Are AI scientists already better than human researchers?
We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts.
Main finding: LLM ideas result in worse projects than human ideas.
@lixin4ever Thank you for the release! One question out of curiosity: What is the motivation behind training LLM for SEA? I know that some languages like malay and indo share some similarities but they are generally disconnected (different script, morphology, culture, etc.)
🚨 New paper on Subword Tokenization 🚨
- umLabeller, a new tool, classifies subword tokenization into morph 🤹 or alien 👽
- alien tokenization 🛸 leads to poorer generalizations than morphological tokenization for 3 downstream tasks. https://t.co/gsfLcb0blF (1/7)
"In other words, the modification are so simple that there is a rule to determine the label (e.g., adding 'X allegedly did Y' doe not entail 'X did Y'). "
And yet the massively pretrained models do not capture this! I find it interesting and remarkable.
11/ Please have a look at the paper if you find this interesting.
Big thanks to my co-author and supervisors: @YuliaOtmakhova, @karinv, Trevor, @eltimster. Finally, I will be at NAACL (my first in-person conference after almost finishing my PhD). See you in Mexico!
Paper accepted to NAACL 2024 main conference.
arxiv: https://t.co/7fyRBZSz7k
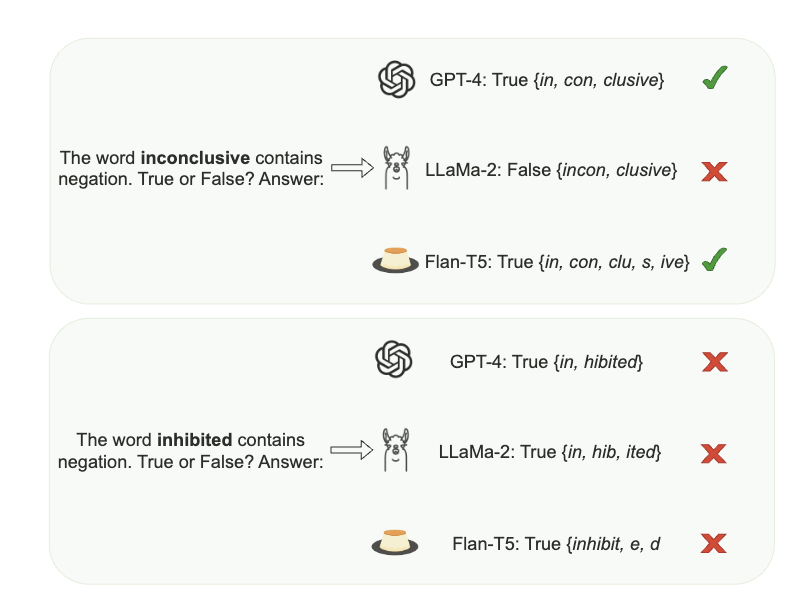
In this work, we explore the interaction between two bottlenecks of LLMs: negation and tokenization (quoting @karpathy: "tokenization is the root of suffering").
10/ We see that models could clearly understand negation despite incorrect tokenization. This could be an interesting phenomenon to look at when discovering LLM interpretability. Also, as English is poor in morphology, we are eager to extend this analysis to other languages.