Belated post: excited to share I joined @ScribbleVC last year. Since 2015, I’ve tried to be like the best VCs I worked with as an operator/founder — show up when needed and stay out of the way when not. That’s also the Scribble way. Proud to be on board!
New AI x Science research:
Frontier models have gaps in their scientific knowledge. Our new eval tests how models recall significant published findings without tools, in Alzheimer’s disease.
GPT-5.5 performed best among released models, but the benchmark remains far from saturated.
Questions are based on prominent findings, often the central claims from highly cited papers, that were published before the models’ cutoff dates.
Does it impact AI x Science discovery agents? In the topics that the LLMs have gaps in “parametric” knowledge, agents using the model overlook potential discoveries -- even with tools and internet search.
The conclusion: training models more intensively on the latest scientific findings is a promising way to make scientific agents more useful!
“More information can be pulled into context. More information should be pulled into context. But there will always be a marginal query that the agent does not run, and the shape of this frontier is determined by internal knowledge.”
Link to research blog below:
Today is my last day at OpenAI, as OpenAI for Science is being decentralized into other research teams. It’s been a mind-expanding two years, from Chief Product Officer to joining the research team and starting OpenAI for Science. Accelerating science will be one of the most stunningly positive outcomes of our push to AGI, and I’m rooting for @sama@markchen90@fidjissimo@gdb@merettm and the whole team!
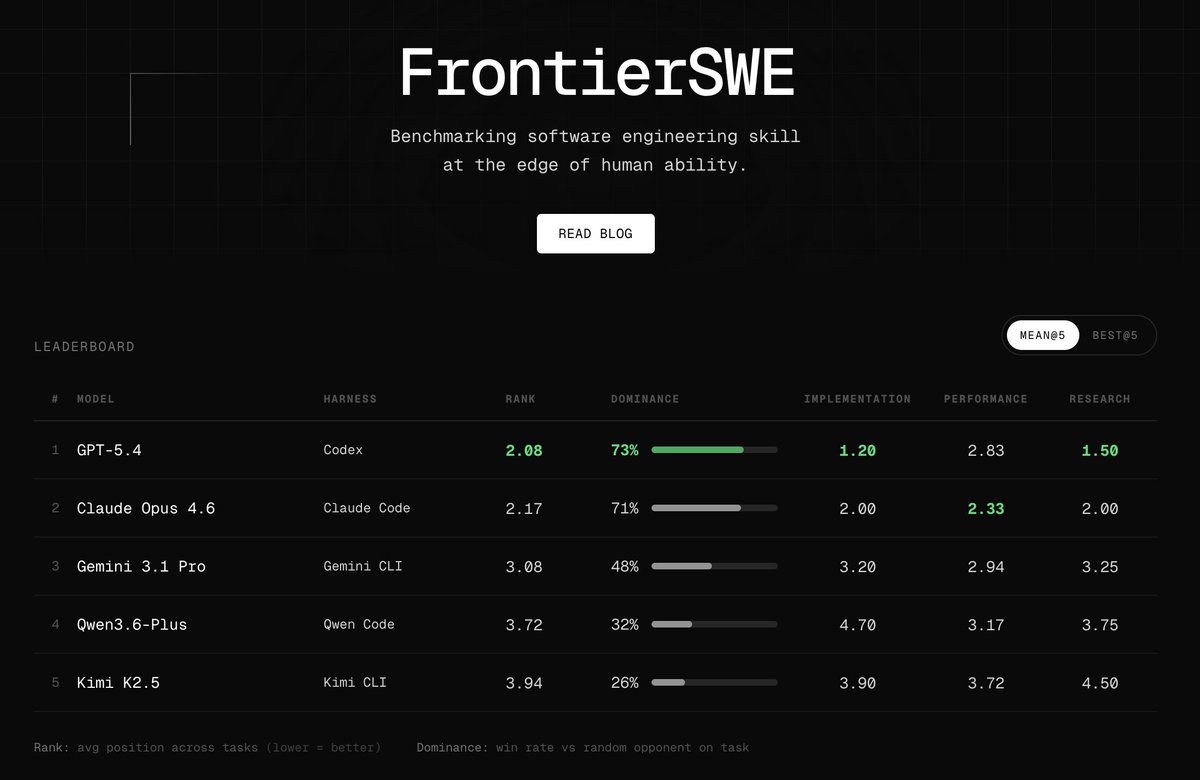
Introducing FrontierSWE, an ultra-long horizon coding benchmark.
We test agents on some of the hardest technical tasks like optimizing a video rendering library or training a model to predict the quantum properties of molecules.
Despite having 20 hours, they rarely succeed
you can now control things with your brain. literally.
we're building the most wearable BCI on the planet, with @sabi, backed by @khoslaventures@accel@initialized & @kevinweil.
we collected the world’s largest neural dataset and trained the most capable Brain Foundation Model.
then we invented a new class of biosensors powered by custom ASICs.
type without typing. click without clicking. a cap that lets your brain do the work.
we’re sabi.
Little textbooks called ‘primers’ shaped the first 200 years of American Education. Primer will shape the next 200.
This is our labor of love for the kids of America. A vision for the future of Education, featuring MarQuis – a real Primer student:
We raised $165M at a $1.15B valuation to stop doing demos.
2026 is about 1) deployment and 2) research. We will start shipping Memo with our new frontier models in a few months.
Our series-B is led by Coatue, with Thomas Laffont joining the board. ->🧵
Sunday's dishwasher-loading, laundry-folding robot starts beta testing this year.
CEO Tony Zhao explains how the robot learns — and why it wears a hat https://t.co/y7pJB6ynl1
Excited to release PostTrainBench v1.0!
This benchmark evaluates the ability of frontier AI agents to post-train language models in a simplified setting.
We believe this is a first step toward tracking progress in recursive self-improvement 🧵:
SO excited to welcome @stuartdsmith to @ScribbleVC!
He's a triple threat (founder + operator + investor) with a stellar track record.
But what makes him even more rare is that he's kind, humble, & a joy to talk to every single day.
Big win for our team & our founders!
We are pumped to welcome @stuartdsmith to @ScribbleVC!
This is great news for both our team & our founders.
Stu is kind and humble, yet has backed some of the best founding teams on the planet.
He's a triple-threat - a founder + operator + investor, and he brings that to bear for our founders as they build their companies and their networks.
Finally, he's a wonderful person and teammate, and we look forward to every conversation, every meeting, every decision, and every team offsite with him.
We are thrilled you joined us, @stuartdsmith!
"Have you really thought through your moat?"
"Is speed really your only lead right now?"
@elizabeth joins @glennsolomon@notablecap on hypergrowth lessons from the early days of Twitter & her early investments in Whatnot, Slack, Figma, + more.
Belated post: excited to share I joined @ScribbleVC last year. Since 2015, I’ve tried to be like the best VCs I worked with as an operator/founder — show up when needed and stay out of the way when not. That’s also the Scribble way. Proud to be on board!
today, we're introducing self diagnostics: the first ever way for agents to proactively self-report issues they encounter.
welcome to the future of agent observability.
Today, we are announcing Proximal. Proximal is a research lab for data. Our core belief is that data which is complex enough to teach today’s frontier models is not bottlenecked by domain experts, but by great ideas and excellent software.
We are excited about a world in which coding agents can autonomously run for multiple weeks, solve the hardest technical problems and discover novel ideas that advance progress in various domains of science and engineering.
We believe that we are not far from this future, but that the biggest bottleneck preventing us from achieving it is training data.
Many companies work on data, but most of them are approaching it the wrong way. Historical capability breakthroughs are the result of creative engineers discovering scalable data collection methods, not thousands of contractors manually writing task demonstrations.
Inevitably, the potential impact of human data will become smaller and smaller as model capabilities increase: agents are already outperforming most humans in many domains - the number of experts that are capable of judging model outputs shrinks with every new model release.
Proximal is a new data company. We are not a recruiting firm or a talent marketplace, but a research and engineering organization that treats data as a problem which deserves the same level of rigor as work on training algorithms and model architectures.
We think that this is the most impactful work towards agents that can autonomously solve complex technical problems, and intend to share our research and progress in the open.
Today a reset is taking place. The senior engineer making a million dollars a year in San Francisco uses the same frontier coding agent as the junior engineer in the Midwest. We talk to companies every day that are taking advantage of this reset, adopting expensive tools, putting in long hours, and still hitting a wall when AI struggles to understand their business context and intent.
The real truth is somewhere between the teams’ heads and the codebase.
Falconer gives everyone in the company, from engineering to sales to marketing to finance, a reliable source of truth. One that’s easy to contribute to and helps keep itself up to date.
If you want to know what changed in your product last week, ask Falconer to write a changelog.
If you want to understand how payment flows work for your new product, ask Falconer to create a diagram.
If you want to capture the decisions in your long Slack thread, ask Falconer to turn it into a document.
When the code changes, your PRDs, strategy docs, and runbooks get updated. Your employees are happy, your coding agents are happy.
Falconer was built with lessons in mind from making engineers at Uber and Stripe the most productive in the industry. We built custom tools for top tier talent. The results were remarkable. But outside of these companies, no one has access to these custom tools.
That’s what we had in mind when we built Falconer.
The quality of information you feed yourselves and your AI tools is how you get the most out of them and separate yourselves from the competition.
You can start centralizing and curating and compounding those gains over time, or you can let the bad information multiply, rot, and pollute your knowledge—severely limiting your AI leverage.
Everyone wants more knowledge, and everyone has knowledge to contribute.
Falconer is now available as your source of truth to achieve the productivity gains you’ve been searching for.
Craft and beauty are finally coming to internal docs. Today we're previewing Falconer: the single source of truth for company knowledge.
We're still working through our waitlist, but are now excited to take on more demo requests.
Engineers spend way too much time answering repeated questions and searching for outdated information. We experienced these problems during hypergrowth at Uber and Stripe and thought, "What if we applied external docs treatment to our internal docs?"
That simple approach achieved pretty remarkable results for productivity. And now Falconer is building the AI-native version of those platforms for everyone.
With Falconer, your internal docs are:
- In one place
- Always up to date
- Easy to find
- Synced with your data
Coding agents allow us to generate more code faster than ever...but that code is poorly understood and out of step with the company's crown jewels: business context and tribal knowledge.
Falconer's mission is to connect teams and agents with a shared memory system—always available and always accurate. We're working on it, and will have much more to share soon.
💥 Today we say “hello world” from OpenAI for Science.
We’re releasing a paper showing 13 examples of GPT-5 accelerating scientific research across math, physics, biology, and materials science. In 4 of these examples, GPT-5 helped find proofs of previously unsolved problems.