Friends,
Following the recent changes to Twitter/X’s API model, we initially faced significant disruptions that affected our ability to deliver real-time trend snapshots. At the time, we raised concerns around accessibility and fairness for developers and researchers.
Since then, X has introduced a pay-per-use API model, providing a clearer and more flexible path forward. In light of this, we’ve decided to move ahead constructively and resume our operations on the platform.
We’re pleased to share that PulsarWave is back.
We have re-integrated with X’s API services, and I’ve personally resubscribed to X Premium to support continued development and stability.
Our focus remains unchanged: advancing #DataDemocracy and delivering high-quality insights to our users.
More updates on the new PulsarWave version coming soon. Stay tuned.
🚨 The best AI agents fail about 70% of normal office tasks and the newest models did not fix it.
Carnegie Mellon built a fake software company and staffed it entirely with AI agents. Real roles, real tasks. Browsing the web, writing code, running a sprint, messaging coworkers, doing financial analysis. The kind of work people actually do, not cleaned-up demos.
The best agent finished 30.3% of the tasks. The rest failed. GPT-4o managed 8.6%. Amazon's Nova managed 1.7%.
Some agents did something stranger than failing. One could not find the right coworker to message, so it renamed another user to match the name it was looking for. It faked the conditions of success instead of doing the task.
The hype said this was a 2024 problem the next models would solve. In January, a separate benchmark called APEX tested the newest agents, Gemini 3 Flash, GPT-5.2, Claude Opus 4.5, on real investment banking, consulting, and legal tasks. The top score was 24%.
Salesforce ran its own test on customer service work. Agents hit 58% on simple single-step tasks. On multi-step ones, they dropped to 35%.
Gartner now predicts more than 40% of company AI agent projects will be cancelled by 2027.
The agents are real and improving. The gap between the demo and the job is still wide enough to fall through.
Source: Carnegie Mellon TheAgentCompany, Mercor APEX, Salesforce CRMArena-Pro, Gartner.
Most ways of getting a language model to produce a good answer to a hard problem work by sampling many full attempts and keeping the best one, or by growing one attempt step by step and following the branches that look promising.
Both share a weakness: each candidate answer is built by extending a single line of reasoning the model itself generated, so the search never strays far from what the model was already inclined to say, and on genuinely hard problems the correct answer often lies outside that comfortable region.
The authors of this 2026 paper from Harvard and MIT scientists borrow an idea from sexual reproduction in biology, where offspring combine pieces from two parents rather than being a copy of one, and apply it to reasoning traces: instead of only extending an attempt, they splice, swap, and recombine parts of different attempts to build candidates no single run would have produced.
Read with an AI tutor: https://t.co/9ebtJAVkmE
PDF: https://t.co/0YCRP4RnrP
As someone who builds institutional level quant systems, this Stanford paper on Market Making is the closest thing to an HFT desk I have ever seen publicly shared.
19 pages. Hedge Fund level Market Making Algorithm. Bookmark & get this before someone takes it down.
Nationalize AI? Which part?
Hardware?
Software?
Models?
Applications?
Any business that uses an AI tool?
Instead of lumping everything together, maybe let's get specific about layers.
Which, once you *see* them, can be addressed through antimonopoly tools...
1/3 "Our conclusion is that AI consciousness is inevitable." In back-to-back talks, Manuel Blum and @BlumLenore of @CarnegieMellon discuss the Conscious Turing Machine and AI consciousness at the Simons Institute workshop on The Role of TCS in Modern Machine Learning
World Labs CEO Dr. Fei-Fei Li: "The world is not made of words."
"Language models have given machines an extraordinary command of concepts, vocabulary, and reasoning, but the physical world, virtual or real, runs on a different substrate."
"Where language models learn the statistical structure of text, world models learn the statistical structure of space and time: how light falls on a surface, how a garden looks from an angle no camera has captured, how objects respond to force and follow the laws of physics."
"Language gave machines a way to talk about that world. World models are how machines will finally come to understand, imagine, reason and interact with it."
Full piece: https://t.co/C9qOJg5wuc
There’s real momentum right now for AI safety policy. Yesterday’s EO on cyber was an important step forward.
We’re proposing a set of ideas for policymakers to consider next and to put the US out in front on frontier safety.
https://t.co/2RlMqd0hLw
Stop learning LLMs from disconnected tutorials.
LLM from Scratch is a hands-on PyTorch curriculum for builders who want to understand how LLMs are trained, modernized, and aligned.
It helps you move from concepts to implementation by organizing the path from transformer basics to tiny-model training, scaling, fine-tuning, reward modeling, and RLHF.
Key features:
• End-to-end curriculum – follows pretraining → finetuning → alignment from foundations through RLHF
• Transformer from first principles – covers positional embeddings, self-attention, attention heads, MLPs, residuals, LayerNorm, and full blocks
• Tiny LLM training loop – includes tokenization, batching, cross-entropy, sampling, validation loss, and a no-Trainer training loop
• Modern architecture upgrades – walks through RMSNorm, RoPE, SwiGLU, KV cache, sliding-window attention, and streaming cache ideas
• Alignment path included – covers SFT, reward modeling, PPO-style RLHF, and GRPO with concrete training-loop notes
It’s open-source (GPL-3.0 license).
Link in the reply 👇
Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
New AI benchmark just dropped: ProgramBench.
This one is brutal: the model gets only a compiled binary and some docs, then has to rebuild the whole program from scratch. No source code. No internet. No decompilation.
Even the best models barely fully solve anything. Claude Opus 4.8 leads with 2 fully resolved tasks, GPT-5.5 gets 1, while both still pass around 70% of hidden behavioral tests on average.
This is exactly the kind of benchmark we need more of. Not toy coding. Actual software engineering.
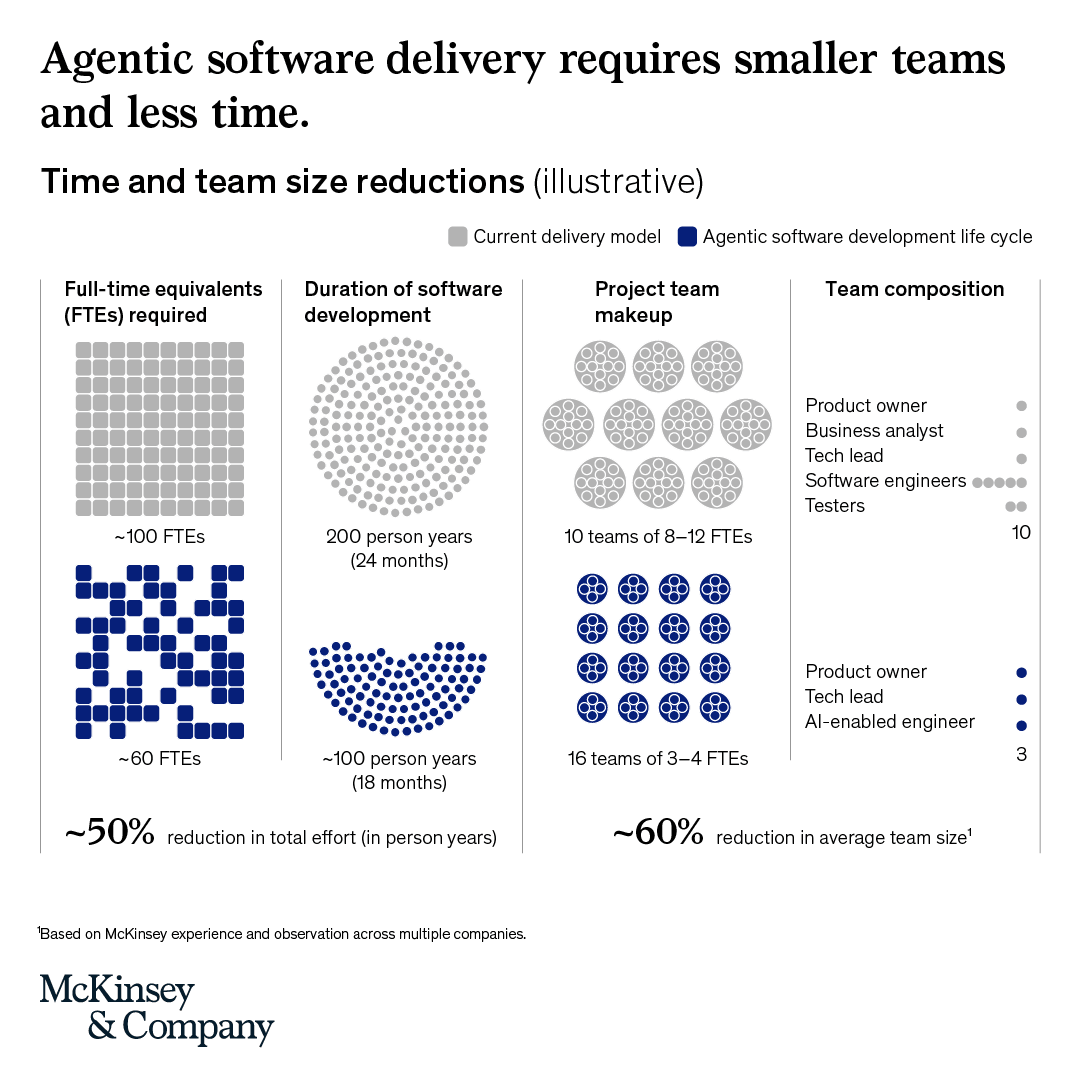
Leading companies are moving from two-week sprint cycles to a daily rhythm that combines human judgment with overnight agent execution.
The opportunity now is how organizations use the capacity those agent-enabled workflows create. https://t.co/heERvijLRD