park Commons (~$1M total, $400k for 7% + $600k guaranteed)
7. HF0 (up to $1M uncapped for 5%, repeat founders only)
8. On Deck ODX (DISCONTINUED 2022, skip)
9. Pear VC PearX (~$250k-2M for ~10%)
10. 500 Global Flagship (~$150k for 6%)
[ AI / ML Specific ]
11. AI Grant (~$250k for 7%, Nat Friedman + Daniel Gross)
12. AI Fund (~$1M+, Andrew Ng, studio model)
13. NVIDIA Inception (credits + perks, no equity)
14. Microsoft for Startups (up to $150k Azure credits, no equity)
15. Google for Startups AI Accelerator (credits, no equity)
[ Vertical / Deep Tech ]
16. SOSV (~$525k across IndieBio, HAX, Orbit)
17. IndieBio (biotech, ~$525k = $250k for 6-8% + Genesis SAFE)
18. HAX (hardware, ~$525k via SOSV)
19. Greentown Labs (cleantech, workspace + grants)
20. Activate (deep science fellowship, 2-yr stipend)
[ Crypto / Web3 ]
21. a16z crypto CSX (~$500k for 7%, SF in-person)
22. Alliance (~$500k, ALL18 starts Sept 7)
23. Outlier Ventures Base Camp (~$250k, per-chain verticals)
24. Coinbase Base Builder (varies, mostly non-dilutive)
[ International / Regional ]
25. Seedcamp (~€350k-1M first check, rolling, Europe)
26. Entrepreneur First (~$250k = $125k for 8% + uncapped MFN)
27. Antler Disrupt US (~$400k = $250k for ~9% + uncapped)
28. Brinc (~$100k, Asia + Middle East)
29. Station F (Paris campus, hosted-program terms)
30. Founder Institute ($499-999 fee + 2.5% Equity Collective warrant)
[ Pre-Seed / Idea Stage / Niche ]
31. Z Fellows (~$10k for 1%, pre-product)
32. ERA NYC (~$100k for 8%, generalist)
33. The Residency (community-first, no standard check)
34. Plug and Play (varies, often non-dilutive)
35. Build For Tomorrow (community + grants)
Four things worth knowing:
1. small program acceptance rates are higher than YC, not because they're easier, because the funnel is smaller. apply to 5-7, not 1
2. brand premium on YC is real but not infinite. Arc + Speedrun + HF0 carry signal too
3. "$X for Y%" is the only number that matters. uncapped MFNs are not free money, they dilute you on the next round
4. avoid any list still quoting Techstars at $120k, ODX as active, HF0 at $100k, or Founder Institute as "$10k for 4%". all wrong
Shared with you those where I am going to apply with my ideas and products
Terms shift annually. Verify on each program's site before applying
gl with successful raising
Another exclusive today.
AI-focussed fund, Activate has picked up a stake in ElevenLabs valued at $11 billion.
@aakrit spoke to us about the partnership… @puranchdET@ETtech
Come work with me!
A really cool job just opened up on our international investigations team at The New York Times for a reporter specializing in OSINT, with lots of room for different skillsets
https://t.co/gx8ZamNlMc
The history of mankind is written within you. If you learn how to read the 'Book of Mankind' in your own heart, you stop depending on others to tell you how to live. True guidance isn't found in a person or a practice—it’s found in self-understanding. #JidduKrishnamurti


![k_sonin's tweet photo. КОЛИЧЕСТВЕННАЯ ЭКОНОМИКА
Рекомендую, совсем коротко, "Количественную экономику" Джесси Шапиро (https://t.co/yGXnEe8eCD). Любому преподавателю микроэкономики - однозначно нужно. Студентам, которые хотят заниматься микро, будет очень полезно. Тем, кто микроэкономику не слушал, нужно прочитать любой стандартный учебник (например, Гулсби-Сайверсон-Лист или Асемоглу-Лейбсон).
Она такая необычная - я очень удивился, когда её прочитал. В ней очень подробно разбираются пять конкретных ситуаций, самых стандартных из учебника микроэкономики, но упор делается не на теорию, а на понимание того, что можно извлечь из данных. Я это объясняю на своих лекциях по микро - у нас на рисунке есть кривые спроса и предложения, но в данных-то мы видим не кривые, а точки. Какие кривые можно восстановить по точкам? Какие показатели выпуска можно восстановить, если мы знаем часть кривых?
Этот подход к анализу поведения фирм и потребителей в 1950-е развивал Яков Маршак [студентом слушавший лекции Слуцкого в дорево��юционном Киеве]. В Чикаго эту традицию потом наследовал Гэри Бэккер. Джесси Шапиро - один из крупнейших экономистов нашего времени, один из создателей целой отрасли в экономической науке - экономики средств массовой информации. Здорово, что он нашёл время написать такой учебник.](https://pbs.twimg.com/media/HK84FI1XwAIKSfJ.jpg)






















![k_sonin's tweet photo. КОЛИЧЕСТВЕННАЯ ЭКОНОМИКА
Рекомендую, совсем коротко, "Количественную экономику" Джесси Шапиро (https://t.co/yGXnEe8eCD). Любому преподавателю микроэкономики - однозначно нужно. Студентам, которые хотят заниматься микро, будет очень полезно. Тем, кто микроэкономику не слушал, нужно прочитать любой стандартный учебник (например, Гулсби-Сайверсон-Лист или Асемоглу-Лейбсон).
Она такая необычная - я очень удивился, когда её прочитал. В ней очень подробно разбираются пять конкретных ситуаций, самых стандартных из учебника микроэкономики, но упор делается не на теорию, а на понимание того, что можно извлечь из данных. Я это объясняю на своих лекциях по микро - у нас на рисунке есть кривые спроса и предложения, но в данных-то мы видим не кривые, а точки. Какие кривые можно восстановить по точкам? Какие показатели выпуска можно восстановить, если мы знаем часть кривых?
Этот подход к анализу поведения фирм и потребителей в 1950-е развивал Яков Маршак [студентом слушавший лекции Слуцкого в дорево��юционном Киеве]. В Чикаго эту традицию потом наследовал Гэри Бэккер. Джесси Шапиро - один из крупнейших экономистов нашего времени, один из создателей целой отрасли в экономической науке - экономики средств массовой информации. Здорово, что он нашёл время написать такой учебник.](https://pbs.twimg.com/media/HK84hTcW8AE6Ncu.jpg)







![DeRonin_'s tweet photo. All the best startup accelerators to apply in 2026 (below FULL spreadsheet):
[ Top-Tier ]
1. Y Combinator (~$500k, 7% on $125k + uncapped SAFE)
2. a16z Speedrun (~$500k for 10% + $500k follow-on)
3. Techstars (~$220k, bumped from $120k in fall 2025)
4. Founders Inc (~$100-250k for 4-7%)
5. Sequoia Arc (~$1M, terms per company)
6. South Park Commons (~$1M total, $400k for 7% + $600k guaranteed)
7. HF0 (up to $1M uncapped for 5%, repeat founders only)
8. On Deck ODX (DISCONTINUED 2022, skip)
9. Pear VC PearX (~$250k-2M for ~10%)
10. 500 Global Flagship (~$150k for 6%)
[ AI / ML Specific ]
11. AI Grant (~$250k for 7%, Nat Friedman + Daniel Gross)
12. AI Fund (~$1M+, Andrew Ng, studio model)
13. NVIDIA Inception (credits + perks, no equity)
14. Microsoft for Startups (up to $150k Azure credits, no equity)
15. Google for Startups AI Accelerator (credits, no equity)
[ Vertical / Deep Tech ]
16. SOSV (~$525k across IndieBio, HAX, Orbit)
17. IndieBio (biotech, ~$525k = $250k for 6-8% + Genesis SAFE)
18. HAX (hardware, ~$525k via SOSV)
19. Greentown Labs (cleantech, workspace + grants)
20. Activate (deep science fellowship, 2-yr stipend)
[ Crypto / Web3 ]
21. a16z crypto CSX (~$500k for 7%, SF in-person)
22. Alliance (~$500k, ALL18 starts Sept 7)
23. Outlier Ventures Base Camp (~$250k, per-chain verticals)
24. Coinbase Base Builder (varies, mostly non-dilutive)
[ International / Regional ]
25. Seedcamp (~€350k-1M first check, rolling, Europe)
26. Entrepreneur First (~$250k = $125k for 8% + uncapped MFN)
27. Antler Disrupt US (~$400k = $250k for ~9% + uncapped)
28. Brinc (~$100k, Asia + Middle East)
29. Station F (Paris campus, hosted-program terms)
30. Founder Institute ($499-999 fee + 2.5% Equity Collective warrant)
[ Pre-Seed / Idea Stage / Niche ]
31. Z Fellows (~$10k for 1%, pre-product)
32. ERA NYC (~$100k for 8%, generalist)
33. The Residency (community-first, no standard check)
34. Plug and Play (varies, often non-dilutive)
35. Build For Tomorrow (community + grants)
Four things worth knowing:
1. small program acceptance rates are higher than YC, not because they're easier, because the funnel is smaller. apply to 5-7, not 1
2. brand premium on YC is real but not infinite. Arc + Speedrun + HF0 carry signal too
3. "$X for Y%" is the only number that matters. uncapped MFNs are not free money, they dilute you on the next round
4. avoid any list still quoting Techstars at $120k, ODX as active, HF0 at $100k, or Founder Institute as "$10k for 4%". all wrong
Shared with you those where I am going to apply with my ideas and products
Terms shift annually. Verify on each program's site before applying
gl with successful raising](https://pbs.twimg.com/media/HIcF86_XkAArXYe.jpg)






























