@murchandamus@davidgshort Haha, the rule is beautifully simple for all of us:
When I was less traveled, I’d count whatever I could get away with.
Now that I’ve got a decent number on the resume, I’d like to be a little finicky
‘Claude, make my product LLM-optimized’ prompt was gloriously worthless
AI search doesn’t reward optimization. It rewards the things people already know and trust.
just build something worth mentioning!
In the last 6 months at @Ahrefs, we analyzed over 1 billion data points across 14 studies. Here's what we learned about AI search optimization:
1) "Best X" blog listicles are the single most prominent content format cited by AI chatbots. They make up 43.8% of all page types cited by ChatGPT specifically.
2) 67% of ChatGPT's top 1,000 citations come from sources marketers can't influence: Wikipedia (29.7%), homepages (23.8%), app stores (6.6%). Only 32.3% are influenceable content like educational pages, reviews, news, and blog posts.
3) 28.3% of ChatGPT's most-cited pages have zero Google organic visibility. These pages get cited repeatedly by ChatGPT despite not ranking in Google at all. A completely separate discovery layer.
4) ChatGPT only cites about 50% of the URLs it retrieves. It fetches dozens of pages per query but uses half as background context without attribution. This means that being retrieved and being cited are very different things.
5) Adding schema markup had zero meaningful impact on AI citations. AI Overviews actually dipped −4.6%, while AI Mode (+2.4%) and ChatGPT (+2.2%) showed changes indistinguishable from zero.
6) YouTube mentions have the highest correlation (0.737) with AI brand visibility out of all the factors we studied (including all the conventional SEO metrics like backlinks, page count, DR, etc). This held true for both Google-owned and OpenAI products.
7) AI Overviews reduce clicks to the #1 result by 58%. That’s up from 34.5% just 10 months earlier. The trend is accelerating.
8) 99.9% of AI Overviews appear on informational intent queries. Transactional, navigational, and local searches are almost entirely AIO-free. Shopping triggers AIOs just 3.2% of the time.
9) For a given search query, Google’s AI Mode and AI Overviews reach the same conclusions 86% of the time — but cite almost entirely different sources (only 13.7% citation overlap).
10) AI Overviews change every 2.15 days on average, with 70% of content differing between consecutive observations. But semantic similarity stays at 0.95. The words, sources, and entities constantly shuffle, but the actual meaning barely moves.
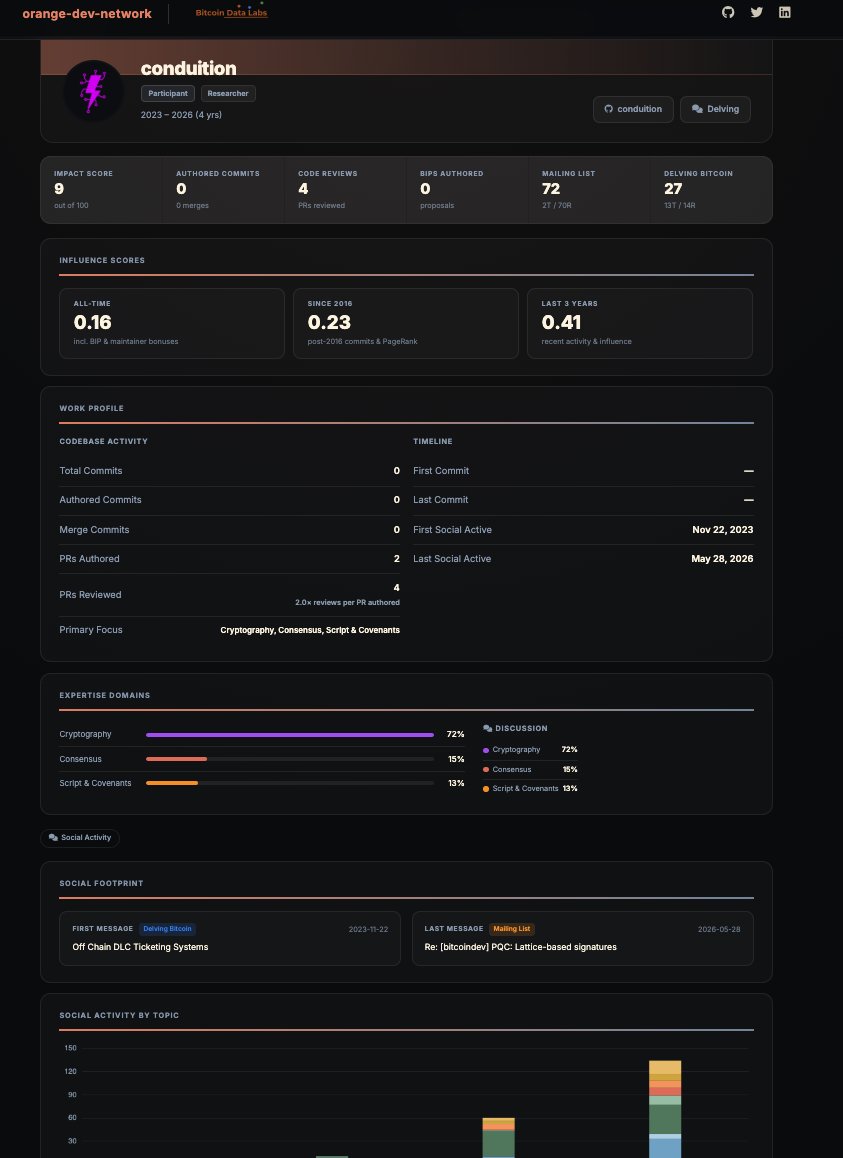
Congratulations, @conduition_io. Great pick, Mike!
your profile shows the pattern clearly:
Consistent, high-signal work through mailing list posts and Delving discussions on post-quantum cryptography.
Does this reflect your work accurately? I’d appreciate any thoughts on how to make it better.
https://t.co/oDAVxSzlLh
Congratulations, @conduition_io. Great pick, Mike!
your profile shows the pattern clearly:
Consistent, high-signal work through mailing list posts and Delving discussions on post-quantum cryptography.
Does this reflect your work accurately? I’d appreciate any thoughts on how to make it better.
https://t.co/oDAVxSzlLh
like the question.
We've been mapping the entire Bitcoin dev ecosystem — ~7k contributors tracked — and built an interactive influence graph + directory to surface both the big names and the unsung ones.
Sipa sits at #1 by impact, but the directory is full of people doing important work that doesn't always get visibility.
Might be useful for highlighting some of those folks:
https://t.co/5Hb7GkB5Qs
Finnish scientists trucked in real forest dirt and grass and laid it over the gravel at four daycare yards. They let the kids dig around in it for a month. The blood tests came back with changes the researchers hadn’t expected to see so fast or so clear.
The study ran at ten daycares in two Finnish cities with 75 kids aged three to five. Four of the yards got the forest treatment: about a tennis court worth of soil and grass laid over the gravel, plus planters and peat blocks the kids could dig and climb on. Three others stuck with their normal gravel yards. The last three were daycares where the kids were already visiting real forests every day.
After one month, the variety of bacteria living on the kids’ skin shot up, and the kind that helps train the skin’s immune defenses jumped the most. Their gut bacteria started to look like the gut bacteria of the forest-visiting kids. Their blood showed more of the immune cells whose job is to keep the body from freaking out at harmless stuff like pollen and peanuts, and overall inflammation dropped. The kids on the plain gravel yards showed none of this.
Childhood asthma in the US doubled between 1980 and 1995. Food allergies in kids jumped 50 percent between 1997 and 2011, then jumped another 50 percent between 2007 and 2021. And peanut allergies in one-year-olds tripled between 2001 and 2017.
The Finnish researchers think one of the reasons is simple: kids today don’t get dirty enough. 37 percent of American preschoolers now spend an hour or less outside on a normal weekday. Their immune systems are getting trained in environments stripped of the bacteria humans have always lived around.
Aki Sinkkonen, who led the study, put it in plain words: “It would be best if children could play in puddles and everyone could dig organic soil.” The Finnish government is now helping pay for daycares across the country to make the same changes.
This hits hard in tennis too.
Becoming pro is already brutal — but life doesn’t get easier once you make it.
Surviving and actually winning is just as tough.
Maybe that’s exactly what we love about Sports!
I made a quick viz on exactly that:
Steep odds: Only 1 in 2500 high school players turn pro.
Short careers: Over 50% drop out within 2 years.
Winner-takes-all: ~90% never win a trophy, while 1% take more than half.
Sponsorship struggle: Hard to sustain an ATP lifestyle outside the top 100.
Check it out: https://t.co/KMIlU0oWRK
@tennisabstract It'd be great for tennis if Jodar pulls off some magic here.
That said, I could live with Zverev too. one slam can work wonders and give us a solid third wheel for the next few years
Big thanks to @SoruKumar for an electric session at Bitcoin Builders Club #8⚡️
@Bitcoindatalabs is one of those projects that makes the whole ecosystem easier to understand.
More visibility into Bitcoin⚡️Lightning means more people can build with confidence.
Big love to everyone who showed up with curiosity & builder energy.
Learn more about Bitcoin Data Labs: https://t.co/dqcJG2aaBS
💻📱Recap video dropping on Monday: https://t.co/xBQrLDPpsc
📅⚡️Next one in June:
https://t.co/OowCPoUWOh
Explainable AI isn’t optional anymore — it’s becoming infrastructure.
Back in banking risk modeling, we chose regression over neural nets for the same reason: we needed to know who contributed what before signing off.
Today, when agents combine multiple models, tools, and content at inference time, fair attribution matters.
Who added the real value?
LIME and Integrated Gradients give useful local views. Yet @p0’s Index uses the gold standard: Shapley values.
They measure each player’s marginal contribution across every possible coalition — fair by design from cooperative game theory, now powering economics in the agent world.
Less guesswork, more precision.
Accessible intro: https://t.co/SkCkUBTVnn
Compensation in Index is calculated by estimating each source's Shapley value: its marginal contribution to an agent's answer at the moment of inference.
Content that's uniquely valuable, hard to replace, or used in high-value agent work earns more.
In an early meeting at Facebook (c. 2007), when I was describing the goals of Facebook Platform (an area I oversaw) Bill Gates yelled at me/us.
His quote has stuck with me to this day:
“This isn’t a platform. A platform is where the collective sum of revenues of the participants exceeds those of the platform itself.”
Ladies and gentlemen, I present to you the tokenmaxxing circle jerk.
More eyes on clean, usable data means
higher-quality insights,
real transparency,
genuine accountability,
stronger and robust growth across the entire ecosystem.
If you’re an analyst, PM, builder, or just data-curious about Bitcoin, come join us and help build it:
https://t.co/bdkX4dDedZ
What Bitcoin or Lightning data question have you always wished was easier to explore? Drop it below 👇
@Bitcoindatalabs@BTCBuildersClub@PlebLab@ThrillerX_@JuanSGalt
#Bitcoin #Lightning #OpenSource
Car is spot on. Making Bitcoin data truly legible changes everything.
That spirit is why I founded Bitcoin Data Labs.
https://t.co/lJPUVHATGW
Data everywhere. Yet almost impossible to drink. Water, water everywhere… not a drop to drink.
What @sorukumar is building with Bitcoin Data Labs really is highly consequential for anyone trying to understand where Bitcoin and Lightning are heading.
If you care about Bitcoin, Lightning, data, and where ecosystem intelligence is moving, I highly recommend coming through on Monday.
You’ll get exposed to a project that makes the network easier to see, understand, and build around.
We’re already shipping real value together:
• Dashboards — Mining Dashboard, Orange-dev-tracker, Orange-dev-network, PlebDashboard, Ln-graph-viz •
Tools — Lightning Network Simulator, Witness Data Decoder, Lightning Channel ID Decoder
All open-source, all built in the open.