Why AI Progress Suddenly Feels Real - my conversation with @yanndubs, who co-leads the Post-Training Frontiers team at @OpenAI
00:00 - Intro
01:30 - Why recent AI progress feels like a step function
04:13 - Model reliability & the emotional rollercoaster of shipping GPT-5.5
07:33 - How OpenAI structures vertical and horizontal teams
09:49 - Improving model efficiency and test-time compute
12:32 - Yann's journey from Switzerland to OpenAI
15:37 - Reasoning in 2026: Real-world utility vs verifiable rewards
18:34 - GPT-5.5 Thinking vs Pro: Scaling test-time compute
20:09 - How reasoning models become more efficient
23:23 - Pre-training scaling and overcoming the data wall
27:03 - Multimodal data, synthetic data, and embodied AI
31:05 - Demystifying mid-training and post-training
37:21 - Does RL create new capabilities in AI?
38:53 - The challenges and frontier of scaling RL
43:09 - Is building AI models a craft or a strict science
48:21 - How AI models generalize across different domains
54:18 - How reinforcement learning cures AI hallucinations
56:04 - Negative generalization and conflicting instructions
58:05 - Can RL scale to law, medicine, and the broader economy?
1:00:19 - The evaluation bottleneck and Model as a Judge
1:04:21 - Continuous AI progress & continual learning
1:08:49 - Will foundation models eat the agent harness
1:11:23 - Why startups should focus on the last mile of AI
Every agent needs its own computer: my conversation with @ivanburazin, CEO of @daytonaio, about sandboxes and the emerging agent stack.
00:00 Intro
02:13 What is an AI agent sandbox?
03:17 Security risks of running agents locally
05:17 Stateful vs. stateless hyperscalers
07:04 The history of cloud IDEs and the end of localhost
09:45 Do all AI agents need a sandbox?
12:26 Sandbox use cases: RL evals & background agents
14:10 Unpacking the emerging AI Agent Stack
16:20 The unsolved problem of agent memory and learning
19:37 Where sandboxes fit in the agent harness
21:35 OpenAI, Anthropic, and agent SDKs
23:06 Ivan's founder journey: From CodeAnywhere to Daytona
26:59 GTM strategies and building developer communities
33:48 Why customer support is your best GTM strategy
35:34 Leveraging Twitter during the AI super cycle
40:50 The technical anatomy of a sandbox
41:53 Why fast spin-up speeds maximize GPU efficiency
46:09 Firecracker, QEMU, and isolation primitives
49:58 Why sandbox snapshots and state forking matter
51:40 Why Daytona built a custom scheduler from scratch
55:24 The challenge of long-running stateful sandboxes
58:10 The build your own sandbox trap
1:01:03 Why AI agents might trigger a global CPU shortage
1:02:46 The future of the AI Agent Stack
Claude Cowork, Mythos, and the Future of Software: my conversation with @felixrieseberg, who leads Cowork at @AnthropicAI
00:00 Intro
01:53 Claude Mythos Preview and the “step-function change”
06:16 Why Anthropic is treating Mythos differently
11:19 The real story behind Claude Cowork’s “10-day” build
12:42 Why Anthropic realized Claude Code needed a non-technical version
15:44 What Claude Cowork actually is
17:03 Under the hood: virtual machines, tools, skills
18:36 Where Cowork’s memory actually lives
19:26 How Cowork connects to files, apps, and the internet
20:45 Why Felix thinks the local computer is under-appreciated
24:49 Trust: how do you get users comfortable with AI agents?
28:45 What UX actually means for AI agents
31:27 Anthropic Cowork's roadmap is only one month long
34:12 Building 100 prototypes
35:10 If execution is free, what becomes the bottleneck?
37:25 Does it come down to taste?
40:12 The hardest part of building Claude Cowork
41:43 Advice for founders building AI agents
44:21 SaaSpocalypse: what’s left for software startups
49:30 Where AI agents are going next
51:20 Regulated industries and enterprise adoption
54:15 Hot takes: what's underrated, overrated, and what Felix would build today
Vibe coding prototypes is cool
Building production-grade, secure apps with AI you can actually run a business on… that’s a different ballgame
Huge launch day for @softr_io, crazy shipping velocity over the last year 🔥@mariam_hakobyan@mkrtchyanartur
Thrilled to announce that @FirstMarkCap has led the Series A in @tracebit_com , the company building the category-defining assume breach platform for the AI era, and I am joining the board. Our thesis is simple: prevention and zero trust alone are no longer enough. AI is expanding the attack surface faster than any team can defend it, and the smartest CISOs have stopped asking 'how do I keep attackers out' and started asking 'how do I catch them the moment they're in, before they can do any damage?' That's exactly what Tracebit does, and we couldn't be more excited to partner with Andy, Sam Cox and the rest of the team.
cc @Accel / @algovc, @TapestryVC, @MMC_Ventures, and CCL.
Everything Gets Rebuilt: my conversation with Harrison Chase, CEO of @LangChain about agent harnesses, evals, runtimes, sandboxes, MCP and the future of the agent stack
00:00 Intro - meet @hwchase17 - at the Chase Center for the @daytonaio Compute conference
01:32 What changed in agents over the last year
03:57 Why coding agents are ahead
06:26 Do models commoditize the framework layer?
08:27 Harnesses, in plain English
10:11 Why system prompts matter so much
13:11 The upside — and downside — of subagents
15:31 Why a useful agent needs a filesystem
18:13 Additional core primitives of modern agents
19:12 Skills: the new primitive
20:19 What context compaction actually means
23:02 How memory works in agents
25:16 One mega-agent or many specialized agents?
27:46 The future of MCP
29:38 Why agents need sandboxes
32:35 How sandboxes help with security
33:32 How Harrison Chase started LangChain
37:24 LangChain vs LangGraph vs Deep Agents
40:17 Why observability matters more for agents
41:48 Evals, no-code, and continuous improvement
44:41 What LangChain is building next
45:29 Where the real moat in AI lives
Thrilled to partner with @MaxJunestrand, @siggelabor, @davidneckstein, Pat, Jacob and the entire @WeAreLegora team as they build the legal operating system for the AI era!
Legal work demands judgment, precision, and trust. What’s exciting about this moment is that AI can actually support that work in a meaningful way, helping legal teams move faster, navigate complexity, and deliver high-quality work without compromising rigor.
That’s a big part of why we’re so excited about Legora. They’re building the leading platform around how legal work actually gets done.
Voice used to be AI’s forgotten modality - now it's having its big moment: rapid innovation, big funding rounds, major agentic applications
My conversation with @neilzegh, top AI researcher in the field (@GoogleDeepMind, @Meta, @kyutai_labs) and now CEO of @GradiumAI
This is a reference episode on all things voice AI 🔥
00:00 Intro
01:21 Voice AI’s big moment, and why we’re still early
03:34 Why voice lagged behind text/image/video
06:06 The convergence era: transformers for every modality
07:40 Beyond Her: always-on assistants, wake words, voice-first devices
11:01 Voice vs text: where voice fits (even for coding)
12:56 Neil’s origin story: from finance to machine learning, with help from @ylecun and @soumithchintala
18:35 Neural codecs (SoundStream): compression as the unlock
22:30 Kyutai: open research, small elite teams, moving fast 31:32
Why big labs haven’t “won” voice AI4
34:01 On-device voice: where it works, why compact models matter
46:37 The last mile: real-world robustness, pronunciation, uptime
41:35 Benchmarking voice: why metrics fail, how they actually test
47:03 Cascades vs speech-to-speech: trade-offs + what’s next
54:05 Hardest frontier: noisy rooms, factories, multi-speaker chaos
1:00:50 New languages + dialects: what transfers, what doesn’t
1:02:54 Hardware & compute: why voice isn’t a 10,000-GPU game
1:07:27 What data do you need to train voice models
1:09:02 Deepfakes + privacy: why watermarking isn’t a solution
1:12:30 Voice + vision: multimodality, screen awareness, video+audio
1:14:43 Voice cloning vs voice design: where the market goes
1:16:32 Paris/Europe AI: talent density, underdog energy, what’s next
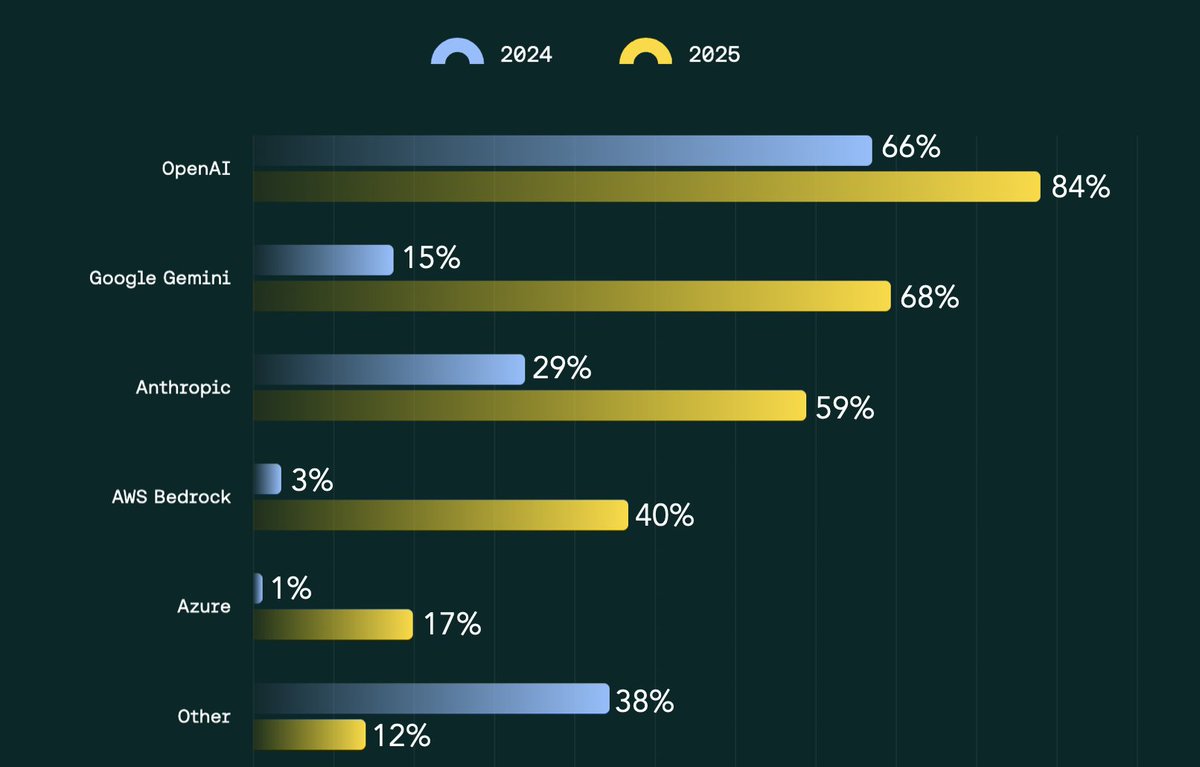
Lots of chatter around which models are winning the enterprise war
We asked 150+ CTOs / CPOs in our @FirstMarkCap Guilds (mix of F1000 + private unicorns) what they use. Small curated sample that's very enterprise skewed, admittedly
This isn't "the market," but it is what the moment in time standard looks to be inside large co's:
- OpenAI leads on primary API usage
- Gemini and Anthropic have gained real ground YoY
- "Other" has collapsed as the large labs have consolidated spend
- 58%+ of respondents use 2+ model APIs across their org
Bigger takeaway: ask different audiences, get different answers. Hackers, startups, MM co's, and global enterprises are operating under different parameters (security, procurement, data residency, multi-model strategy, etc)
Excited to be leading @VillageSQL $25M Series A alongside @GVteam , @sparkcapital & @homebrew .
@VillageSQL is reigniting innovation in MySQL 🔥 - bringing permissionless extensions & AI-native functionality inside the database, without migrations.
Big moment for the MySQL ecosystem.
#AI #Databases #OpenSource #MySQL #VentureCapital
https://t.co/MZojBqEa2E
NVIDIA's New Moat & Why China is "Semiconductor Pilled” — loved my conversation with Dylan Patel (@dylan522p).
Raw, incredibly insightful, and... hilarious.
00:00 - Intro
01:16 - Nvidia acquires Groq: A pivot to specialization
07:09 - Why AI models might need "wide" compute, not just fast
10:06 - Is the CUDA moat dead? (Open source vs. Nvidia)
17:49 - The startup landscape: Etched, Cerebras, and 1% odds
22:51 - Geopolitics: China's "semiconductor-pilled" culture
35:46 - Huawei's vertical integration is terrifying
39:28 - The $100B AI revenue reality check
41:12 - US Onshoring: Why total self-sufficiency is a fantasy
44:55 - Can the US actually build fabs? (The delay problem)
48:33 - The CapEx Bubble: Is $500B spending irrational?
54:53 - Energy Crisis: Why gas turbines will power AI, not nuclear
57:06 - The "AI uses all the water" myth (Hamburger comparison)
1:03:40 - Circular Debt? Debunking the Nvidia-CoreWeave risk
1:07:24 - Claude Code & the software singularity
1:10:23 - The death of the Junior Analyst role
1:11:14 - Model predictions: Opus 4.5 and the RL gap
1:14:37 - San Francisco Lore: Living with roommates @dwarkesh_sp & @_sholtodouglas
Every human worker needs a computer. Soon, every AI agent will too, but not one: millions, provisioned instantly, securely isolated, and running in parallel.
Thrilled to be partnering with @ivanburazin (who didn't a break during the holidays), @JukicVedran and @daytonaio (+ @upfrontvc, @datadoghq, @figma, @PaceCap)
https://t.co/fV3sXFTWeh
Very excited to announce our $20m Series A in @porterdotrun, led by the fantastic Justin Rhee (@rheejust). Porter was built to make infrastructure something startups don’t have to relearn as they scale, delivering a full PaaS experience inside their customer’s own cloud accounts. Porter has quickly become the default choice for this generation of AI companies (cc @TennrOfficial, @outtake_ai, @ModelML_, @GigaAI), already a top-five all time most used dev tool in YC, but impressively touts public companies and $1bn+ revenue businesses as customers as well. Their product roadmap is endless and we couldn’t be more excited to be on the journey with Justin and team.
NYC Angel Investors!
FirstMark, @alley_corp, @usv, @LererHippeau, and @InspiredCap are hosting the inaugural NYC Angels Summit, bringing together a select group of the most active and up-and-coming angels investing in the NYC ecosystem.
Apply to attend at the link below ⬇️
Gemini 3, scaling laws and the 'finite data' era: my conversation with @borgeaud_s, research engineer at @GoogleDeepMind and a pre-training lead for Gemini 3
00:00 – Cold intro: “We’re ahead of schedule” + AI is now a system
00:58 – @OriolVinyalsML's “secret recipe”: better pre- + post-training
02:09 – Why AI progress still isn’t slowing down
03:04 – Are models actually getting smarter?
04:36 – Two–three years out: what changes first?
06:34 – AI doing AI research: faster, not automated
07:45 – Frontier labs: same playbook or different bets?
10:19 – Post-transformers: will a disruption happen?
10:51 – DeepMind’s advantage: research × engineering × infra
12:26 – What a Gemini 3 pre-training lead actually does
13:59 – From Europe to Cambridge to DeepMind
18:06 – Why he left RL for real-world data
20:05 – From Gopher to Chinchilla to RETRO (and why it matters)
20:28 – “Research taste”: integrate or slow everyone down
23:00 – Fixes vs moonshots: how they balance the pipeline
24:37 – Research vs product pressure (and org structure)
26:24 – Gemini 3 under the hood: MoE in plain English
28:30 – Native multimodality: the hidden costs
30:03 – Scaling laws aren’t dead (but scale isn’t everything)
33:07 – Synthetic data: powerful, dangerous?
35:00 – Reasoning traces: what he can’t say (and why)
37:18 – Long context + attention: what’s next
38:40 – Retrieval vs RAG vs long context
41:49 – The real boss fight: evals (and contamination)
42:28 – Alignment: pre-training vs post-training
43:32 – Deep Think + agents + “vibe coding”
46:34 – Continual learning: updating models over time
49:35 – Advice for researchers + founders
53:35 – “No end in sight” for progress + closing
A major new entrant in voice AI: @GradiumAI
If we were designing computers from scratch today, the default interface probably wouldn’t be a keyboard. It would be voice.
Voice is the most natural interface we have, and probably the most underserved modality in AI today.
We’re excited to announce that @FirstMarkCap is co-leading Gradium’s $70M seed round with Eurazeo alongside DST Global, Eric Schmidt, Xavier Niel, Rodolphe Saadé, Korelya, Amplify Partners and others.
Gradium was founded in September 2025 by @neilzegh (Meta/Google DeepMind), @olivierteboul (Google Brain), @lmazare (Google DeepMind/Jane Street) and @honualx (Meta). Collectively they invented and open-sourced neural audio codecs and audio language models, and used this technology to power the very first voice cloning, text-to-music generation and speech-to-speech translation. They then created @kyutai_labs , a non-profit lab pushing the frontiers of multimodal LLMs, in particular releasing the first real-time conversational model in 2024.
If you’re building anything voice-native – agents, games, learning tools, healthcare or something entirely new – you can start working with the product today at https://t.co/tRyHCIJSKI.