💡 You get 2,000 free Qwen Code runs every day!
Run this one simple command:
npx @qwen-code/qwen-code@latest
Hit Enter, and that’s it!
🚀 Now with Qwen OAuth support — super easy to use.
Try it now and supercharge your vibe code! 💻⚡
Github:https://t.co/8ITh20WTbV
I am alarmed by the proposed cuts to U.S. funding for basic research, and the impact this would have for U.S. competitiveness in AI and other areas. Funding research that is openly shared benefits the whole world, but the nation it benefits most is the one where the research is done.
If not for funding for my early work in deep learning from the National Science Foundation (NSF) and Defense Advanced Research Projects Agency (DARPA), which disburse a good deal of U.S. research funding, I would not have discovered lessons about scaling that led me to pitch starting Google Brain to scale up deep learning. I am worried that cuts to funding for basic science will lead the U.S. — and also the world — to miss out on the next set of ideas.
In fact, such funding benefits the U.S. more than any other nation. Scientific research brings the greatest benefit to the country where the work happens because (i) the new knowledge diffuses fastest within that country, and (ii) the process of doing research creates new talent for that nation.
Why does most innovation in generative AI still happen in Silicon Valley? Because two teams based in this area — Google Brain, which invented the transformer network, and OpenAI, which scaled it up — did a lot of the early work. Subsequently, team members moved to other nearby businesses, started competitors, or worked with local universities. Further, local social networks rapidly diffused the knowledge through casual coffee meetings, local conferences, and even children’s play dates, where parents of like-aged kids meet and discuss technical ideas. In this way, the knowledge spread faster within Silicon Valley than to other geographies.
In a similar vein, research done in the U.S. diffuses to others in the U.S. much faster than to other geographic areas. This is particularly true when the research is openly shared through papers and/or open source: If researchers have permission to talk about an idea, they can share much more information, such as tips and tricks for how to really make an algorithm work, more quickly. It also lets others figure out faster who can answer their questions. Diffusion of knowledge created in academic environments is especially fast. Academia tends to be completely open, and students and professors, unlike employees of many companies, have full permission to talk about their work.
Thus funding basic research in the U.S. benefits the U.S. most, and also benefits our allies. It is true that openness benefits our adversaries, too. But as a subcommittee of the U.S. House of Representatives committee on science, space, and technology points out, “... open sharing of fundamental research is [not] without risk. Rather, ... openness in research is so important to competitiveness and security that it warrants the risk that adversaries may benefit from scientific openness as well.”
Further, generative AI is evolving so rapidly that staying on the cutting edge is what’s really critical. For example, the fact that many teams can now train a model with GPT-3.5- or even GPT-4-level capability does not seem to be hurting OpenAI much, which is busy growing its business by developing the cutting-edge o4, Codex, GPT-4.1, and so on. Those who invent a technology get to commercialize it first, and in a fast-moving world, the cutting-edge technology is what’s most valuable. Some studies (link in original post, below) also show how knowledge diffuses locally much faster than globally.
China was decisively behind the U.S. in generative AI when ChatGPT was first launched in 2022. However, China’s tech ecosystem is very open internally, and this has helped it to catch up over the past two years:
- There is ample funding for open academic research in China.
- China’s businesses such as DeepSeek and Alibaba have released cutting-edge, open-weights models. This openness at the corporate level accelerates diffusion of knowledge.
- China’s labor laws make non-compete agreements (which stop an employee from jumping ship to a competitor) relatively hard to enforce, and the work culture supports significant idea sharing among employees of different companies; this has made circulation of ideas relatively efficient.
While there’s also much about China that I would not want the U.S. to emulate, the openness of its tech ecosystem has helped it accelerate.
In 1945, Vannevar Bush’s landmark report “Science, The Endless Frontier” laid down key principles for public funding of U.S. research and talent development. Those principles enabled the U.S. to dominate scientific progress for decades. U.S. federal funding for science created numerous breakthroughs that have benefited the U.S. tremendously, and also the world, while training generations of domestic scientists, as well as immigrants who likewise benefit the U.S.
The good news is that this playbook is now well known. I hope many more nations will imitate it and invest heavily in science and talent. And I hope that, having pioneered this very successful model, the U.S. will not pull back from it by enacting drastic cuts to funding scientific research.
[Original post, with links: https://t.co/JR3x4O1iVr ]
most common neural net mistakes: 1) you didn't try to overfit a single batch first. 2) you forgot to toggle train/eval mode for the net. 3) you forgot to .zero_grad() (in pytorch) before .backward(). 4) you passed softmaxed outputs to a loss that expects raw logits. ; others? :)
Sir @irfan_malikx
Just completed Andrew Ng's Deep Learning Specialization on Coursera! 🚀 Learned so much about neural networks, CNNs, and deep learning techniques. Excited to apply this knowledge to real-world AI challenges. #DeepLearning#AI#MachineLearning#Coursera"
New short course on LLMOps!
LLMOps (large language model operations) is a rapidly developing field that takes ideas from MLOps (machine learning operations) and specializes them to building and deploying LLM-based applications. In this course, taught by @googlecloud's Erwin Huizenga, you'll learn to use automation to make building, tuning and deploying an LLM-based application less manual and more efficient.
You'll learn how to:
- Apply supervised fine-tuning to tune an LLM to a specific task
- Automate and orchestrate LLM-tuning and deployment by customizing a pre-built tuning pipeline
- Apply best practices for preparing training data for supervised fine-tuning of an LLM
- Create an LLMOps workflow you can adapt to other LLM-tuning jobs
This course doesn't assume any prior MLOps or LLMOps experience. Sign up here to learn about this emerging field! https://t.co/UlDEbI0DbK
Remember exercise pages from textbooks? Large-scale collection of these across all realms of knowledge now moves billions of dollars. Textbooks written primarily for LLMs, compressed to weights, emergent solutions served to humans, or (over time) directly enacted for automation.
Happy to announce that the lectures for our Free Artificial Intelligence Advance Course are resuming from Tonight!
Be ready for the Live Lecture, Tonight at 7:30 p.m.
#AIwithIrfanMalik#hopetoskill
Data is everywhere, but what does it all mean?
Learn how to build your own AI project, like a chatbot here ➡️ https://t.co/OQSFr6oHGx
Dive Deeper into 4 different data science roles to excel here ➡️https://t.co/sN1ZVHdGuP
#Dataterms#datascience#data
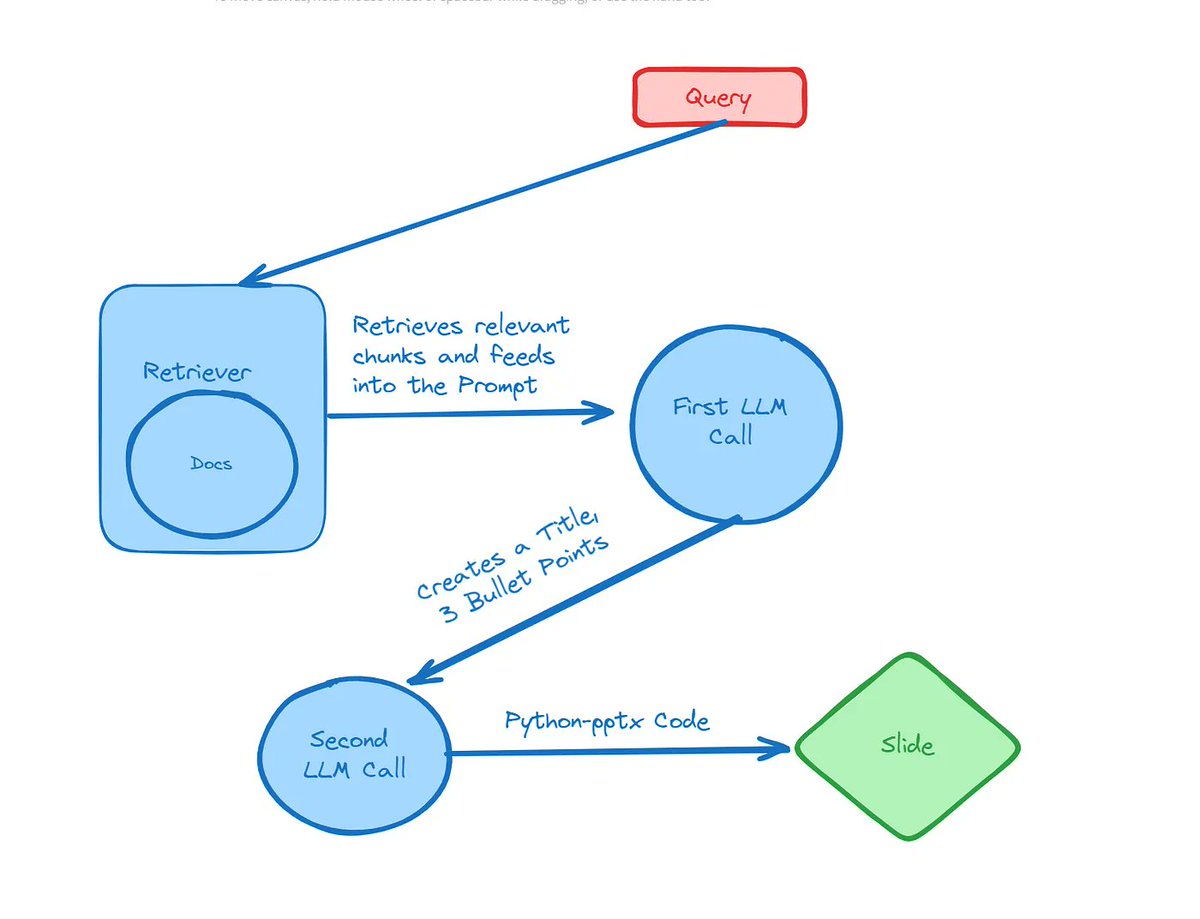
Generating PowerPoints with Llama 3 🦙📊
This is an awesome article by @naivebaesian on how to use @llama_index to build a Llama3 RAG pipeline that doesn’t just answer questions, but can generate a Powerpoint slide deck.
Python-pptx is a neat library to programmatically create Powerpoint presentations, and the articles shows how to use @llama_index structured extraction to prompt LLMs to write python-pptx code.
https://t.co/r1l661B6Bv
Announcing AlphaFold 3: our state-of-the-art AI model for predicting the structure and interactions of all life’s molecules. 🧬
Here’s how we built it with @IsomorphicLabs and what it means for biology. 🧵 https://t.co/gjw6Ip4F2M