Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
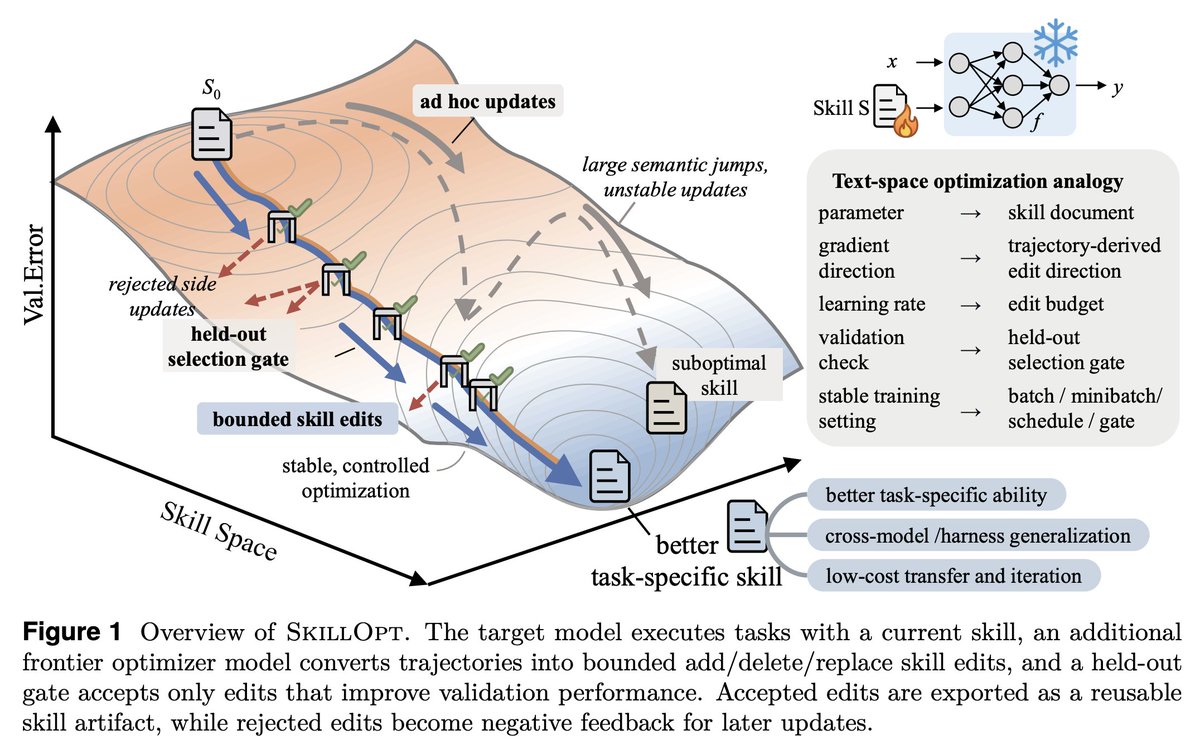
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
My new article "Toward a science of intelligence: unifying physics, neuroscience and AI" https://t.co/9jVmJzg1BW
published in the Daedelus journal of @americanacad
Its part of a special issue on AI+Science with many amazing contributors lead by James Manyika https://t.co/3Z7aer186F
Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
We know surprisingly little about how automation will unfold outside rich countries.
So we built the Global Automation Atlas: 18,000 tasks, 124 countries, and 2.3 million task-country comparisons.
This paper is a banger that documents how technological change transforms research agendas.
Rather than shaking up the questions people were interested in, computers let researchers tackle questions they already cared about but were bottlenecked by compute. Quite relevant for thinking about AI & science imo!
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
Human opinions are complex and diverse. What do LLMs understand about them?
In our new #ICLR paper, we find that LLMs know far more about human opinions than is revealed in their outputs, and develop SAE methods to bring this knowledge to the surface + steer to different groups.
Terence Tao proposes what he calls a "Copernican view of intelligence".
Instead of buying into the common, one-dimensional narrative that artificial intelligence will simply evolve from "subhuman" to "superhuman" and ultimately make humanity entirely redundant, Tao urges us to look at the bigger picture.
Much like the Copernican revolution proved the Earth is not the center of the universe, Tao suggests we need to realize that human intelligence isn't the only, or necessarily the highest, form of intellect. Historically, we have treated other forms of storing or creating knowledge—like animals, books, and computers—as secondary. However, we actually exist within a much richer universe of intelligence.
Both human intelligence and computer intelligence possess their own distinct strengths and weaknesses. The true potential lies not in viewing them as direct competitors, but rather in focusing on collaboration. By working together, humans and computers can achieve additional things that neither could accomplish on their own, requiring us to think in much wider terms than just what humans or computers can do alone.
I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: https://t.co/m5vkJxWIY6
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep@GavinSherry
I increasingly believe that there are fundamental principles which simultaneously govern the designs of well-functioning minds, organizations and societies.
Once we pin them down with mathematical precision, we’ll understand the world more deeply than we can currently imagine.
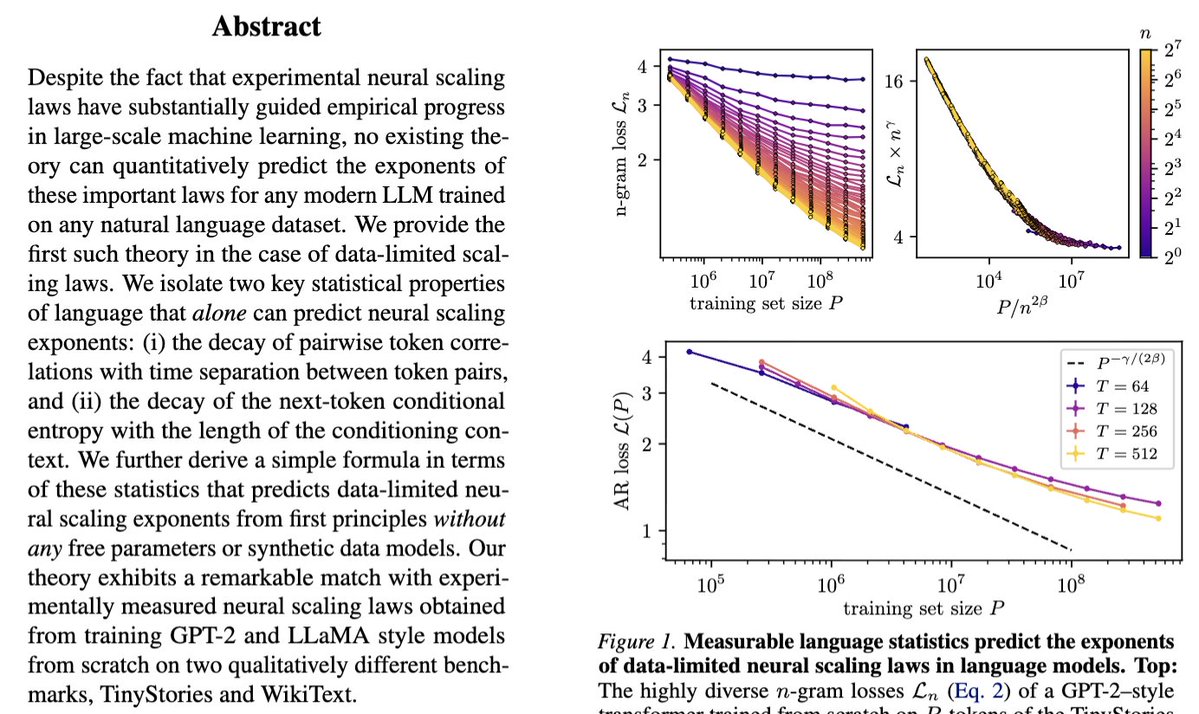
Our new paper "Deriving neural scaling laws from the statistics of natural language" https://t.co/7QbrldK8Zp lead by @Fraccagnetta & @AllanRaventos w/ Matthieu Wyart makes a breakthrough! We can predict data-limited neural scaling law exponents from first principles using the structure of natural language itself for the very first time!
If you give us two properties of your natural language dataset:
1) How conditional entropy of the next token decays with conditioning length.
2) How pairwise token correlations decay with time separation.
Then we can give you the exponent of the neural scaling law (loss versus data amount) through a simple formula!
The key idea is that as you increase the amount of training data, models can look further back in the past to predict, and as long as they do this well, the conditional entropy of the next token, conditioned on all tokens up to this data-dependent prediction time horizon, completely governs the loss! This gets us our simple formula for the neural scaling law!
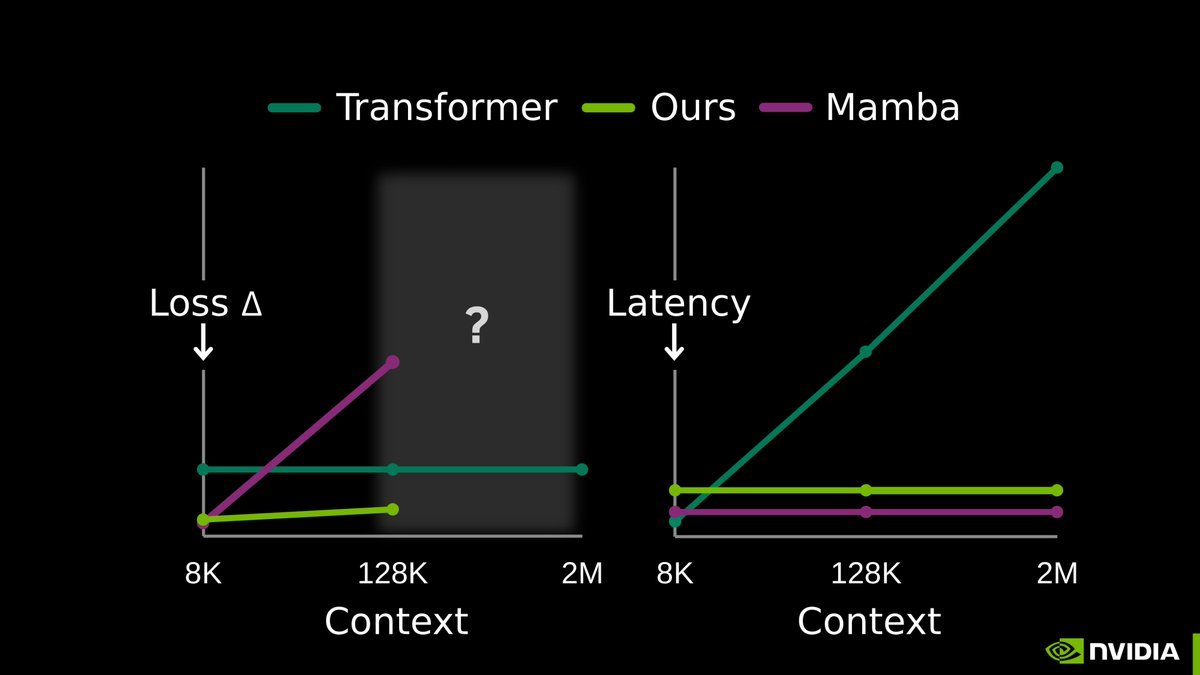
LLM memory is considered one of the hardest problems in AI.
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: https://t.co/woCpiIrq0T
Arxiv: https://t.co/3VkFlS3wx3
This has been over a year in the making with @arnuvtandon and an incredible team.
Introducing the World's First Fact-Checking Marketplace
Disinformation spreads like wildfire.
@factcheckdotfun will fight fake news with financial incentives and AI.
We're building on @base to change how facts will be verified forever.
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
📈Out today in @PNASNews!📈
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:
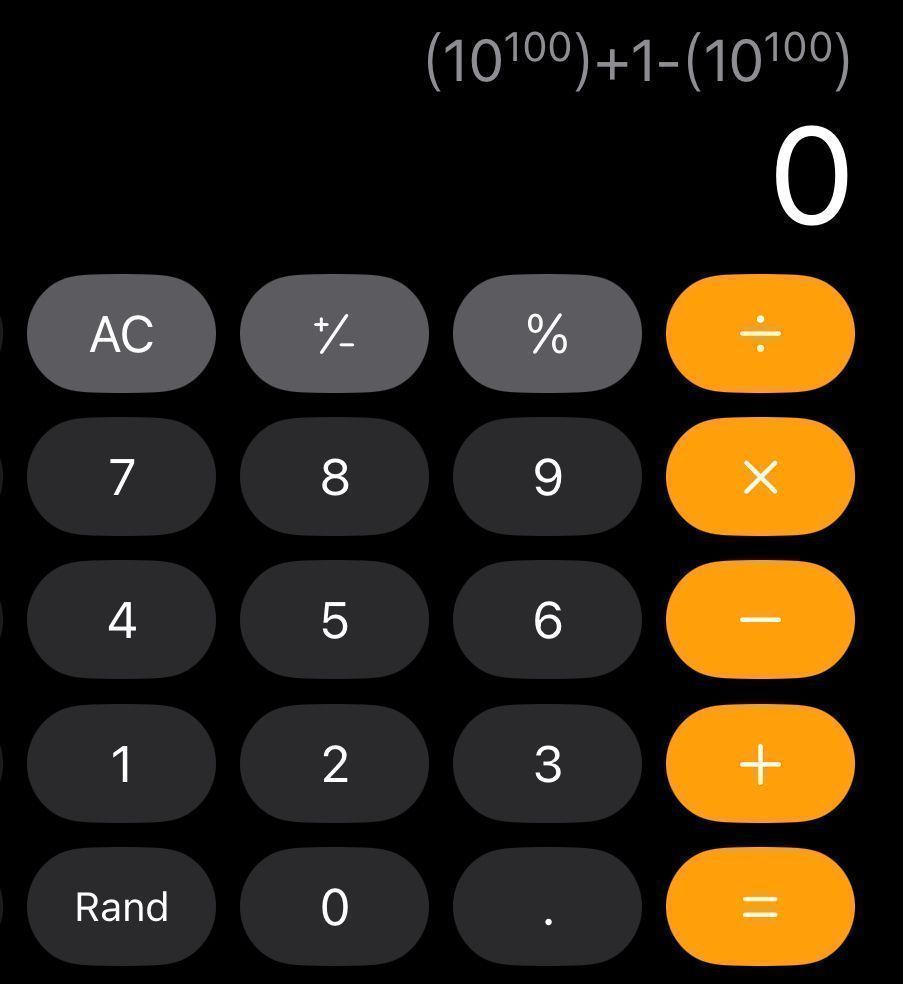
"A calculator app? Anyone could make that."
Not true.
A calculator should show you the result of the mathematical expression you entered. That's much, much harder than it sounds.
What I'm about to tell you is the greatest calculator app development story ever told.