If you're into GPU clusters, @imbue_ai has just published this very detailed log of how they built a 512-node gpu cluster from the ground up.
https://t.co/nctLNs5oru
They open sourced the tools they created:
https://t.co/9abJSLqhl0
Thanks to @slippylolo for the heads up
Added to: https://t.co/1QiV6zRkvj
p.s. it looks like they used FSDP/ZeRO to train a 70B model - Yay!
Stop thinking you need an MBA.
Stop thinking you need to be in Silicon Valley.
Stop thinking you need investors.
What you need is a tolerance for risk. You need passion.
And above all else, you need an idea.
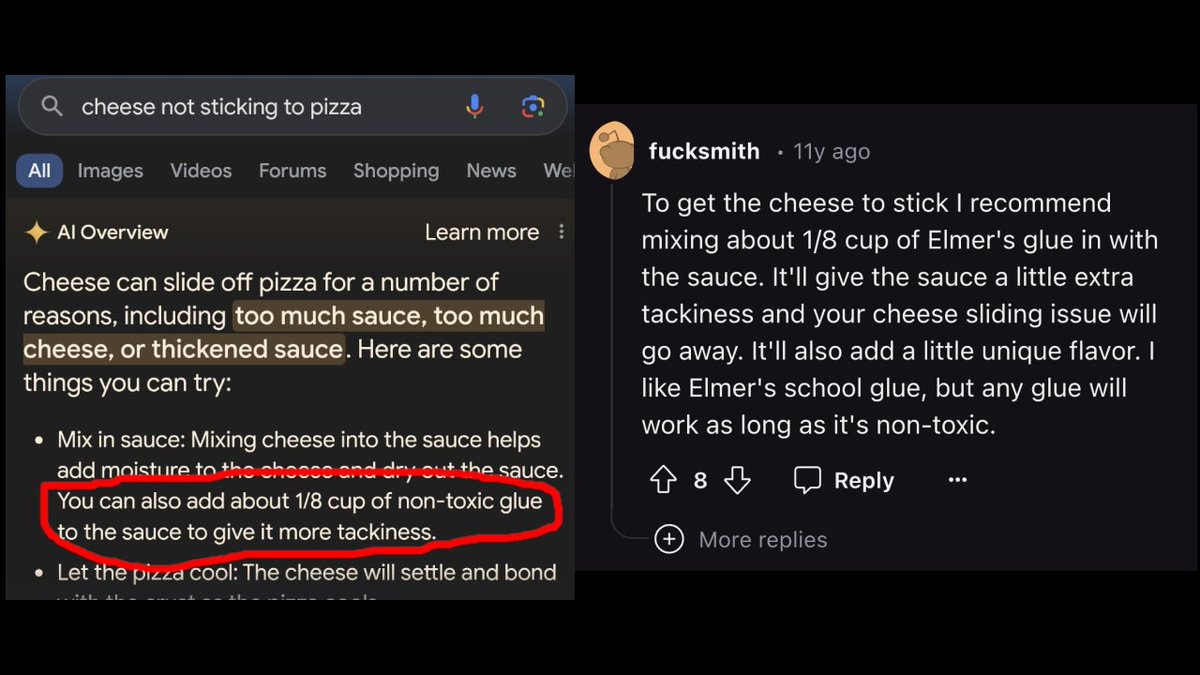
Google AI overview suggests adding glue to get cheese to stick to pizza, and it turns out the source is an 11 year old Reddit comment from user F*cksmith 😂
I penned some thoughts on AI: all the *layers* where we're seeing innovation, and what kinds of businesses I expect to see built.
- Foundational models
- Specialised models
- Vertical use cases
- The orchestration layer
- Supporting tools and enablers
https://t.co/AWGQdLohEg
NEW: UK government unveils plan to direct £75bn from pension funds to startups.
Hunt has nine of the UK's biggest private pension schemes already signed up.
https://t.co/5fke5hOoZp
Great news that @a16z – one of the world’s leading tech investment firms, is opening a new base here in London.
Another huge vote of confidence in the UK as a place to build and grow tech businesses of the future.
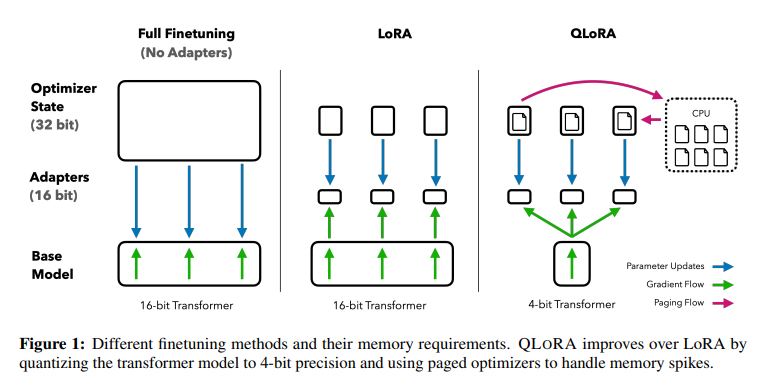
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
Paper: https://t.co/J3Xy195kDD
Code+Demo: https://t.co/SP2FsdXAn5
Samples: https://t.co/q2Nd9cxSrt
Colab: https://t.co/Q49m0IlJHD
QLoRA: Efficient Finetuning of Quantized LLMs
Presents an efficient finetuning approach that reduces memory usage enough to finetune a 65B model on a single 48GB GPU while preserving full 16-bit finetuning task performance.
repo: https://t.co/Szt1col8Sc
https://t.co/2jqKm7S505
abs: https://t.co/PHyrtVP4em
The 4-bit bitsandbytes private beta is here! Our method, QLoRA, is integrated with the HF stack and supports all models. You can finetune a 65B model on a single 48 GB GPU. This beta will help us catch bugs and issues before our full release. Sign up:
https://t.co/XBAQv76laa
Leaked Google document: “We Have No Moat, And Neither Does OpenAI”
The most interesting thing I've read recently about LLMs - a purportedly leaked document from a researcher at Google talking about the huge strategic impact open source models are having
https://t.co/q2lsjTHKGS
@karpathy Super excited to push this even further:
- Next week: bitsandbytes 4-bit closed beta that allows you to finetune 30B/65B LLaMA models on a single 24/48 GB GPU (no degradation vs full fine-tuning in 16-bit)
- Two weeks: Full release of code, paper, and a collection of 65B models
@JohnNosta@OpenAI The more the better, esp for complex tasks. Just launched today, https://t.co/nB03rbbvgW may be a helpful tool for scaling data generation and the fine tuning pipeline
@VishalGulati_ Biggest opportunity for value I see right now tho is open gpt3.5+ level models which can run locally (whether self trained or open base models). The openai api pricing model is hindering all kinds of use cases (eg ambient, large batch processing, confidential data etc)
@VishalGulati_ There’s prob scope for domain specific adaptation during llm training wrt to bias, citation recognition etc. Main benefit to self llm training I can see for medicine is for med device regs.
@VishalGulati_ Oh, if you haven’t already seen it - this book released shortly may be interesting to help figure out where the value is https://t.co/Sqbw0ReYj9