@AnthropicAI Well you were probably going to nerf it in a week or so due to high demand. But I must admit it was quite good experience while I was working with it for the last few days.
@deedydas Did you try the same tasks with GPT 5.5 or any other model using a proper loop + context? None of these tasks sound impressive in 2026 ifmyou have a good harness and workflow tbh.
Hey @OpenAI all codex cli and codex app returns the same error response (with 5.5 model only)
{ "type": "error", "error": { "type": "image_generation_user_error", "code": "invalid_value", "message": "The model 'gpt-image-2' does not exist.", "param": "tools" }, "status": 400 }
@zan2434@ashpreetbedi@eddiejiao_obj@drewocarr the query was “cats”. failed to build full version and draft version was pretty.. drafty. good concept but it needs a lot of work to be usable
@LLMJunky@bensig Even if MemPalace itself stays local, once you connect it to a commercial model through MCP, retrieved snippets can be sent to that provider as part of prompts or tool-augmented context.
Claude Code leaked their source map, effectively giving you a look into the codebase.
I immediately went for the one thing that mattered: spinner verbs
There are 187
please shut the fuck up i don't even care about the specific thing you're saying i'm just so tired of hearing predictions one after the other telling me what the future is going to be like just please shut the fuck up
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
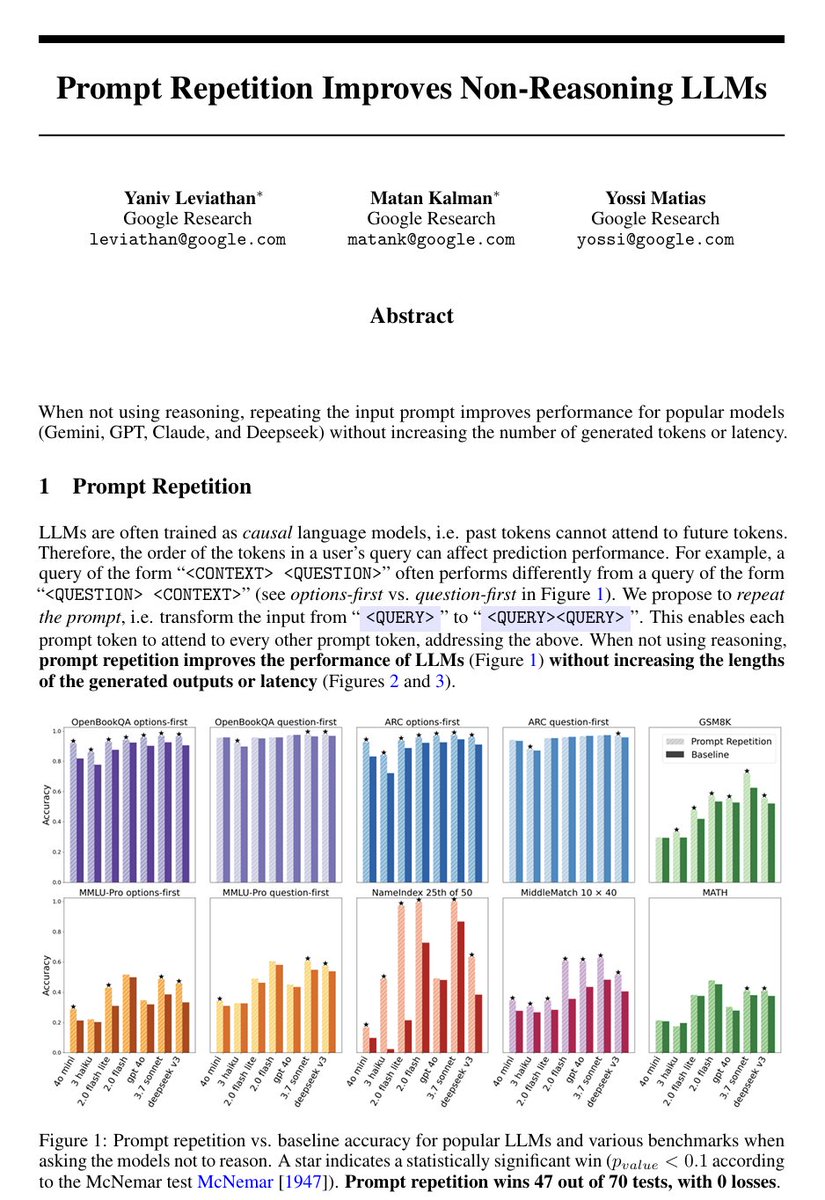
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: https://t.co/MipHHO6rjX
Get the PDF: https://t.co/XQrqiaGwIO