@512banque "The lesson: the harness is a huge part of the value you feel as a user. And when some loops are this cheap, the optimal strategy changes: you can afford retries, parallel attempts, and verification passes instead of betting everything on one expensive first shot."
I got tired of abstract AI benchmarks that rank models in isolation.
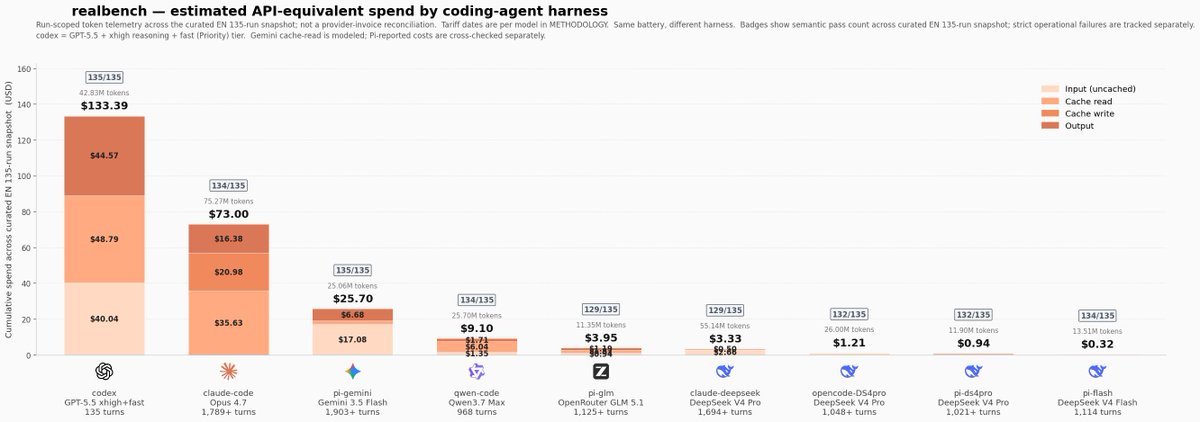
Users don't run a model. They run a full loop: model + harness + tools + retries + cache + prompts.
So I ran 27 tasks that look like my real work across different coding-agent harnesses, 5 times each to reduce variance. I also wanted to create my own tasks to avoid the problem of benchmaxxing.
Result: near-identical pass rates, wildly different bills.
Codex/Claude costs are API-equivalent because I use subscriptions. But at public API prices, one Codex setup charts at ~420× the cost of Pi + DeepSeek V4 Flash for the same strict score.
The lesson: the harness is a huge part of the value you feel as a user. And when some loops are this cheap, the optimal strategy changes: you can afford retries, parallel attempts, and verification passes instead of betting everything on one expensive first shot.
Don't trust my tasks. Run it on yours.
je suis très sceptique par rapport au "second cerveau" pour produire du contenu en full automatique sur un compte présenté comme personnel... quand je vois mon reach sur twitter même sur des tweets de merde ça me confirme que les gens veulent pas du dégueulis d'IA mais veulent vraiment connaître mon vrai avis à moi.
A la rigueur prémâcher le boulot avec l'IA, faire des recherches, reformuler des arguments, affuter son point de vue ok. Mais poster de la loghorrée full IA générative c'est un manque de respect.
Ici c'est full organique et full shitpost vous en faîtes pas les amigos 🫡
CrawlObserver va faire changer de dimension les audits SEO techniques, et quand on branche l’API @SEObserver_fr ça devient stratosphérique 🤯
encore un peu de patience avant l’envoi des mails pour la bêta privée…
en fait tout est là. les gens se déchirent sur le modèle mais c'est le HARNESS (cadrage/canalisation) = le workflow qui permet d'obtenir les meilleurs résultats. savoir piloter l'IA est le truc le plus important de nos jours.
CLAUDE-CEPTION: J'ai demandé à Claude de hacker son propre cerveau.
- Reverse engineering complet de Claude Code (CLI) : 12MB de javascript minifié décortiqués
- Comment prompter et ne pas prompter dans des cas pareils
- 3+1 règles de bonnes pratiques pour démarrer sur des projets dans lesquels on ne comprend rien.
On fait monter les enchères: si ce tweet a 200 RT je vous enregistre une vidéo claude code maintenant et je la poste ce soir-même. Sinon tranquille d'ici 1 semaine ou 2.
People being bearing for memory stocks, $sndk & $mu are fine, mostly bullish imo.
When you make AI inference cheaper and faster, you don't deploy the same amount more efficiently, you deploy more of it. A reduction in KV cache size means models with much longer context windows become possible plus it primarily addresses compute-side memory (GPU HBM/SRAM for KV cache), Rolling Out More efficient inference could actually accelerate the data pipeline (more queries served → more data generated → more storage needed).
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Je vais faire ma pickme. Si j'ai 100 RT sur ce tweet je crée une chaîne youtube claude code & AI pour détailler concrètement et en vidéo ce dont je parle sur ce compte X, dédiée aux noobs et aux + avancés. Du même acabit que ça, mais avec tous les détails:
https://t.co/4Qmsqsj7Z4