"Eighties tech sticks to the skin, responds to the touch: the personal computer, the Sony Walkman, the portable telephone, the soft contact lens." - Bruce Sterling
I got a real transformer language model running locally on a stock Game Boy Color (thanks Codex)!
No phone, PC, Wi-Fi, link cable, or cloud inference.
• The cartridge boots a ROM, and the GBC runs the model itself.
• The model is @karpathy’s TinyStories-260K, converted to INT8 weights with fixed-point math so it can run without floating point.
• Built with GBDK-2020 as an MBC5 Game Boy ROM.
• The model weights live in bank-switched cartridge ROM. Prompt entry happens on-device with the D-pad/buttons and an on-screen keyboard.
• The prompt is tokenized on the Game Boy, then the ROM runs transformer prefill + autoregressive generation. The KV cache is stored in cartridge SRAM, because the GBC’s work RAM is tiny.
It is extremely slow, and the output is gibberish because the math is heavily quantized/approximated, but the core thing works!
Hardware: stock Game Boy Color + EZ Flash Junior + microSD. No soldering, no internal mods.
We started by investigating why Claude chose to blackmail. We believe the original source of the behavior was internet text that portrays AI as evil and interested in self-preservation.
Our post-training at the time wasn’t making it worse—but it also wasn’t making it better.
Meta illegaly downloaded 80+ terabytes of books from LibGen, Anna's Archive, and Z-library to train their AI models.
Aaron Swartz downloaded 70 GBs of articles from JSTOR (0.0875% of Meta) in 2010. Faced $1 million in fine and 35 years in jail. Took his own life in 2013.
It’s Friday late at night. I walked with her online 30 years ago in a multi-user dungeon role-play game.
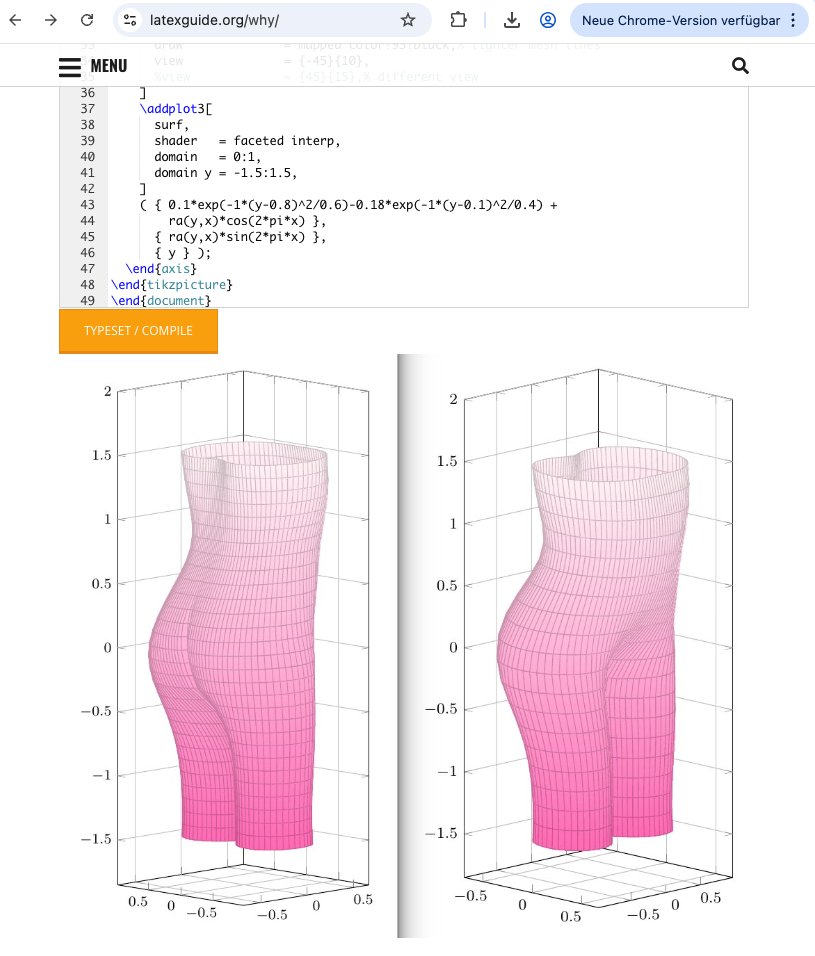
Met her in a café in Hamburg 20 years ago. I had too much wine tonight. Should I call her? Text her? I’m plotting functions in TikZ to distract myself.
if you're running Qwen 3.5 on any coding agent (OpenCode, Claude Code) you will hit a jinja template crash. the model rejects the developer role that every modern agent sends.
people asked for the full template. here it is. two paths depending on which model you're running:
path 1: patch base Qwen's template.
add developer role handling + keep thinking mode alive.
full command:
llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 --chat-template-file qwen3.5_chat_template.jinja
template file: https://t.co/U3Lxydk8kg
without the patched template, --chat-template chatml silently kills thinking. server shows thinking = 0.
no reasoning. no think blocks. check your logs.
path 2: run Qwopus instead.
Qwen3.5-27B with Claude Opus 4.6 reasoning distilled in. the jinja bug doesn't exist on this model. thinking mode works natively. no patched template needed. same speed, same VRAM, better autonomous behavior on coding agents.
weights: https://t.co/Rf9MyTWfzn
both fit on a single RTX 3090. 16.5 GB. 29-35 tok/s. 262K context.
ADHD multitaskers absolutely printing rn
> talk to agent 1
> while you wait for it to respond, talk to agent 2
> while you wait for agent 2 to respond, back to agent 1. if still spinning, talk to agent 3...