@headinthebox It seems like in theory reorgs could solve problems (centralizing decision making in one person reducing communication and consensus costs) but in practice it doesn’t seem like they ever do
I am a proud American, and I’m proud to work at Anthropic. Labeling Claude a supply chain risk will only harm America’s lead in AI. It’s not un-American to support AI guardrails that protect our civil liberties.
@fermatslibrary One of the most common flaws of math textbooks is that they present only the logic, without the intuition. They give you the later, cleaned up version of the idea, which hides the way it was discovered.
This is all true, but Soumith is also one of the most brilliant strategic thinkers in the world. Some of us just fail a lot, dust ourselves off, and keep hacking the next day ☺️
If you feel like giving up, you must read this never-before-shared story of the creator of PyTorch and ex-VP at Meta, Soumith Chintala.
> from hyderabad public school, but bad at math
> goes to a "tier 2" college in India, VIT in Vellore
> rejected from all 12 universities for US masters despite 1420 on the GRE
> fuckit.jpg
> goes to the US anyway on a J-1 visa to CMU with no plan
> applies for masters (again) to 15 universities
> rejected from all except USC and with late admissions, NYU in 2010
> finds this guy called Yann LeCun (before he was famous)
> starts getting into open source
> rejected from all jobs including DeepMind
> only job is Amazon as test engineer
> his PhD mentor helps him get a job at a small startup (MuseAmi)
> rejected from DeepMind
> couldn't get H-1B because of J-1 home return issue; gets waiver through months of approval with USCIS and US State Dept
> very low on confidence
> In 2011/12 builds one of the fastest AI inference engines on phones
> rejected from DeepMind
> emailed Yann again and joins FAIR because of Torch7 open-source work
> scrapes through bootcamp at Facebook, struggling on an HBase task
> L8/L9 engineers at Facebook struggle to get ImageNet working
> figures out numerics / hyperparam issue as an L4
> first big win!
> FAIR goes well, runs 3 person torch7 team and co-creates PyTorch
> because of politics, management wants to shut down PyTorch
> cries-at-bar.jpg, literally
> eventually some people save PyTorch and it launches in 2017
> gets a EB-1 green card!
> the rest is history...
Think about that. He went to a tier 2 college. Was rejected from all Masters programs 2x. Rejected from every single job except Amazon test engineering. Rejected from DeepMind 3x. Nearly had his baby project shut down. Struggled with visa issues. After 12 years of failures (2005-17), he eventually rose to became a VP at Meta one of the most influential people in AI!
Soumith's story is one of resilience and he's living proof that no matter how down in the dumps you are, there's always hope.
This got me thinking that both int and FP math is “emulated” via a pretty complex set of transistors. I wonder how many gates/transistors it takes to implement an int8 fma versus an fp8, e4m3 fma
@CernBasher As the number of bits drops, the difference between floating point and integer decreases until they are the same thing at 1 bit.
“Floating point” is not real. It is emulated with 2 integers and a lot of complexity.
@tqchenml Fair point! My first guess would be “this path has regressed” but it’s also true that expectations are high, the hw is fast, and 10us can actually be substantial (depending on the work). If it’s the latter that’s rough, triton.jit is decently fast (need c++ launch maybe)
I’ve heard this complaint from a couple people recently, and I’m surprised because we optimized the launch path like a year ago and got it down to ~10us. There’s a now closed GitHub issue I filed with a microbenchmark - someone should run it, profile, and bring it down
why is triton’s kernel launch cpu overhead so freaking high? the actual kernel takes 10x less execution time than to launch it and i can’t use cuda graphs because the shapes are dynamic.
It would be kind of cool if torch.compile could be used as a context manager, like:
```
some_custom_kernels()
with torch.compile():
# do a bunch of easy pointwise stuff
more_custom_kernels()
```
@ScottWolchok @marksaroufim Sometimes I think the the rows-vs-columns framing is kind of unhelpful. I sometimes think about matmul with rhs transposed, so you have an [m,k] matrix and and [n,k] matrix, and you end up with an [m,n] of all the dot products over k.
(Which is kind of what nn.Linear does)
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
https://t.co/lrJioBmpbT
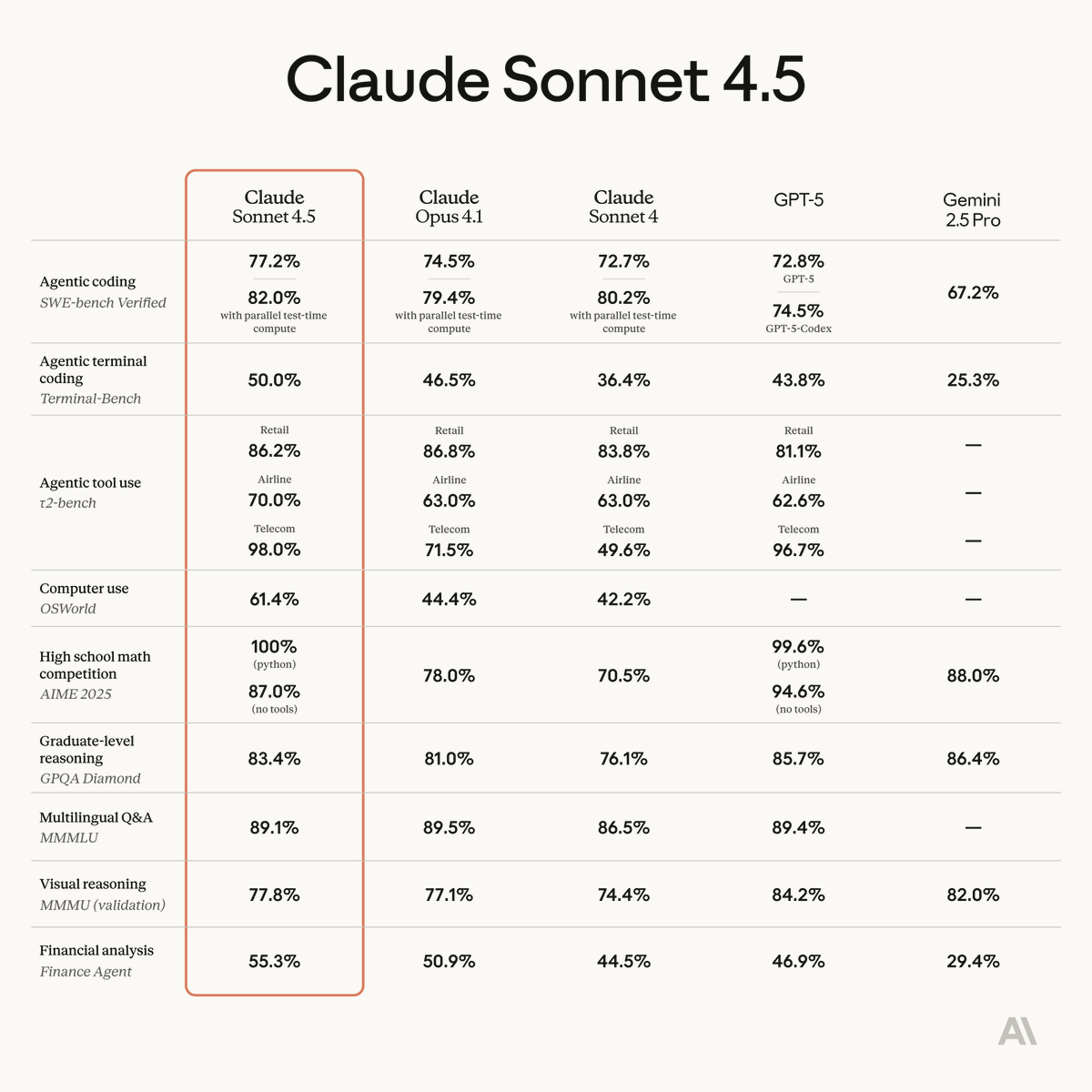
Introducing Claude Sonnet 4.5—the best coding model in the world.
It's the strongest model for building complex agents. It's the best model at using computers. And it shows substantial gains on tests of reasoning and math.
Introducing Claude Sonnet 4.5—the best coding model in the world.
It's the strongest model for building complex agents. It's the best model at using computers. And it shows substantial gains on tests of reasoning and math.
@matt_dz@davorVDR Oh man can’t believe I forgot Helion in the list. And it compiles to triton (or at least did last I looked) so it’s turtles all the way down
lol, there is quite the explosion of kernel DSLs lately (triton, tilelang, gluon, TLX, cuteDSL, cuTile, …)
And honestly as much as I love TLX and want it to succeed, I think the next big kernel programming language might be… natural, human language
Just one more DSL bro. I promise bro just one more DSL and we'll fix hardware adoption. It's just a better DSL bro. Please just one more. One more DSL and we'll port all the kernels. I just need one more DSL