@ivanfioravanti@danieltvela this command works for spec decoding but running it I get 2x lower t/s than when just running the big model alone 🤔 llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q8_0 -hfd ggml-org/gemma-4-E2B-it-GGUF:Q8_0 --no-mmproj
Meet @svegas18, @AustinBaggio , @christinetyip from autoresearch@home:
> Wednesday, they release the most comprehensive autoresearch repo & leaderboard
> Same day, we plan and launch an autoresearch hack
> Thursday, they decide to fly y from Canada & NYC to present their work
@edouard_iosdev@levelsio I've traveled to the US with it many times. I was only stopped once for a check. They took a sample, ran a test, and let me go within a few minutes.
We vibe-coded https://t.co/3dM07J4YC7 to test different OCR models. Between DeepSeek OCR 2, GLM OCR, and LightOnOCR-2, we are getting the most consistent results from DeepSeek. Its bounding box placement is also quite good.
@clattner_llvm@AnthropicAI Cool article! I'm curious, though, why is this the most interesting lesson if it’s exactly what you’d expect from an LLM? You even mention that in the next paragraph! 🙂
fully local Wispr alternative app running Qwen3 ASR 0.6B via mlx-audio-swift. practically instantaneous result in any active input field. @Prince_Canuma
fully local Wispr alternative app running Qwen3 ASR 0.6B via mlx-audio-swift. practically instantaneous result in any active input field. @Prince_Canuma
@Prince_Canuma running the same image on their demo app provides a good output. although it takes quite long to get the result, but that might be due to some free demo constraints.
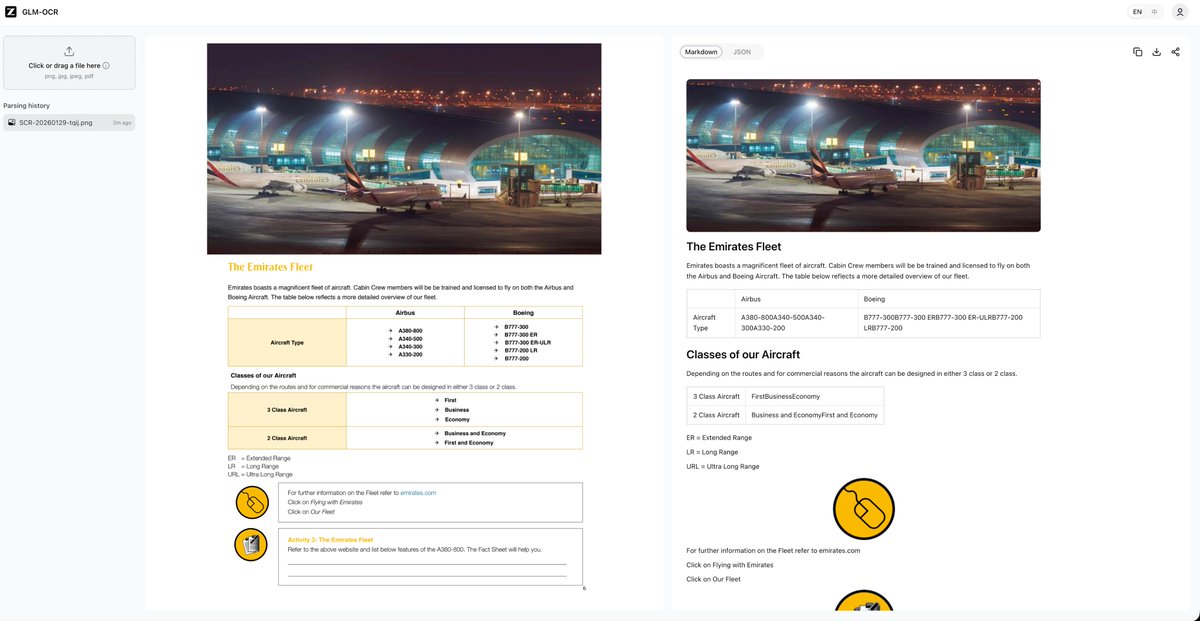
@Prince_Canuma for example, I was not able to make it recognize all the text in this image, regardless of the mode I used. meanwhile, DS does it with ease.
@Prince_Canuma did some tests with it. running on mbp m4 max 128. definitely faster than DeepSeek OCR2. however, it's significantly worse than DS on complex documents.