The safety profile here matters as much as the efficacy. The daraxonrasib arm had a longer median treatment duration (6.2 months vs 1.5–3.2 months across chemo regimens), yet showed lower rates of grade ≥3 events, dose reductions, and treatment discontinuations.
https://t.co/lOOWk1geDo landmark result for pancreatic cancer ... probably the most meaningful survival improvement seen in the second-line setting since the disease was characterized. Daraxonrasib operates as a tri-complex inhibitor: it recruits cyclophilin A intracellularly to form a binary complex that then engages RAS in its active GTP-bound state = RAS(ON).
@midwit_capital Precisely. For ultra-rare events, high sensitivity is the key to greater utility because it dramatically reduces false negatives = truth (eventual relapse if falsely negative). I’m not yet aware of a study where MRD detection didn’t eventually result in overt relapse.
We’ve automated every single thing we can @every with AI agents.
And yet there’s way more human work to do than ever. We’ve gone from 4 -> 30 human employees since GPT-3.
I wrote a report on the structural reasons: how AI makes expert competence cheap, why that drives up demand for experts, and why the dynamic only intensifies as we approach AGI.
After Automation: https://t.co/Lb7SUCduAg
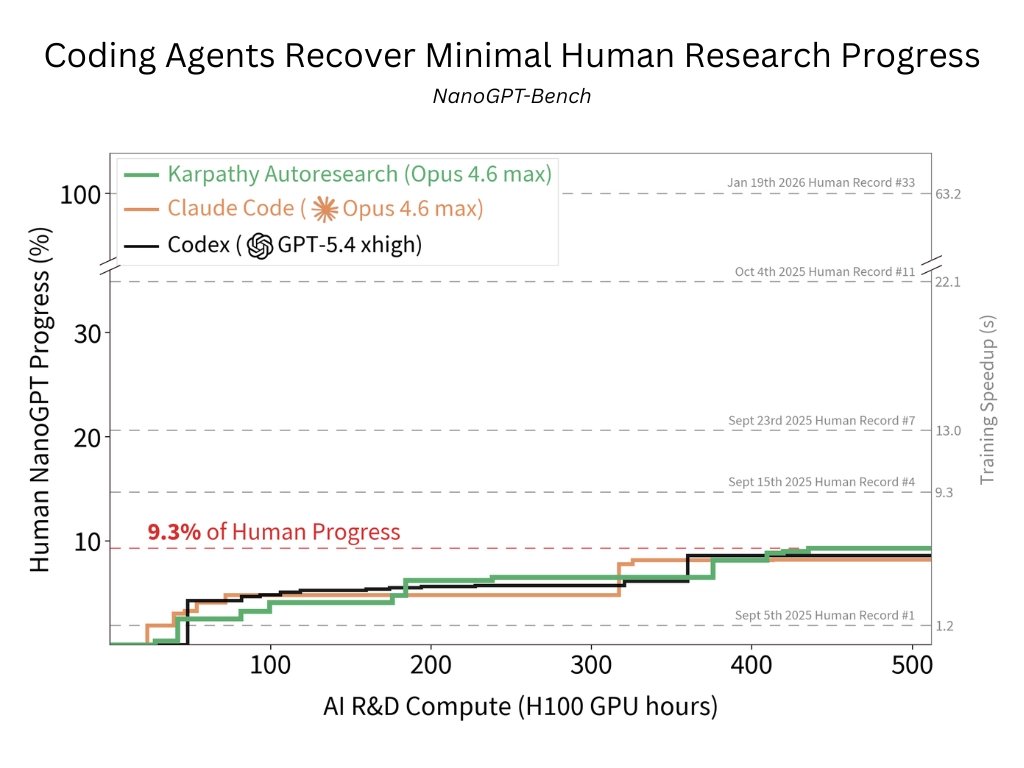
Can coding agents do research?
We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress
Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵
If you are running a consulting business and you are deploying Anthropic or OpenAI directly into your organization (I’m looking at you PwC and Accenture) you are letting the fox into the hen house.
OpenAI and Anthropic are openly funding and starting competitors to you while also using your usage to drive more success for them.
This is not a failure on their part but a failure on your part.
Consulting businesses that understand this are adopting a control plane that allows them to arbitrate where tokens go and who generates tokens for them.
Controlling the tokens is controlling the spice (Dune).
This was a key pillar of 8090’s global partnership with EY and they key feature of our Software Factory. We control token generation and can direct them to any model provider.
We are close to another global partnership and will announce it soon.
These organizations refuse to accept the disruption standing still or, even worse, by adopting and accelerating the companies who want to disrupt them.
🚨What if we could reliably program macrophage polarization state?🚨
https://t.co/6qGxuHptQq
Macrophages are highly plastic immune cells that perform critical functions by polarizing into distinct cellular states. The polarization state of macrophages can substantially influences the progression of cancers, infections, and autoimmunity. (1/11)
Sanders and AOC introduced a bill to pause ALL AI data center construction. 300+ local bills filed. Half of planned 2026 data centers facing delays or cancellation. Each one brings billions to local economies.
The people who say they want American jobs are trying to block the biggest job creation engine since the interstate highway system.
Was. The pathophysiology of sickle cell disease is the presence of sickled cells. The SWITCH and the STOP trials have shown us that hemoglobin F upregulation for e.g. is insufficient to prevent stroke hence ASH guidelines are to maintain HbS < 30% … which zero existing therapies do. True gene correction soon
We are back. After one year of quiet building.
Introducing GENE-26.5, our first robotic brain that takes a major step toward human-level capability.
For years, robotics has struggled to learn from the world’s largest and valuable data source: Humans.
Solving it means rethinking the whole stack from the ground up:
- A robotics-native foundation model.
- A 1:1 human-like robotic hand.
- A noninvasive data collection glove for motion, force, and touch.
- A simulator that turns weeks of experiments into minutes.
GENE-26.5 is trained across language, vision, proprioception, tactile, and action. We designed a set of tasks to test how far we can go with this new paradigm.
Fully autonomous, 1x speed, one model, same weights. (Enjoy with sound on)
We are approaching the endgame for robotics.
And this is just a beginning.