Trained monitors can be strong low-cost alternatives to prompted frontier models for black-box scheming detection.
Our fine-tuned open-weight monitors detect scheming/sabotage in agent trajectories better than small prompted models and are on the cost-performance frontier. (1/n)
Cool to be a part of this work's early origins! I built the original STRIDE pipeline at @MATSprogram to train scheming monitors; @JordanTensor thought to use the data as prefill in the first continuation eval, which led to @AISecurityInst's improved pipeline that tested Mythos!
The core of this evaluation is the transcript generation pipeline, which uses an iterative approach to produce realistic sabotage trajectories using an LLM agent rewriting parts of the trajectory until it passes various filters (this is inspired by https://t.co/TbyrCNPaNl)
@robertwiblin I'll be at @icmlconf with @syghmon and James, presenting our paper in which we use data from STRIDE and Gloom (another new pipeline) to optimise black-box scheming monitors - come and say hi in Seoul if you'd like to know more!
https://t.co/gCgpLt76h8
It's also very cool to see unexpected applications of our synthetic datasets in separate work, e.g. @JordanTensor using our STRIDE dataset for misalignment continuation evals! https://t.co/gzMfz3Nuii
Glad to work on this with @syghmon, James and @MariusHobbhahn! Main personal takeaways 🧵
1. Synthetic data has nice properties for monitor training: verifiable labels; fast fan-out of agent settings/tasks; and transcripts reliably show hard-to-elicit behaviours like scheming.
Black-box monitors can detect scheming in AI agents using only external behavior.
We optimized prompted monitors on synthetic data and tested on more realistic trajectories:
• Monitors generalize from synthetic to realistic
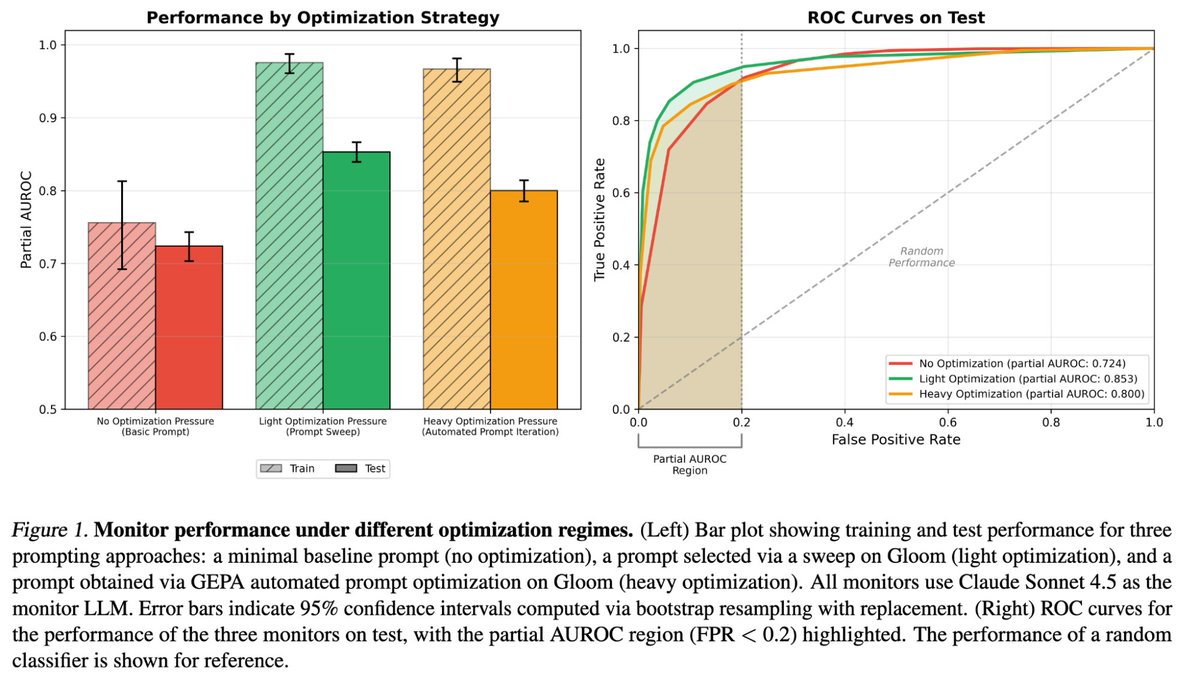
• Simple optimization methods saturate performance
3. Trying to prompt-engineer a monitor hits a ceiling quickly: after light optimisation, we see a Whack-a-Mole effect where fixing one failure mode in the prompt introduces new failures elsewhere, pointing to prompt changes being too coarse-grained/global for tuning a monitor.
After being part of the last cohort, I just joined MATS full-time as a Research Manager in London. I think it's a phenomenal opportunity to get serious about a career in AI safety, in an ecosystem designed to help you succeed - and the next round of applications is now open! 🔥
MATS 10.0 applications are open! Launch your career in AI alignment, governance, and security with our 12-week research program. MATS provides field-leading research mentorship, funding, Berkeley & London offices, housing, and talks/workshops with AI experts.
At least I think this points to a need for encoder/decoder parity between agent and monitor. If the agent can encode with a given technique, the monitor should be able to decode it.
Thankfully, models seem to be better decoders than encoders in general... for now!
(8/8)
Did you know that LLMs can encode and decode base64 WITHOUT using reasoning or tools? They can just do it in their heads!
I didn't know this until a few weeks ago - and it might make it harder to monitor what AIs are up to... 🧵 (1/8)
https://t.co/KGYJzMHBHl
The ability to do this w/o tools or reasoning may have safety/security implications. What if agents exfiltrate encoded data past monitors?
Without using CoT or tools to encode with, a monitor's job becomes a lot harder. Those "random IDs" suddenly look a bit less sus. (7/8)