Spotify's Chief Architect just showed how they ship 4,5K deployments /day with Claude at Anthropic stage
27-minutes. free. By #1 music app dev
"More than 99% of our engineers use AI coding tools. Adoption took off after Opus 4.5"
Worth more than any $500 vibe-coding course.
We killed RAG, We killed Sandboxes, We gave our Assistant a virtual filesystem and dropped latency to 10ms
- Our Assistant was a glorified search bar.
- The moment it had to cross reference multiple searches it fell apart
- Sandboxes couldn't work
- We went virtual
Traditional RAG only sends relevant chunks of a document. Never a full doc. Answers in docs span multiple pages: eg
- Product Overview page
- Configuration page
- API reference page.
With rag the model can only see pieces and chunks of a page but never the full doc a user sees. This gap lead to many responses feeling half baked
We first tried putting the agent in a sandbox and found responses to be better, however sandbox startup time was ~46 seconds and would cost us at least $70k/year. Sandboxes didn't work.
We built a virtual filesystem that translates UNIX commands into queries against our database. We call it Chroma FS. Output quality remained the same while completely removing a sandbox.
What we realized was the agent doesn't need a real sandbox. It just needs to think its in a sandbox.
ChromaFs now powers the docs assistant across 30,000+ conversations a day across all our users.
No containers. No VMs. No session cleanup. Just Chroma queries behind a bash interface.
Full technical breakdown in the blog 👇
Last week this session took 9 minutes and 150k tokens on Opus 4.6.
Complex app navigation, network debugging, perf profiling on a production app. Justified, right?
Not really. Same session today: 69k tokens. 6 minutes. Less than half.
Here's how 🧵
karpathy is showing one of the simplest AI architectures that actually works..
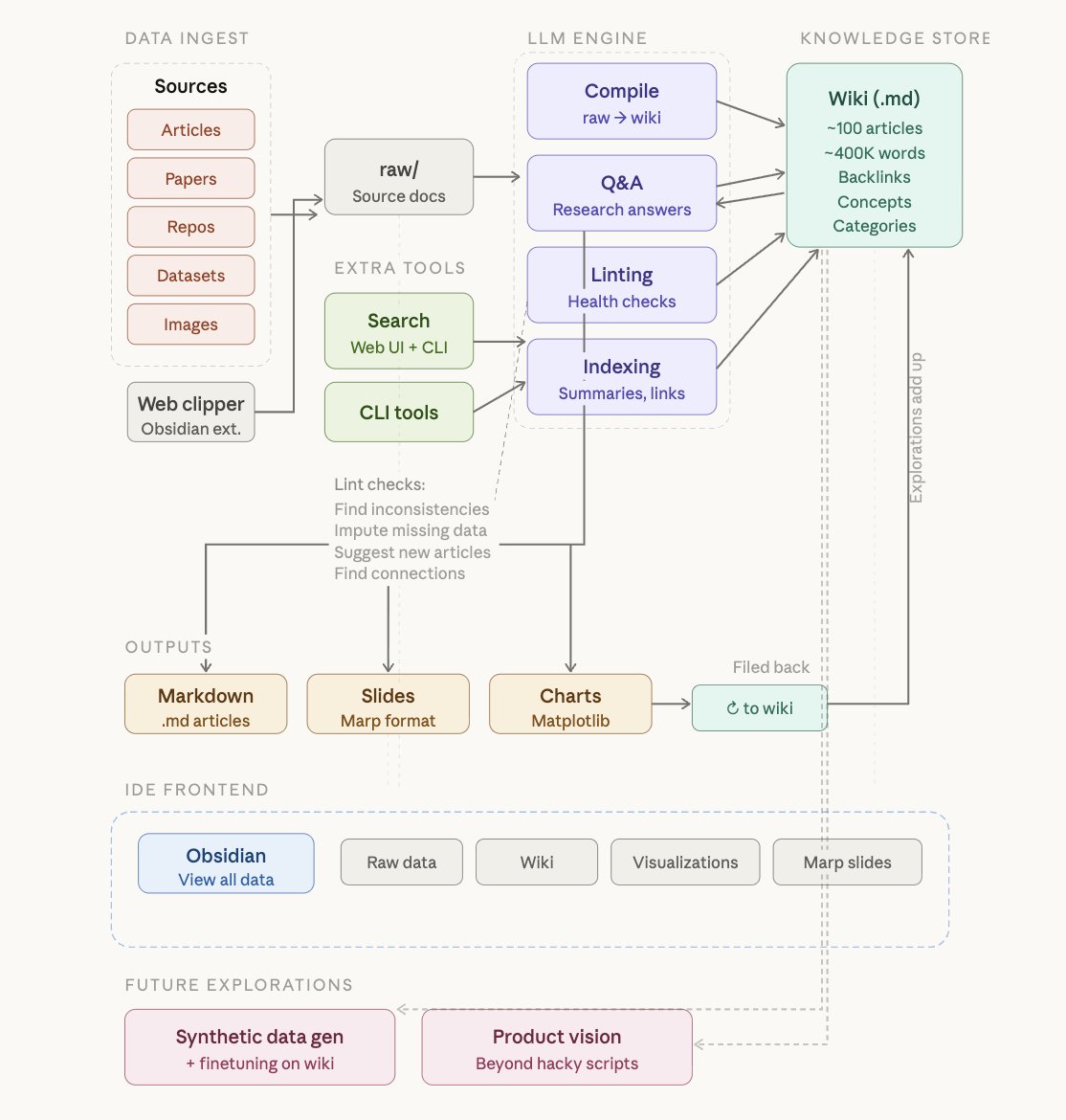
dump research into a folder, let the model organise it into a wiki, ask questions, then file the answers back in.
the real insight is the loop...every query makes the wiki better. it compounds.. now thats a second brain building itself.
i think this is so good for agents if applied right
instead of pulling from shared memory every session, they build a living knowledge base that stays.
your coordinator is not just coordinating tasks anymore.. it is maintaining institutional knowledge so every execution adds something back to the base.
the bigger implication is crazy tho.
agents that own their own knowledge layer do not need infinite context windows, they need good file organisation and the ability to read their own indexes.
way cheaper, way more scalable, and way more inspectable than stuffing everything into one giant prompt.
The LEAD search engineer at Google just dropped a brand new blog post that confirms something most SEOs have never even heard of...
Googlebot only fetches the first 2MB of your pages HTML = Everything after that cutoff doesn't exist to Google!!!
Not fetched, not rendered, not indexed.
And the Web Rendering Service is completely STATELESS - Meaning it clears local storage and session data between every request, so if your content depends on cookies or session state to render, Google can't see it.
External CSS and JS files are fetched SEPARATELY with their own 2MB limit per file, and PDFs get a 64mb limit.
So the structure and order of your code literally matters! And is why some CMSs are so much better out the box than others... Make sure you put your meta tags, title, canonicals, and structured data as HIGH as possible in the document. If they're below the 2MB cutoff, Google doesn't know they exist.
Most OnPage SEO guides never take any of this into account, but most OnPage is surface-level.
The real edge is understanding the infrastructure your content passes through before Google even evaluates it.
Great thread on reducing Claude Code token up to 60%
Best one is using the open-source tool RTK (Rust Token Killer)
It automatically removes noise, merges repeated content, and strips useless blank lines and progress bars.
More details down in @aibuilderclub_ 👇
In 2019, a legendary MIT lecture quietly changed how the smartest people communicate.
Most people still ignore it.
Patrick Winston didn’t just teach speaking he exposed why people fail to be understood.
18M+ views later… it’s still ahead of its time.
His frameworks:
• Your ideas are like your children
• The 5-minute rule for job talks
• Why jokes fail at the start
15 lessons on communication:
the fastest growing GitHub repos this week:
1. affaan-m/everything-claude-code (+22.8K stars)
agent harness optimization. skills, memory, security for Claude Code, Codex, Cursor and beyond.
2. obra/superpowers (+17.0K stars)
agentic skills framework that works. just crossed 116K stars.
3. bytedance/deer-flow (+16.1K stars)
open-source long-horizon SuperAgent. researches, codes, creates. sandboxes + subagents built in.
4. Crosstalk-Solutions/project-nomad (+14.6K stars)
offline survival computer packed with AI. works anywhere, no internet needed.
5. FujiwaraChoki/MoneyPrinterV2 (+10.4K stars)
automate making money online. the sequel nobody asked for but everyone starred.
6. TauricResearch/TradingAgents (+9.2K stars)
multi-agent LLM financial trading framework. because one agent trading isn't scary enough.
7. jarrodwatts/claude-hud (+5.5K stars)
Claude Code plugin showing context, tools, agents, and todos in real time.
8. mvanhorn/last30days-skill (+4.8K stars)
AI agent skill that researches any topic across Reddit, X, YouTube, HN, Polymarket, and the web.
9. NousResearch/hermes-agent (+4.6K stars)
the agent that grows with you.
10. langchain-ai/open-swe (+1.8K stars)
open-source async coding agent. async by design, not by accident.
the theme this week: AI agents took over GitHub again.
bookmark this. next week's list will look completely different.
In 2019, MIT professor Patrick Winston gave a legendary 1-hour lecture called “How to Speak.”
It has 18M+ views for a reason.
His frameworks:
• Your ideas are like your children
• The 5-minute rule for job talks
• Why jokes fail at the start
15 lessons on communication:
Typed a Gmail username once and the UI instantly said: “Username already taken.”
I asked an ex-Staff Google engineer the same problem (he was director of engineering in a startup i worked at), “You’re not doing an Elasticsearch query on every keypress, right?”
He laughed. “No. That’d be a crime.”
My classy approach:
1. Keep an in-memory trie of reserved usernames.
2. Update it async (delta pushes), not per keystroke.
3. UI checks locally in O(k) where k = username length.
Numbers (why this is feasible):
1. Assume 2B usernames, avg length 10 chars.
2. Raw chars = 2B × 10 = 20B chars.
3. Even if you store 1 byte/char (not true in a trie, but baseline) that’s ~20GB just for characters.
4. A trie is about prefix sharing, so common prefixes collapse hard. Real memory is “nodes + edges”, not “strings”.
5. If we model ~1 node per char worst-case: ~20B nodes.
- If a node is 8 bytes (tight packed arrays, bitsets, offset indices; no pointers), worst-case is 160GB.
- With prefix sharing, you can easily cut multiples of that depending on distribution (gmail-like usernames are not random).
6. Shard by first 2 chars (36 possible: a-z, 0-9). 36² = 1296 shards.
- Worst-case per shard: 160GB / 1296 ≈ 123MB.
- Suddenly “instant check” fits in memory per front-end pod or edge POP.
Yes, you can also do it with WebSockets:
1. Client streams “candidate username” events.
2. Server replies with availability.
3. Works fine, but now you’ve built a hot, stateful, low-latency service for… a UI hint.
Most people will ship:
1. Elasticsearch prefix search.
2. Debounce 150ms.
3. Cache a bit.
4. Pray at peak signup traffic.
And it works.
But the trie approach is the kind of solution where the UI feels like magic tbh and it's something novel that i thought of.
Things are just different at google scale.
We just open-sourced Paperclip: the orchestration layer for zero-human companies
It's everything you need to run an autonomous business: org charts, goal alignment, task ownership, budgets, agent templates
Just run `npx paperclipai onboard`
https://t.co/wuDdEmrSMx
More 👇