The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
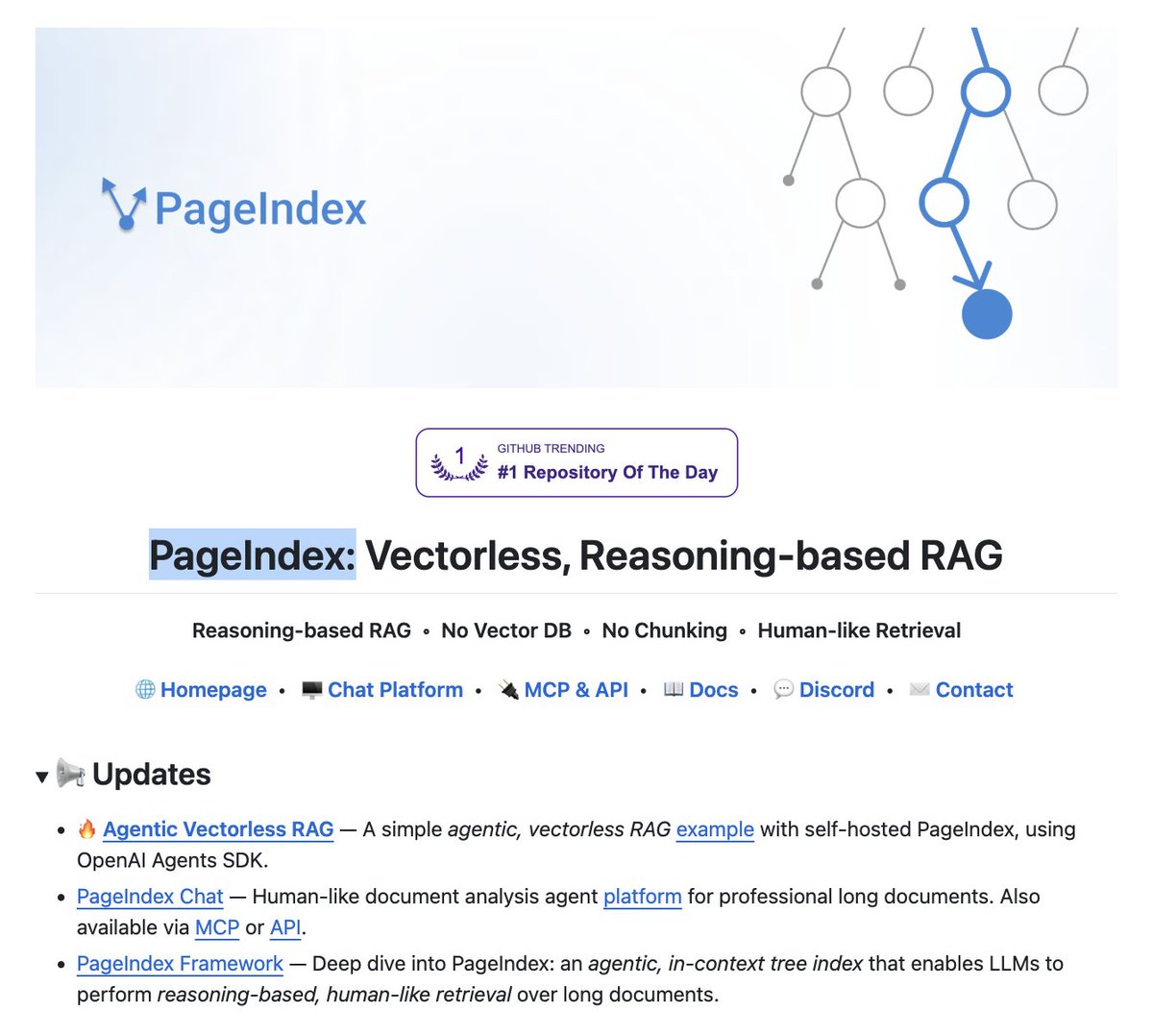
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
Claude Code ships with 5 architectural layers most engineers never open.
Not features. Not settings. Layers — each solving a distinct problem that LLMs alone can't solve. And four of them have nothing to do with prompting.
Here's the full Agent Development Kit:
Layer 1 — CLAUDE.md → The Memory Layer
Architecture rules, naming conventions, test expectations, repo map. Always loaded. Always active.
Two scopes:
• ~/.claude/CLAUDE.md → global
• .claude/CLAUDE.md → project
This isn't context you paste in before every session. It's context that never needs repeating. The agent's constitution.
Layer 2 — Skills → The Knowledge Layer
Each SKILL.md carries a description. Claude matches it at runtime and forks the skill into an isolated subagent. On-demand, never always-on.
Task-specific knowledge without inflating your main context window. Modular by design.
Layer 3 — Hooks → The Guardrail Layer
PreToolUse → PostToolUse → SessionStart → Stop → SubagentStop
This is the layer most teams skip. And the one they regret skipping first.
Hooks are NOT AI. They're deterministic event-driven shell commands.
• Auto-lint on every Write
• Hard-block on rm -rf
• Slack notification on Stop
Event fires → Matcher checks → Command runs
Quality enforced at the infrastructure level. Not the prompt level.
Layer 4 — Subagents → The Delegation Layer
Each subagent gets its own context window, model, tools, and permissions.
Main agent delegates down. Receives results up. That's it.
No infinite recursion — subagents can't spawn subagents. Main context stays clean. Hard boundaries by design.
Layer 5 — Plugins → The Distribution Layer
Bundle your skills + agents + hooks + commands into a plugin. One install. Whole team inherits the behavior.
Think npm packages — but for what your agent knows how to do.
Wrapping everything:
→ MCP Servers on the left (GitHub, databases, APIs, custom integrations)
→ Agent Teams on the right (parallel execution, message passing, shared permissions)
The 5-layer stack in one line:
CLAUDE.md sets rules → Skills provide expertise → Hooks enforce quality → Subagents delegate work → Plugins distribute to the team
Most production failures in agentic systems trace back to one missing layer.
Which one is the gap in your current setup?
AI coding without structure is just a Ferrari on muddy roads: very fast, very stuck. SPDD says: version the prompt, review the intent, then let the model write code inside the guardrails.
🤩 Structured-Prompt-Driven Development by @thoughtworks
Treats prompts as first-class engineering artifacts:
→ Prompts live in version control
→ Requirements, design, norms, and safeguards are captured up front
→ Code generation follows a structured blueprint
→ Logic changes update the prompt first
→ Refactors sync back into the prompt
https://t.co/E70oBhYiZ6
This 2-hour Stanford lecture breaks down how models like ChatGPT and Claude are actually built, clearer than what many people in top AI roles ever get exposed to.
Save this and set aside two hours today. It might end up being the most valuable thing you learn all week.
Automations can now run in the same thread, so Codex can pick up where it left off, with the original context intact.
It can schedule future work and wake up automatically to continue long-term tasks, from landing open PRs to following up on tasks or staying on top of fast-moving conversations.
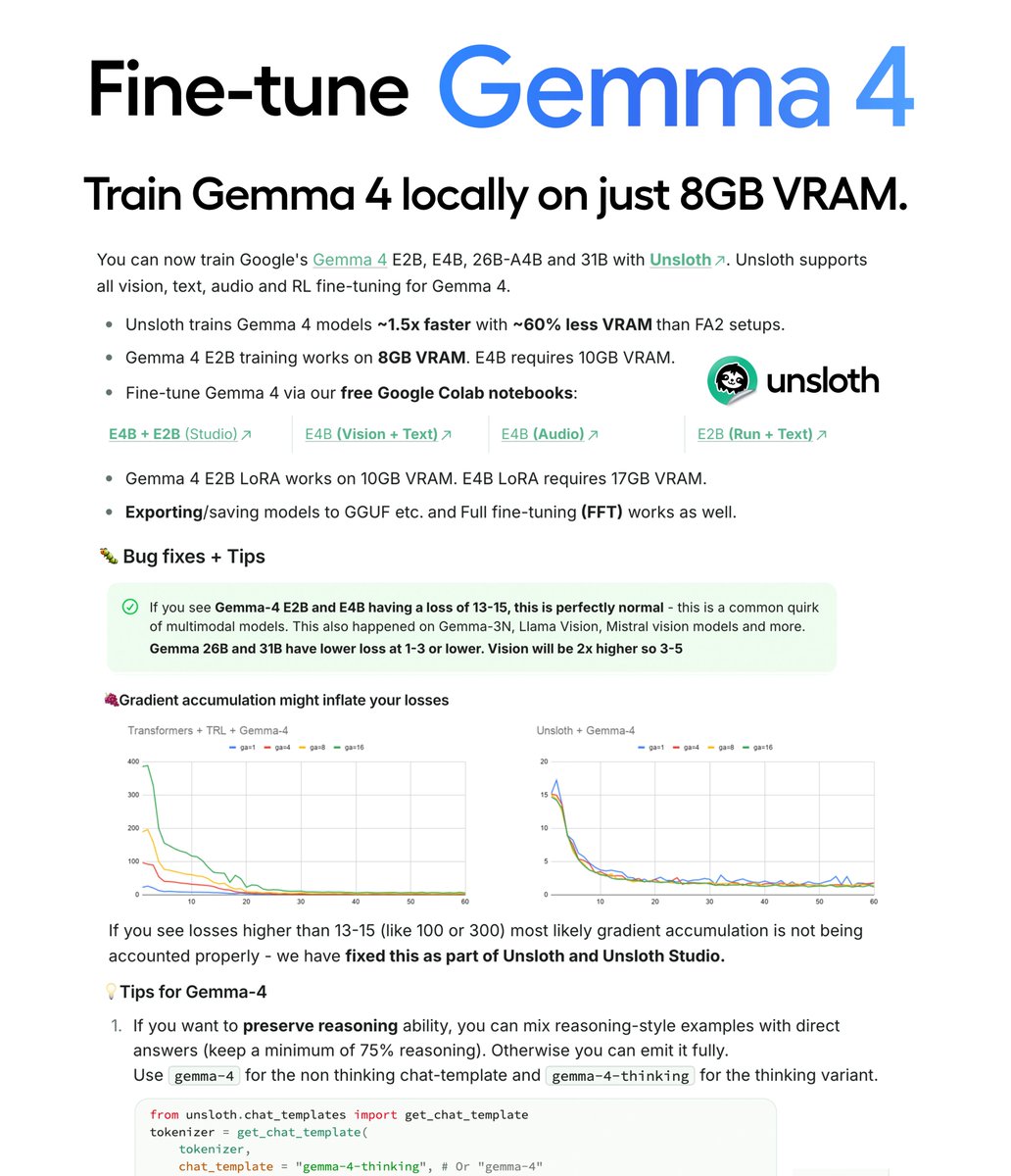
You can now fine-tune Gemma 4 with our free notebooks! 🔥
You just need 8GB VRAM to train Gemma 4 locally!
Unsloth trains Gemma4 1.5x faster with 50% less VRAM.
GitHub: https://t.co/aZWYAtakBP
Guide: https://t.co/NBwKoFH2lp
Gemma-4-E4B Colab: https://t.co/JjpCQgWEpL
🚨 Microsoft has solved the biggest problem with AI.
They open-sourced bitnet.cpp. It’s a 1-bit inference framework that runs massive 100B parameter models directly on your CPU without GPUs.
it uses 82% less energy.. 100% open-source.
Gemma 4 can run on phones without an internet connection! 🤯
It can perform local agentic tasks, such as logging and analyzing trends. When connected, it can also make API calls.
Want to try it yourself? Get the Google AI Edge App on iOS or Android. (🔊 Sound on for the demo!)
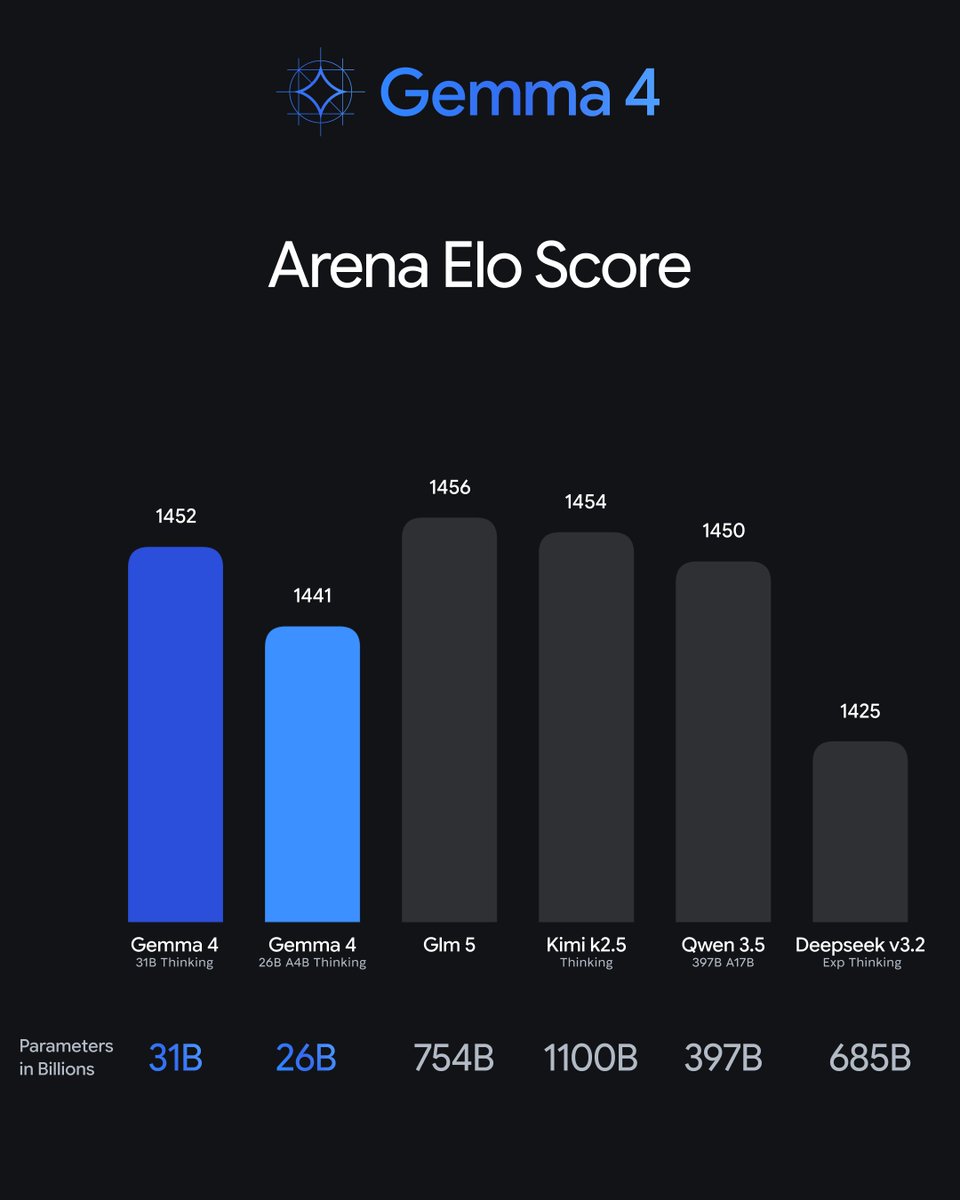
Who wants to know how Gemma 4 works?
This visual guide breaks down the new architectures and how they process text, images, and (for the smaller models) audio.
👇
Available in four sizes:
🔵 31B Dense & 26B MoE: state-of-the-art performance for advanced local reasoning tasks – like custom coding assistants or analyzing scientific datasets.
🔵 E4B & E2B (Edge): built for mobile with real-time text, vision, and audio processing.
Meet Gemma 4: our new family of open models you can run on your own hardware.
Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
This research is a product of our Anthropic Fellows program, led by @tomjiralerspong and supervised by @TrentonBricken.
See the full paper here: https://t.co/gz1i1Oy8ZI
Follow along with @jecfish as she shows you how WebDriver BiDi supercharges cross-browser testing 🧪 Learn how this browser automation can help with mock network requests and monitoring console events ▶️ https://t.co/TiNXQyZpJV
A simple way to explain 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆.
In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available.
It is useful to group the memory into four types:
𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions.
𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers.
𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries.
𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand.
𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system.
We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory.
A visual explanation of potential implementation details 👇
And that is it! The rest is all about how you architect the flow of your Agentic systems.
What do you think about memory in AI Agents?
#LLM #AI #MachineLearning
Want to learn how to build an Agent from scratch without any LLM orchestration framework? Follow my journey here: https://t.co/dQS4CtNPC0
🚨Ilya Sutskever finally confirmed
> scaling LLMs at the pre-training stage plateaued
> the compute is scaling but data isn’t and new or synthetic data isn’t moving the needle
What’s next
> same as human brain, stopped growing in size but humanity kept advancing, the agents and tools on top of LLMs will fuel the progress
> sequence to sequence learning
> agentic behavior
> teach self awareness
Think of it as the “iPhone”, which kept getting bigger and more useful from hardware point, but plateaued and the while focused shifted to applications.
2025 will be the year of Agents!
> @Replit for coding
> @seobotai for content
> @crewAIInc for the rest
I’ve been recommending Bolt or v0 for full-stack code bootstrapping, and Cline or Cursor for iteration. Quick tips:
✍️ Make sure requirements are clear
🔎 Test & verify all changes are expected
💵 Plan around token limits & costs