Advice for AI engineers 💡
Stop building LangGraph pipelines.
Modern LLMs are so good at tool calling that your hand-crafted orchestration is actually hurting performance.
Let the model decide.
I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit.
My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently.
So, here goes.
How to be a Principal Engineer/Senior Principal Engineer/Senior Architect/fancy-sounding-title Engineer, a thread:
1. You're evaluated on how much more the company succeeds because you're there, not the lines of code you wrote. If you can unblock someone, do that. If you need to kill a two year project that's not going anywhere, do that. Do what is right, not what makes you look good.
always funny when engineers size each other up
met a guy who had worked for NASA
me "I designed the S3 filesystem"
him "I designed the Mars rover filesystem"
… aight you cool …
@davidrobertson@svpino Agree. I’m no expert, but the pdf pages to png approach has worked for me since gpt4o was released. Passing Base64 png image encoding to got4o to return JSON key values. Managed to replace expensive enterprise OCR services. Will keep you posted if quality drops..so far so good.
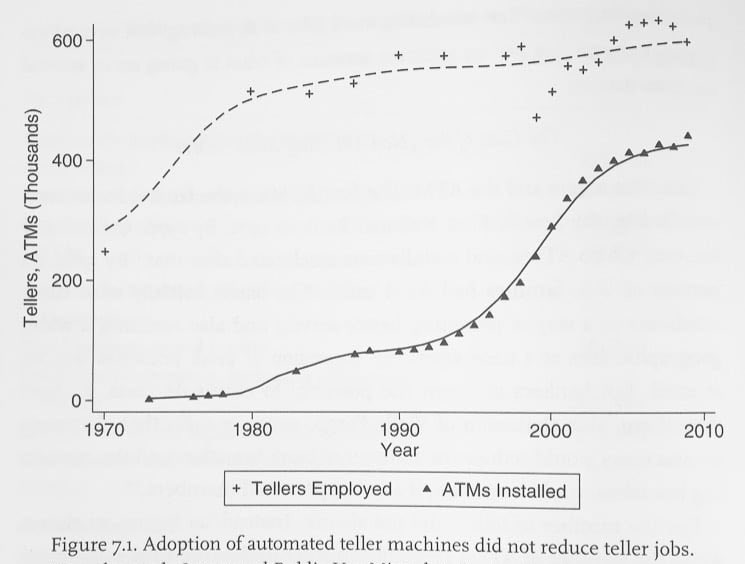
Bank teller employment continuing to grow during the rise of ATMs is a perfect example of how automation lowers the cost of delivering a particular task, letting you serve more customers, and thus growing the category. We are going to see this over and over again with AI.
One skill for the top 1%:
Building real-time data pipelines and stream processing.
Everywhere I go, companies need to process data as fast as they produce it. It's hard to find people who know how to do this well, but companies are willing to pay exceptionally well for this.
Apache Kafka and Flink are the industry standards streaming platforms for high-performance data pipelines. Unfortunately, most streaming libraries are Java-based and offer a Python wrapper.
If you are a Python developer, here is an open-source alternative:
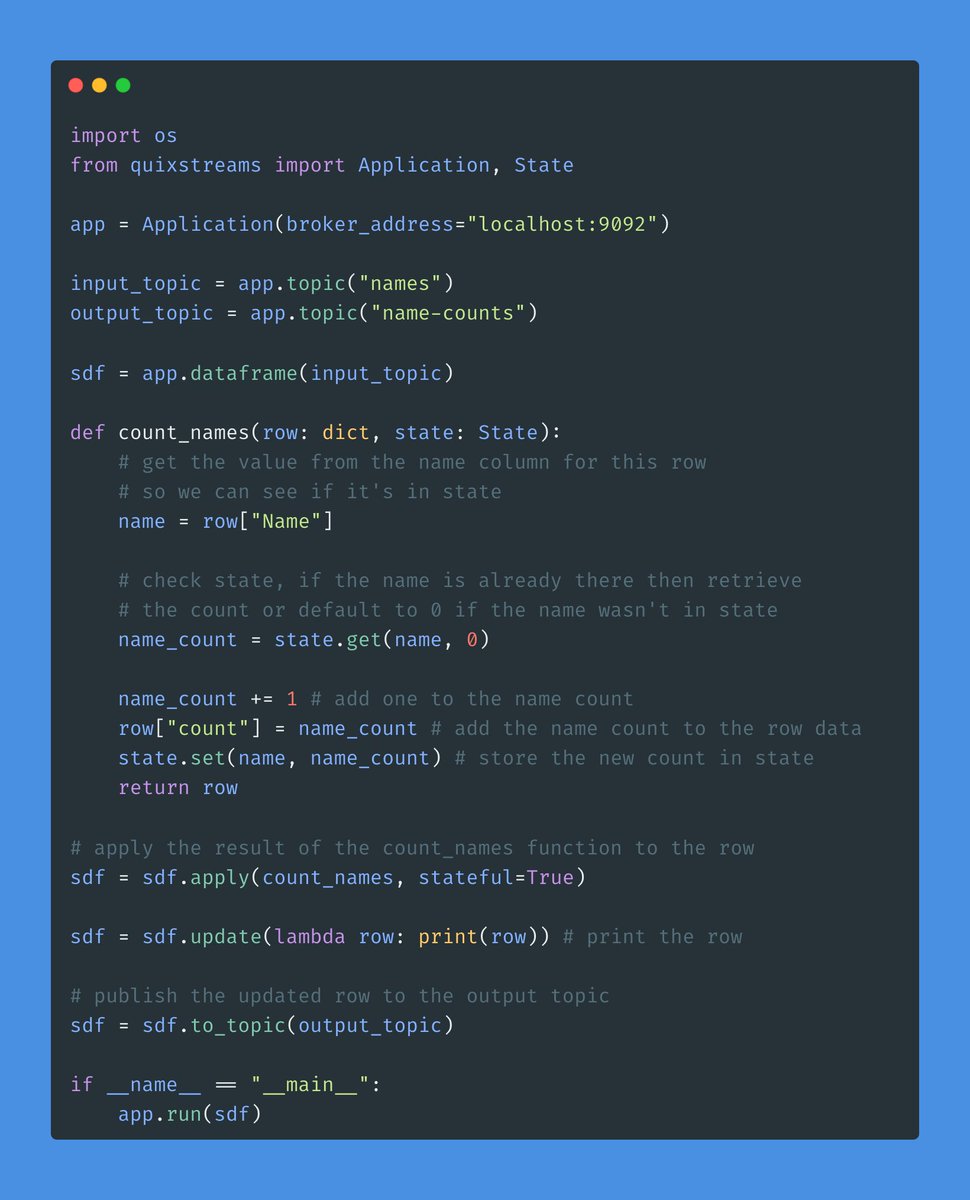
Quix Streams is a library that works with Kafka using pure Python. It's lightweight and has a beautiful and straightforward interface. Here's their GitHub repository:
https://t.co/Og1YvJGOQZ
You can use Quix to build stream processing pipelines in pure Python, including feature engineering, pre-computations, inference, and real-time machine learning.
The attached sample shows a simple aggregation and will give you a taste of what it’s like to build with Quix.
Thanks to the Quix team for collaborating with me on this post.
Thank you to everyone who brought this article to our attention. We agree that customers should not have to pay for unauthorized requests that they did not initiate. We’ll have more to share on exactly how we’ll help prevent these charges shortly.
#AWS#S3
How an empty S3 bucket can make your AWS bill explode - https://t.co/KRgL9C1u9p
After 8 months of planning, 12 hours of filming, and 2 weeks of editing, my biggest project has been released.
The Modern Full-Stack React Tutorial is now live, FOR FREE, on my YouTube channel
PROMPTS ARE TINY PROGRAMS
We’re now about 18 months into the AI revolution. One thing that was uncertain in late 2022 was whether prompt engineering would be around to stay, or whether better AI would quickly obviate it.
I now think it’s around to stay and I have an explanation that makes sense to me, at least: prompt engineering is just a subset of software engineering.
That is, prompts are tiny programs written in natural language. But the API isn’t specified and varies between models. So guessing the right “function calls” with clever use of vocabulary is a huge part of the game. On the other hand, even if you don’t guess *exactly* the right words to use, the model will often do what you mean.
This is different from how we normally think of an API, which is both more legible and more fragile. The exact words to make an API do what you want are written down, but if you don’t say those exact words it won’t do what you want.
Even given this difference, the concept of prompts as tiny programs using hidden APIs helps explain the bizarre magic associated with specific phrases. I’m reminded of Quake3’s fast inverse square root[1,2], which has a famously obscure incantation in C that just so happened to deliver a 4X speedup.
More code now looks like that, and it makes sense. C is how you talk to machines and English is how you talk to humans. So, just like you write part of a large application in C for performance, you’ll also write part of it in English for dealing with unstructured data.
You can go further with this analogy. Once you think of prompts as code, you can probably generate model-aware syntax highlighters for favored keywords. You can maybe automatically generate API-like docs from a model for the most common use cases.
And you can think of every new model you add to your codebase as roughly analogous to adding a new programming language — because just as it takes time for someone to ramp up on the idioms of Rust, they’ll need to play around with the latest Mistral to get the hang of how to talk to it.
Anyway — this is all probably obvious to folks spending 100% of their time in the field, and is similar to some of the things @karpathy has posted about, but at least for me it was a useful articulation of why prompts are around to stay: prompts are tiny programs.
[1]: https://t.co/3Ryz3N69hY
[2]: https://t.co/qK2C7IU2g1






















![balajis's tweet photo. PROMPTS ARE TINY PROGRAMS
We’re now about 18 months into the AI revolution. One thing that was uncertain in late 2022 was whether prompt engineering would be around to stay, or whether better AI would quickly obviate it.
I now think it’s around to stay and I have an explanation that makes sense to me, at least: prompt engineering is just a subset of software engineering.
That is, prompts are tiny programs written in natural language. But the API isn’t specified and varies between models. So guessing the right “function calls” with clever use of vocabulary is a huge part of the game. On the other hand, even if you don’t guess *exactly* the right words to use, the model will often do what you mean.
This is different from how we normally think of an API, which is both more legible and more fragile. The exact words to make an API do what you want are written down, but if you don’t say those exact words it won’t do what you want.
Even given this difference, the concept of prompts as tiny programs using hidden APIs helps explain the bizarre magic associated with specific phrases. I’m reminded of Quake3’s fast inverse square root[1,2], which has a famously obscure incantation in C that just so happened to deliver a 4X speedup.
More code now looks like that, and it makes sense. C is how you talk to machines and English is how you talk to humans. So, just like you write part of a large application in C for performance, you’ll also write part of it in English for dealing with unstructured data.
You can go further with this analogy. Once you think of prompts as code, you can probably generate model-aware syntax highlighters for favored keywords. You can maybe automatically generate API-like docs from a model for the most common use cases.
And you can think of every new model you add to your codebase as roughly analogous to adding a new programming language — because just as it takes time for someone to ramp up on the idioms of Rust, they’ll need to play around with the latest Mistral to get the hang of how to talk to it.
Anyway — this is all probably obvious to folks spending 100% of their time in the field, and is similar to some of the things @karpathy has posted about, but at least for me it was a useful articulation of why prompts are around to stay: prompts are tiny programs.
[1]: https://t.co/3Ryz3N69hY
[2]: https://t.co/qK2C7IU2g1](https://pbs.twimg.com/media/GEmOOThaAAE2HXY.jpg)





























