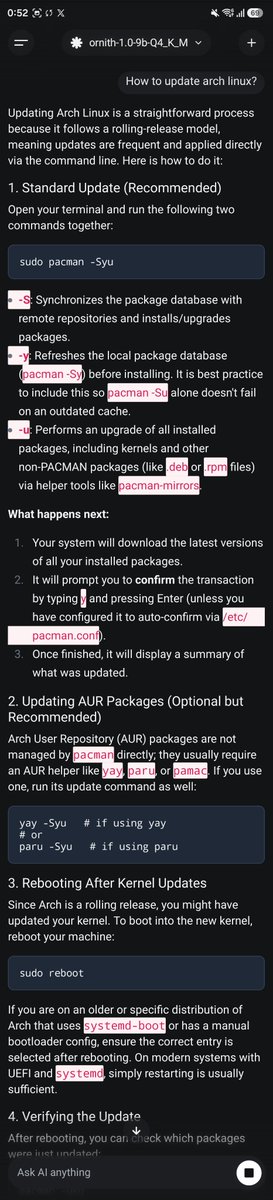
@ornith_ I am running Ornith-1.0-35B-GGUF:BF16 on an RX 6900 XT + Threadripper 3970X with 128 GB RAM.
It's very impressive. From my testing in Zed editor over Ollama-Vulkan, it's between GPT-5.3 xHigh and 5.4 High.
I'm ready to donating to dev process, no limits, local data, that's it.
@M47429M@lucidwing17 1. Please use English.
2. Given the existence of numerous models possessing capabilities akin to GPT-4o, what specific challenges or issues are being encountered?
@SapientFoo1@lucidwing17 Yes! It would be appreciated if you could respect OpenAI's decision. They own their model and have no obligation to operate inefficient, underperforming models on costly modern infrastructure, especially since you have the liberty to utilize models such as GPT-4o on your device.
@Anthony39218878@JoeWilliams010@sama What kind of power? Gemma 4e4b can be run on a smartphone and it's equally powerful. Gemma 31B can be run on a single GPU at home and it's far more capable than 4o.
Bro, stop living under the rock. 😉
@JoeWilliams010@sama Totally stupid model, which even can't generate proper script or even correct sentences.
Just host local model, all local models are far better than 4o, lol.