If you've implemented speculative decoding, you've run into this: your speculator predicts the distribution correctly and still gets rejected.
Let’s take an example:
"The random number from 1 to 10 inclusive is"
Ideal LLM: uniform 1/10 across all numbers.
Good speculator: same distribution.
In that situation, the naive scheme takes a random number from the speculator, then takes another random number from an LLM and can only accept the bonus token in 1/10 cases when they happen to match.
We should be able to always take its guess without the loss of generation quality.
The fix is straightforward.
Sample from both the speculator and the LLM using the same seed via the Gumbel-max trick.
Shared randomness means shared outcome when distributions match.
100% acceptance rate in this case. Near-optimal in practice.
We shipped this in https://t.co/sEuiM8hbiK
Full kernel implementation: https://t.co/JeS5IRN0Ox
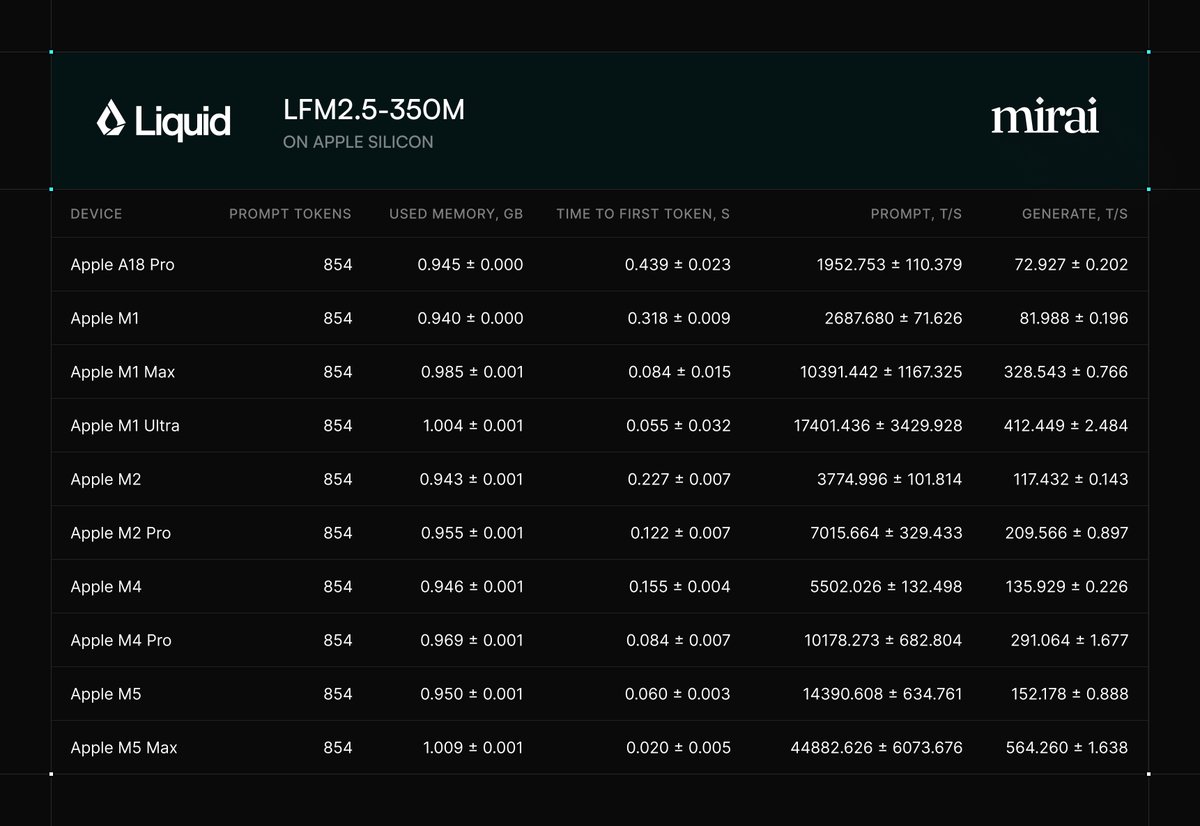
LFM2.5-350M is now available on Mirai.
@liquidai smallest model outperforms Qwen3.5-0.8B on reasoning and agentic tool use.
Running on Mirai in full precision, it exceeds 70 tokens/second on iPhone.
LLM activations have outliers. A few channels spike 100x past the rest, every token. Standard INT8 wastes almost all its precision covering them.
The fix: rotate the weight space so outliers disappear before quantization. It's why QuaRot and TurboQuant work.
Here's how we implemented it:
https://t.co/2jpHCiwed4
Apple just released its programming guide for Metal Performance Primitives, and they suggest using Morton codes for tiled GEMM, but why?
In computer graphics, you use such space-filling curves all of the time
It makes objects that are close in space to be close in memory
There are several reasons, but one of them is that you get better cache locality, meaning less expensive reads from the device memory
This is exactly why it’s appealing for GEMM too - you have a lot of overlapping memory reads between the tiles
Morton schedules tiles in compact square patches, minimizing the working set that fits in last-level cache simultaneously, so nearby threadgroups are more likely to reuse the data they share
(1/n) I recently joined @trymirai, where we are working on LLM inference targeting Apple Silicon. Lately I've been digging into quantization.
LLM inference is mostly memory-bound. The byte/FLOP ratio is high enough that a lot of the machine's time goes to moving data around instead of doing compute. Quantization helps with that in general, but on Apple Silicon there's an extra payoff: the GPU has a fast W8A8 path. If both weights and activations are INT8, you can use that path for prefill and speculative-decoding verification.
Weights are easy since they're static and can be quantized offline. Activations are where the real pain starts.
We are doing really cool hard tech at @trymirai, but until recently our social media feeds were full of linkedinish cringe. We decided to fix it and share more technial content
I am currently working on our quantization pipeline, so here is a thread about LLM quantization
We achieve this by sampling from both the speculator and the LLM via the Gumbel-max trick, sharing the same seed. This will achieve a 100% acceptance rate in the toy example above, and a near-optimal acceptance rate in more complicated real-world cases, while being much simpler than the mainstream rejection-sampling-like algorithm that most other inference engines use.
https://t.co/nEnlyBkp2d
How to improve acceptance rate in speculative decoding?
Inference of LLMs requires reading large amounts of data from memory while doing relatively little compute with that data, which means that compute is significantly underutilized.
https://t.co/sEuiM8hJ8i can turn that underutilized compute into higher decoding throughput by trying to cheaply guess the next token, computing the next token for both the current sequence and current sequence + guessed next token, and then, if the next token matches our guess, we can take both at once, doubling the throughput. This is the simplest form of speculative decoding.
The simplest way to improve upon this is by realizing that the LLM is often unsure about what the next token should be. Let's take an example: "The random number from 1 to 10 inclusive is", an idealized LLM outputs uniform 1/10 probability for every number 1–10. A good speculator would output the same. In that situation, the naive scheme takes a random number from the speculator, then takes another random number from an LLM and can only accept the bonus token in 1/10 cases when they happen to match. But here the speculator exactly predicted the LLM's distribution. We should be able to always take its guess without the loss of generation quality.
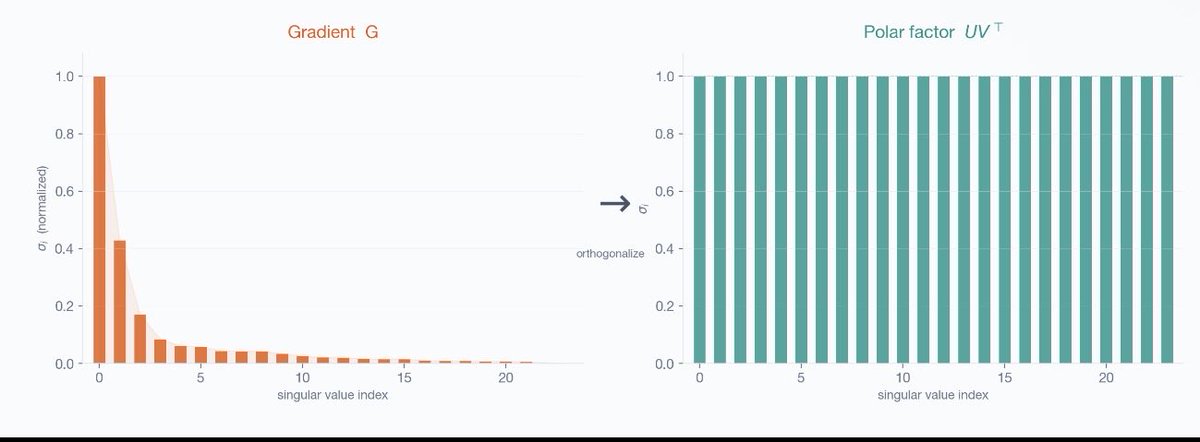
Why does Muon beat Adam for training quantized networks?
It comes down to what each optimizer treats as "distance" in weight space.
Adam treats a weight matrix as a flat vector of numbers. Muon treats it as a linear map — and measures change by how much the input-output mapping moved.
gradient G has SVD G = U Sigma V^T. Muon's update is just U V^T. keep the directions, throw away the magnitudes
1/ Apple shipped Metal Performance Primitives — a GPU matmul API built on cooperative_tensor. If you look at Apple's open-source code for an example of how to use MPP, you'll find a hardcoded M5 memory layout.
We tend to think AI quality = model quality.
Bigger model → better answers.
However, for local inference, performance depends on
model + hardware + execution together.
The same model can be much more or less efficient depending on how it’s run on-device.
That means local AI isn’t just a model problem. It’s a systems problem. Of how efficiently can your model run on a real device.
That’s the shift.
Mirai is building the on-device inference layer,
the runtime between hardware and models, turning local compute into predictable, efficient, production-ready intelligence.
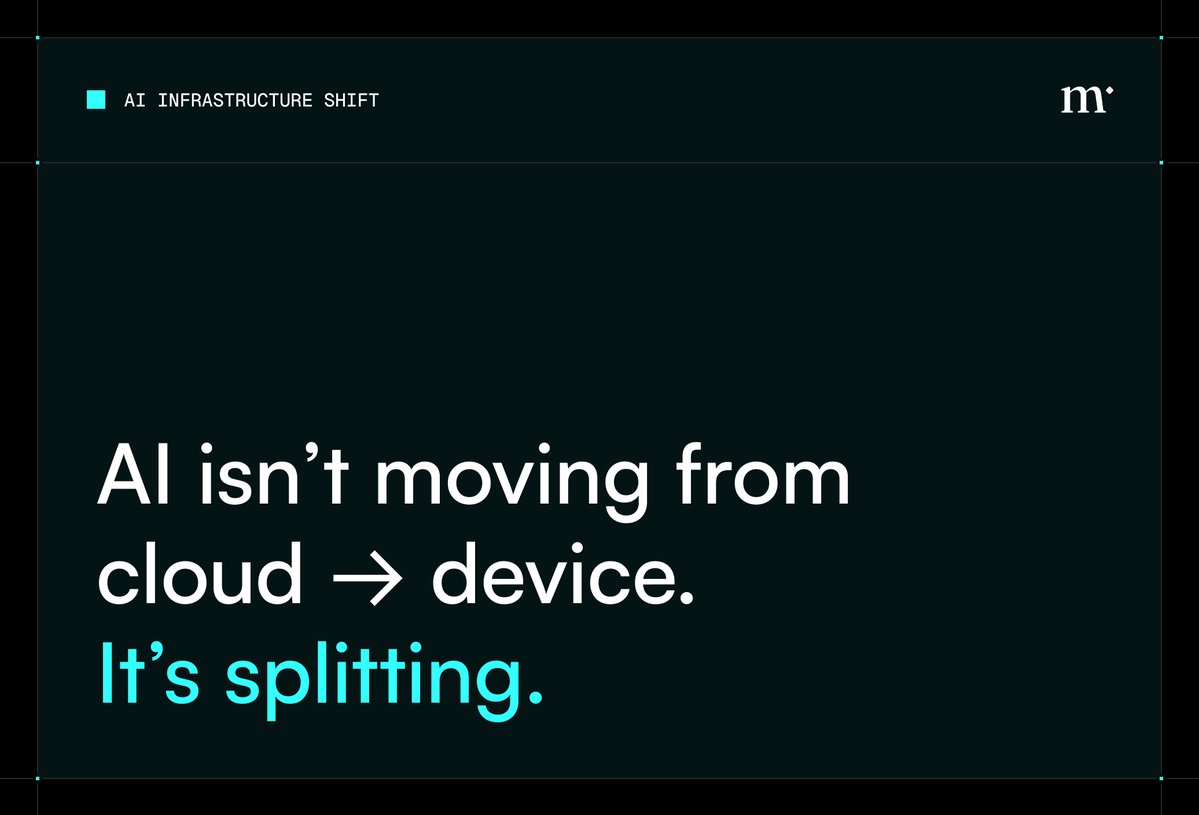
AI isn’t moving from cloud → device.
It’s splitting.
Local models already handle a share of real-world queries, while frontier models remain essential for complex tasks.
It’s redistribution.
Simple workloads move closer to the user. Complex workloads stay in the cloud. The system becomes hybrid by default.
Once part of your AI stack runs locally:
• latency drops
• costs collapse
• privacy improves
• reliability increases
Mirai exists for this new architecture.
Where intelligence is split across layers,
but feels like one system.
Personal AI should run on your personal devices. So, we built OpenJarvis: a personal AI that lives, learns, and works on-device.
Try it today and top the OpenJarvis Leaderboard for a chance to win a Mac Mini!
Collab w/ @Avanika15, John Hennessy, @HazyResearch, and @Azaliamirh. Details in thread.
The biggest constraint in AI isn’t models. It’s energy ⚡
Inference demand is exploding:
• Google Cloud saw a 1300× increase in token processing.
• NVIDIA reported 10× year-over-year growth
But data centers take years to build and require massive energy infrastructure.
So the real question isn’t just:
“How do we build bigger models?”
It’s:
“How do we turn energy into intelligence more efficiently?”
That’s why intelligence-per-watt matters.
Just as performance-per-watt moved computing from mainframes to PCs, intelligence-per-watt may move AI from data centers to devices.
Mirai is building for that transition.