Congrats to the @StainlessAPI team on the acquisition by Anthropic!
It took six customer intros and two months to get @RattrayAlex to take a meeting with us — but from that first 25-minute conversation in a cramped NYC office, the vision for API infrastructure was obvious.
Excited to have partnered with Alex, @laurenmhreeder, @JenniferHli, @calvinfo, and team. Huge milestone.
cc: @felicis
https://t.co/h7GSV6S5NJ
We're thrilled to announce that Stainless is joining @AnthropicAI! Stainless was founded to make software better for everyone, and we're honored to continue that mission on the Anthropic team. Check out the announcement blog post for more: https://t.co/guUmXn0OoS
We backed @StainlessAPI because @RattrayAlex believed SDKs deserved the same craft as the APIs they wrap. Anthropic believed it too. They've powered every official Claude SDK since day one. Congrats to the Stainless team on joining @AnthropicAI!
Anthropic is acquiring @stainlessapi, an SDK and MCP server platform that has powered every Anthropic SDK since the earliest days of our API.
Read more: https://t.co/ZQbsZKnicv
The @Felicis Forecast: the nine themes that we think will define what’s coming next. They don’t fit neatly into categories, but start to pop up everywhere once you notice them.
https://t.co/1A40KAJypY
1/ Today we launch the @Felicis Forecast. It's our map of the changes that defy neat categorization but matter most to what’s next. Where AI’s potential cuts across industries to collide with consumer, organizational, and socio-economic fault lines. Where the old structures have ruptured, and new ones are just coming into view.
Because even to people like us – generalists who’ve spent the past 20 years studying change – this moment feels different. Everything’s up for grabs. Rules, tidy bell curves, and comfortable patterns no longer apply.
So instead of following patterns, we forecast: 9 themes we just can’t get out of our heads, that seem to pop up everywhere once you notice them.
https://t.co/cQrirqWdBd
AI shipped to prod before its infra was built — first software wave that's done that.
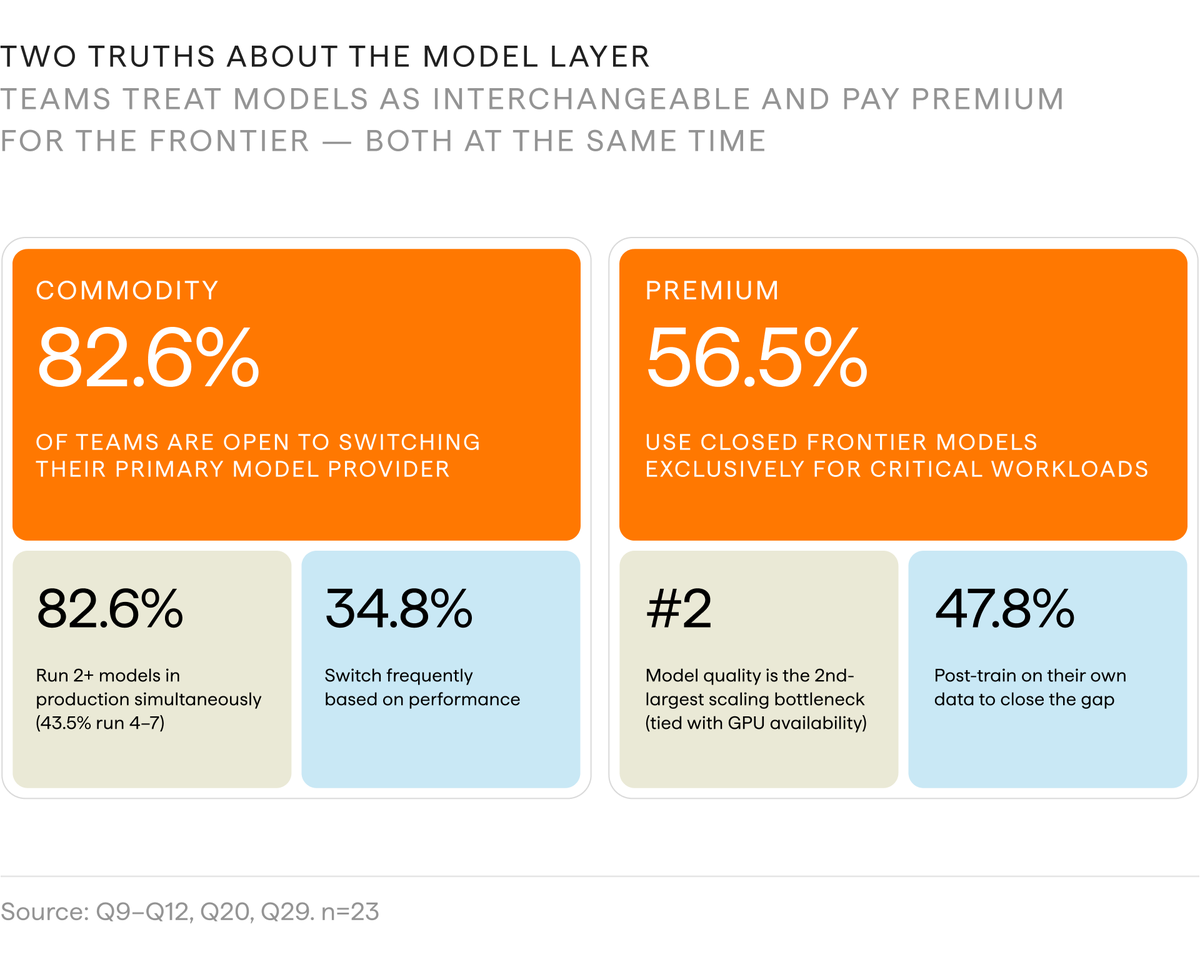
We surveyed 23 eng leaders. 70% doubled inference spend in 6 months. Half ship agents as core product. Most monitor it on home-built Grafana.
Building primitives? Reach out.
https://t.co/64ryBNWd53
Had a great chat with Harry Kim from @nvidia , @philipkiely from @baseten , and Arya Asemanfar from @SierraPlatform, for a salon dinner on long-running agents and inference.
We were joined by 20+ technical leaders from @Replit , @nvidia , @hippocraticai , @PrimeIntellect , @anyscalecompute , @togethercompute, @thinkymachines, @netflix , @tryramp , @MemGPT and more.
Consistent themes that emerged through several conversations:
- Nobody owns the agent harness yet. App teams are building it by default, inference platforms want to absorb it from below. Sentiment pointed to the application layer as its home — though some platforms are getting close.
- Evals are the precondition for everything else — model right-sizing, routing decisions, fine-tuning confidence. Nothing off the shelf is specific or good enough to work generally. Everyone is handling it in-house.
- The next wave for inference is real-time: video, audio, multimodal. Beyond that, inference-time compute and observability are the areas people are focused on.
- VR as a longer-term area of interest, when the technology can serve the capabilities consumers actually need.
Super energizing to chop it up with some of the best in the business! cc @felicis
Pancreatic cancer mRNA vaccine shows lasting results in an early trial. Scientists caution that more research is needed, but nearly all of the patients who responded to the personalized vaccine are still alive six years later.
https://t.co/13GBL8ujOV
We hosted Prof. Alyosha Efros (UC Berkeley) at @SkildAI! He didn't believe that robots could actually cook eggs reliably. :)
Tested back-to-back 5times without fail! One batch of scrambled eggs every ~2.5mins nonstop. The same model assembles a GPU on a server rack too.
Grateful to be working with @schwarzjn_ and his team at Thomson Reuters to help leverage their proprietary data to mid-train the world's best legal models!
Mid-training on domain specific data can massively improve specialized performance without sacrificing general capabilities. And because the mid-trained model understands the domain better, post-training becomes far more effective.
Check out our case study linked below to learn more. And if you want to leverage your own proprietary data to build strong, domain specific models where accuracy and reliability are key, please reach out to us @datologyai!
spent the last few weeks in the weeds asking AI engineers & CTOs on how they're actually building in 2026 – inference spend, GPU infra, model strategy, async workloads for @felicis' first AI dev survey.
some of the results are... not what we expected 👀
who should we be talking to?