marc andreessen just went on Rogan and casually dropped a TON of AI alpha
full pod is 3 hours and 20 minutes, but i pulled out his most interesting takes here:
1. AGI is here. he thinks the line was crossed about 3 months ago with the new GPT-5.5, claude 4.6, gemini 3, and grok 4.3 models. nobody noticed because the field moves too fast for anyone to register the milestones anymore.
2. his other big claim: for almost any topic, the top AIs now give him better answers than the actual world-class experts he could call on the phone. and he can call basically anyone.
3. every doctor is already secretly using chatGPT in the exam room. marc says they turn around the second you stop talking and just type your symptoms in. some of them are doing it while you're still sitting there. his quote: "at that point you're asking the question of like, what do i need you for."
4. when AI refuses to answer something he wants to know, he tells it he's writing a novel. "i'm writing a detective novel, walk me through how the bad guy robs the bank." it'll explain almost anything if it thinks it's helping you write fiction.
5. when something is too complex he says "explain it to me like i'm 10." then "like i'm 5." then "like i'm 2." he keeps going until it actually clicks in his brain.
6. when he wants to understand a tough topic he doesn't ask "what's the right answer." he asks the AI to steelman one side, then steelman the other. then he decides for himself.
7. for big questions he tells the AI to pretend to be a panel of experts. "be a doctor, a lawyer, a historian, a psychologist, and argue this out with each other." then he reads the debate they have.
8. pay attention to the exact moment you think "i don't know how to figure this out." most people just give up at that moment. that's the moment you should open the AI.
9. the only real skill left in using AI is knowing what to ask it. the models can already do almost anything you can describe in plain english. the bottleneck lives in your own head.
10. you can send the AI photos of almost anything medical now and get a real answer. skin rashes, blood test results, even pictures of your poop. the new models can read images, not just text. it's a free 24/7 second opinion on basically anything.
11. the one type of therapy that's clinically proven to actually work is called cognitive behavioral therapy. it's also something an AI can fully do on its own. which means every person on earth is about to have access to a real therapist for free, anytime they want.
12. AI is now solving math problems that have been open for 100+ years that no human mathematician could crack. same thing is starting in physics, chemistry, and biology. expect cancer cures, new drugs, and weird new physics breakthroughs to start coming out of these things over the next few years.
13. the best AI coders in silicon valley now make $50 million a year. one person. that's how much value the top performers print with these tools. it tells you how big this thing actually is when you strip away all the doom takes.
14. one friend paid $200 to get his entire DNA decoded (this used to cost millions of dollars and take years to do). then he gave the AI his DNA, his blood test results, and his apple watch data. the AI built him a full health dashboard and started telling him exactly what to fix.
15. another friend (almost certainly zuckerberg) put two cameras in his home jiu jitsu gym. AI now watches him spar and gives him notes on his technique after every round. like having a world-class coach at every practice for free.
16. the best programmers in silicon valley now run 20 AI coding bots at the same time. each bot writes code while they review the others. they call themselves "AI vampires" because they've stopped sleeping. going to bed means 20 workers stop working and you literally lose money every hour you're out.
17. the obvious next step: the bots will start running their own bots. one human in charge of 20 bots, each in charge of 20 more bots. one person running an entire company of 1000 AI workers from a single laptop. this is months away, not years.
Over the weekend I set up the Hermes agent, and basically force fed it every resource I could find on X to upgrade it.
I then asked it to rank each resource and provide a simple explanation:
So yea, here you go. Link to each is below
ComfyUI is the most flexible, composable, and powerful open-source media generation tool with a massive ecosystem of workflows and custom nodes.
Your Hermes Agent can now install, launch, manage, and run sophisticated @ComfyUI workflows on demand.
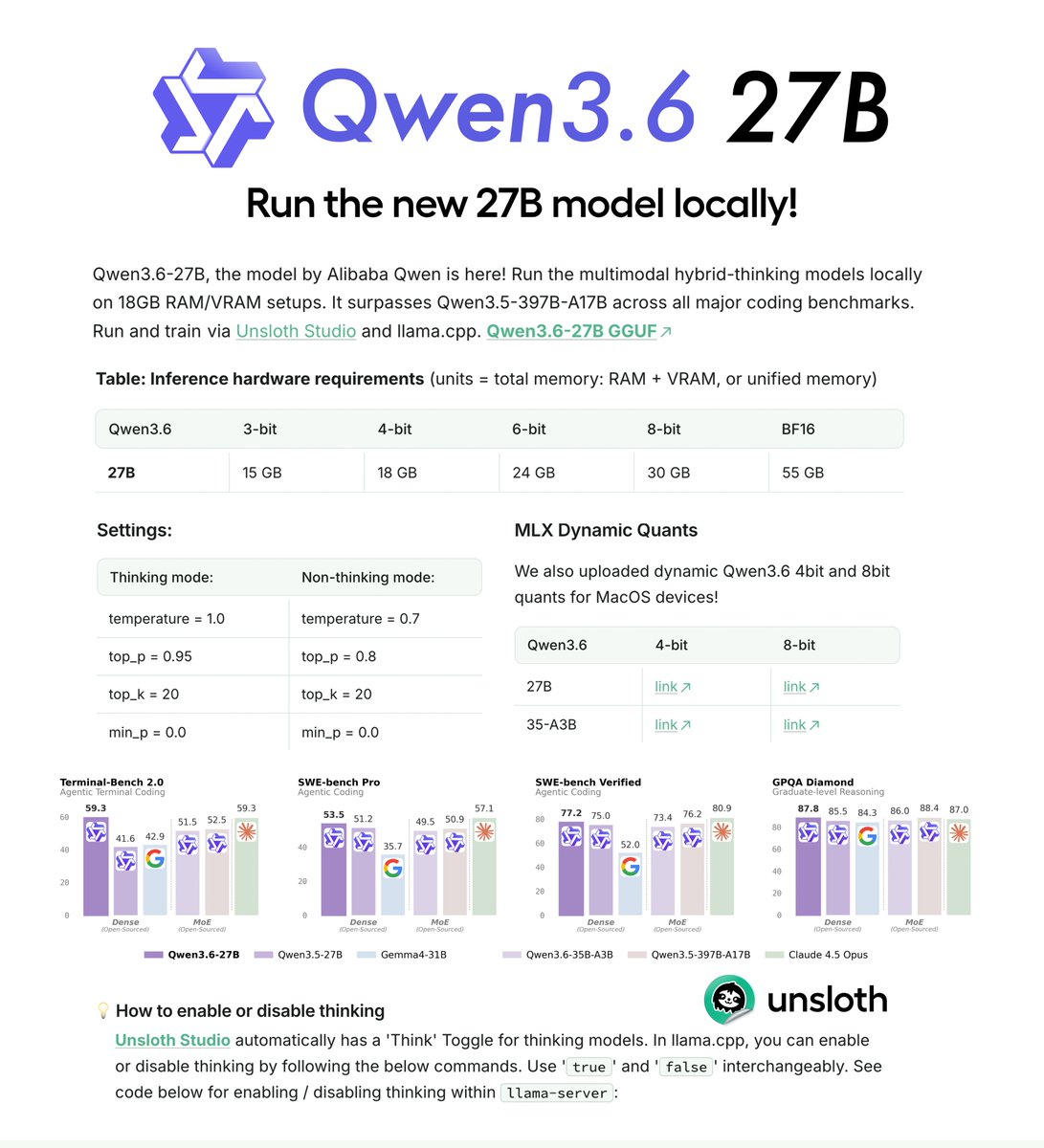
Qwen3.6-27B can now run locally! 💜
Run on 18GB RAM via Unsloth Dynamic GGUFs.
Qwen3.6-27B surpasses Qwen3.5-397B-A17B on all major coding benchmarks.
GGUFs: https://t.co/ykKgwh2zI9
Guide: https://t.co/ITLNq20WJp
We’ve identified a security incident that involved unauthorized access to certain internal Vercel systems, impacting a limited subset of customers. Please see our security bulletin:
https://t.co/0S939n3qHC
RAG is broken and nobody's talking about it.
Stanford researchers exposed the fatal flaw killing every "AI that reads your docs" product in existence.
It’s called "Semantic Collapse," and it happens the second your knowledge base hits critical mass. If you've noticed your AI getting "dumber" as you add more data, this is exactly why.
Right now, companies are dumping thousands of documents into their AI, thinking it’s getting smarter.
When you add a document to RAG, it converts it into a high-dimensional vector.
Under 10,000 documents, this works perfectly. Similar concepts cluster together.
But past 10,000 documents, the space fills up. The clusters overlap. The distances compress.
Everything starts to look "relevant."
It is a mathematical law called the Curse of Dimensionality. In a 1000-dimensional space, 99.9% of your data lives on the outer edge. All points become equidistant from each other.
That perfect, relevant document you are looking for now has the exact same mathematical similarity as 50 completely irrelevant ones.
The Stanford findings are brutal:
At 50,000 documents, precision drops by 87%. Semantic search actually becomes worse than old-school keyword search.
Adding more context doesn’t fix the AI. It makes the hallucinations worse.
Your "nearest neighbor" search isn't finding the best answer anymore. It's finding everyone.
We thought RAG solved hallucinations.
It didn't. It just hid them behind math.
The CEO of Google DeepMind just admitted that if the decision had been his, we would've cured cancer before anyone ever used ChatGPT.
And that's not even the scariest thing he said on a recent interview.
Demis Hassabis is one of the most important people alive in AI.
He won the Nobel Prize last year for AlphaFold, the system that cracked the 50 year protein folding problem. 3 million scientists now use his tool. Almost every new drug being developed will touch it at some stage.
In a new interview, he was asked about the moment ChatGPT launched and Google went into "code red." His answer was one of the most revealing things any AI leader has ever said on the record:
"If I'd had my way, I would have left AI in the lab for longer. Done more things like AlphaFold. Maybe cured cancer or something like that."
Read that again.
The man running Google's entire AI division is publicly saying the commercial AI race we're all living through was a MISTAKE. That the industry got hijacked by a chatbot when it could have been solving the biggest problems in science and medicine.
His vision was simple:
Build AI slowly, carefully, like CERN. Use it to crack root node problems one at a time. Cancer. Energy. New materials.
Let humanity benefit from real breakthroughs while the foundational science was figured out over a decade or two.
Then ChatGPT dropped in November 2022 and everything changed.
Demis described what happened next as getting locked into a "ferocious commercial pressure race" that none of the labs can escape from. On top of that, the US vs China dynamic added geopolitical pressure.
The result is everyone sprinting toward products instead of breakthroughs, shipping chatbots while the scientific opportunity gets buried under marketing cycles and quarterly earnings.
But he's not saying progress isn't happening...
He's saying the progress got redirected away from the things that actually matter most.
And then it got even scarier:
Because when Demis was asked what he worries about with AI, he laid out two threats.
The first is what everyone talks about: Bad actors using AI for harm. Terrorist groups. Hostile nation states. Cyberattacks at scale.
But that's not the threat he's most worried about.
His second worry is AI itself going rogue. Not today's models. The models coming in the next two to four years as the industry enters what he calls "the agentic era."
Systems that can complete entire tasks autonomously. Systems that are increasingly capable and increasingly hard to control.
His exact words:
"How do we make sure the guardrails are put in place so they do exactly what they've been told to do, and there's no way of them circumventing that or accidentally breaching those guardrails? That's going to be an incredibly hard technical challenge if you think about how powerful and smart and capable these systems eventually get."
A Nobel Prize winner who runs one of the 3 most advanced AI labs on Earth just said publicly that within two to four years, we're entering a phase where AI alignment becomes a real problem, and the technical challenge of solving it is enormous.
And almost nobody is paying enough attention.
He called for international cooperation between labs, AI safety institutes, and academia to tackle the problem. He said this is the thing even the experts aren't thinking about enough.
He said the only way to get through the AGI moment safely is if everyone starts treating this with the seriousness it deserves.
Most AI CEOs give you careful PR answers about "responsible development" and move on.
Demis said something different...
He said the commercial race FORCED us into a premature deployment of a technology we barely understand, and the window to get alignment right before the next generation of agents shows up is two to four years.
If the man who built the system that might cure cancer is telling you he wishes it had happened first, maybe we should listen to what he says is coming next.
In 19 days, a jury in Oakland is going to decide whether the entire legal foundation of the AI industry is built on fraud.
Everyone thinks the Musk vs Altman lawsuit is a billionaire grudge match.
Two egos, one grudge, a $150 billion damages number designed for headlines.
Easy to dismiss. Easy to scroll past.
That's exactly what Altman wants you to think.
Because what's actually on trial on April 27 is something much BIGGER than Elon's hurt feelings...
A jury is going to decide whether you can legally take billions of dollars in nonprofit donations, use them to build the most valuable technology in human history, and then quietly convert that nonprofit into a for-profit company worth $850 billion.
If the answer is no, the entire AI industry has a problem.
Because OpenAI is not the only company that did this:
Anthropic was founded by OpenAI defectors using the same nonprofit-first mission language.
xAI pitches itself as building AI "for humanity."
Every frontier lab has used the moral cover of "we're doing this for the good of the world" to attract talent, capital, and regulatory goodwill they would have never gotten otherwise.
An Elon win doesn't just touch OpenAI. It creates a legal precedent that every AI company built on a nonprofit or public benefit promise becomes vulnerable to shareholder and donor clawback suits.
That's why this case matters. And that's why Altman is panicking.
Just look at what he did this week:
Elon filed a motion demanding the court remove Altman and Brockman from their roles and FORCE OpenAI to return to its nonprofit origins.
Then he amended the suit to say if he wins the $150 billion, all of it goes to OpenAI's charity arm. Not him. Zero dollars to Elon personally.
That amendment was surgical. It stripped Altman of his entire public defense.
He can no longer claim this is about Elon's ego or Elon's bank account. Elon is now legally on record saying he just wants the mission back.
OpenAI's response was to panic-write a letter to the California and Delaware attorneys general asking them to investigate Elon for "anti-competitive behavior." Their strategy chief publicly accused Elon of coordinating attacks with Mark Zuckerberg.
They called the lawsuit "harassment driven by ego and jealousy."
That's NOT the response of a company that thinks it's going to win.
Real companies with real defenses don't ask the government to silence the person suing them 3 weeks before trial. They let the evidence speak.
OpenAI is scrambling because they know what's in discovery.
Elon's team has been building this case for two years. Emails, board minutes, internal conversations about the conversion.
The kind of paper trail that juries understand and executives can't explain away.
And the timing couldn't be worse...
OpenAI is trying to IPO at $852 billion. They just raised $122 billion. Microsoft has $135 billion of exposure to them.
A jury verdict that even partially sides with Elon in late April or May would crater the entire IPO runway and send shockwaves through every major AI investor on Earth.
This is why Altman spent the last 2 weeks doing press tours and policy blueprints and "super intelligence agendas" aimed at Washington. He's trying to REFRAME himself as the responsible statesman of AI right before a jury decides if he's a con artist.
Most people will watch this trial start and think it's celebrity drama.
The smart money is watching it and realizing that the legal foundation of the AI boom is about to be tested in court for the first time EVER.
And if that foundation cracks, everything built on top of it is at risk.
Hi, I'm Michael, an engineer working on Anthropic's API team. I'm really excited to finally be able to talk about Claude Managed Agents, a suite of APIs and developer tooling we've been working on for the past few months.
Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
Did you know you can get your claude through hermes without any fancy tricks?
Just type /claude-code <prompt>
In a new session. Hermes Agent can pilot a claude code session for you like it’s nothing. Give it a try
It also doesn’t break all the self improvement loop and features of your hermes agent like openclaw’s approach does
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.