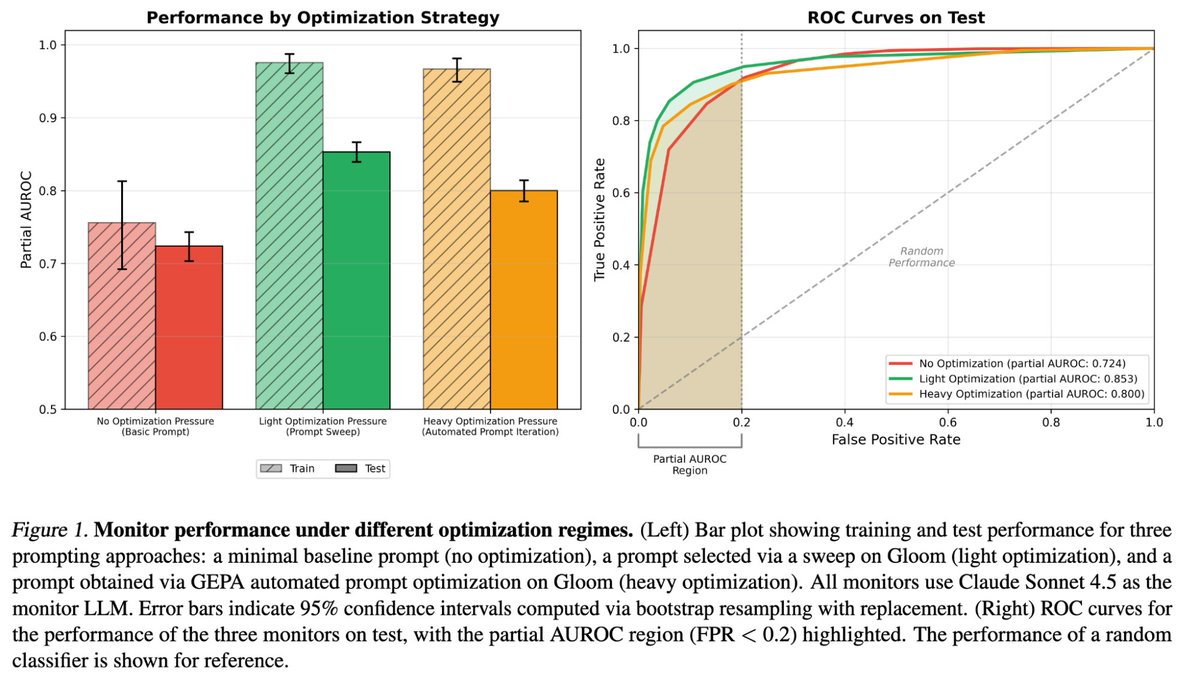
We found that fine-tuning can improve scheming monitors substantially even on meaningfully OOD evals.
I'm now even more convinced that there are a lot of low-hanging fruit to improve monitors and Apollo & external collaborators (e.g. MATS) will continue to try and plug them!
Black-box monitors can detect scheming in AI agents using only external behavior.
We optimized prompted monitors on synthetic data and tested on more realistic trajectories:
• Monitors generalize from synthetic to realistic
• Simple optimization methods saturate performance
One practical takeaway: given a setup similar to ours, you need to optimize less than you think. Generate diverse prompts with frontier models, pick the best on the data, then stop. Monitors readily overfit with further optimization (e.g. automated prompt optimization), risking worse performance in the real setting.
Paper: https://t.co/JtsA1R5ZVG
MATS 9.0 applications are open! Launch your career in AI alignment, governance, and security with our 12-week research program. MATS provides field-leading research mentorship, funding, Berkeley & London offices, housing, and talks/workshops with AI experts.
New paper: What happens once AIs make humans obsolete?
Even without AIs seeking power, we argue that competitive pressures will fully erode human influence and values.
https://t.co/efbmjqcTIy
with @jankulveit@raymondadouglas@AmmannNora@degerturann@DavidSKrueger 🧵
Does style matter over substance in Arena? Can models "game" human preference through lengthy and well-formatted responses?
Today, we're launching style control in our regression model for Chatbot Arena — our first step in separating the impact of style from substance in rankings.
Highlights:
- GPT-4o-mini, Grok-2-mini drop below most frontier models when style is controlled
- Claude 3.5 Sonnet, Opus, and Llama-3.1-405B rise significantly
- In Hard Prompts, Claude 3.5 Sonnet ties for #1 with ChatGPT-4o-latest. Llama-405B climbs to joint #3.
More analysis in the thread below👇
# RLHF is just barely RL
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
What would it look like to train AlphaGo with RLHF? Well first, you'd give human labelers two board states from Go, and ask them which one they like better:
Then you'd collect say 100,000 comparisons like this, and you'd train a "Reward Model" (RM) neural network to imitate this human "vibe check" of the board state. You'd train it to agree with the human judgement on average. Once we have a Reward Model vibe check, you run RL with respect to it, learning to play the moves that lead to good vibes. Clearly, this would not have led anywhere too interesting in Go. There are two fundamental, separate reasons for this:
1. The vibes could be misleading - this is not the actual reward (winning the game). This is a crappy proxy objective. But much worse,
2. You'd find that your RL optimization goes off rails as it quickly discovers board states that are adversarial examples to the Reward Model. Remember the RM is a massive neural net with billions of parameters imitating the vibe. There are board states are "out of distribution" to its training data, which are not actually good states, yet by chance they get a very high reward from the RM.
For the exact same reasons, sometimes I'm a bit surprised RLHF works for LLMs at all. The RM we train for LLMs is just a vibe check in the exact same way. It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. These predictions can look really weird, e.g. you'll see that your LLM Assistant starts to respond with something non-sensical like "The the the the the the" to many prompts. Which looks ridiculous to you but then you look at the RM vibe check and see that for some reason the RM thinks these look excellent. Your LLM found an adversarial example. It's out of domain w.r.t. the RM's training data, in an undefined territory. Yes you can mitigate this by repeatedly adding these specific examples into the training set, but you'll find other adversarial examples next time around. For this reason, you can't even run RLHF for too many steps of optimization. You do a few hundred/thousand steps and then you have to call it because your optimization will start to game the RM. This is not RL like AlphaGo was.
And yet, RLHF is a net helpful step of building an LLM Assistant. I think there's a few subtle reasons but my favorite one to point to is that through it, the LLM Assistant benefits from the generator-discriminator gap. That is, for many problem types, it is a significantly easier task for a human labeler to select the best of few candidate answers, instead of writing the ideal answer from scratch. A good example is a prompt like "Generate a poem about paperclips" or something like that. An average human labeler will struggle to write a good poem from scratch as an SFT example, but they could select a good looking poem given a few candidates. So RLHF is a kind of way to benefit from this gap of "easiness" of human supervision. There's a few other reasons, e.g. RLHF is also helpful in mitigating hallucinations because if the RM is a strong enough model to catch the LLM making stuff up during training, it can learn to penalize this with a low reward, teaching the model an aversion to risking factual knowledge when it's not sure. But a satisfying treatment of hallucinations and their mitigations is a whole different post so I digress. All to say that RLHF *is* net useful, but it's not RL.
No production-grade *actual* RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. It's all fun and games in a closed, game-like environment like Go where the dynamics are constrained and the reward function is cheap to evaluate and impossible to game. But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python? Going towards this is not in principle impossible but it's also not trivial and it requires some creative thinking. But whoever convincingly cracks this problem will be able to run actual RL. The kind of RL that led to AlphaGo beating humans in Go. Except this LLM would have a real shot of beating humans in open-domain problem solving.