My time at Ai2 / @allen_ai has come to an end.
Ai2 is a wonderful place. The last 2.5+ years building Olmo, Tulu, and other projects will be one of the peaks of my entire career. I'm extremely thankful for my teammates and the open community who made this work possible.
For me, it's time to try something different. I will still be working in the open model & open science spaces (more news on that soon). In the meantime I'll be spending a few months learning, chatting with a broader network, getting married (!!) and most importantly recharging from pouring my soul into this place.
I've attached the note I shared with the team and some fun photos from our time together. I'll keep cheering for Ai2 and am excited to see what you build next.
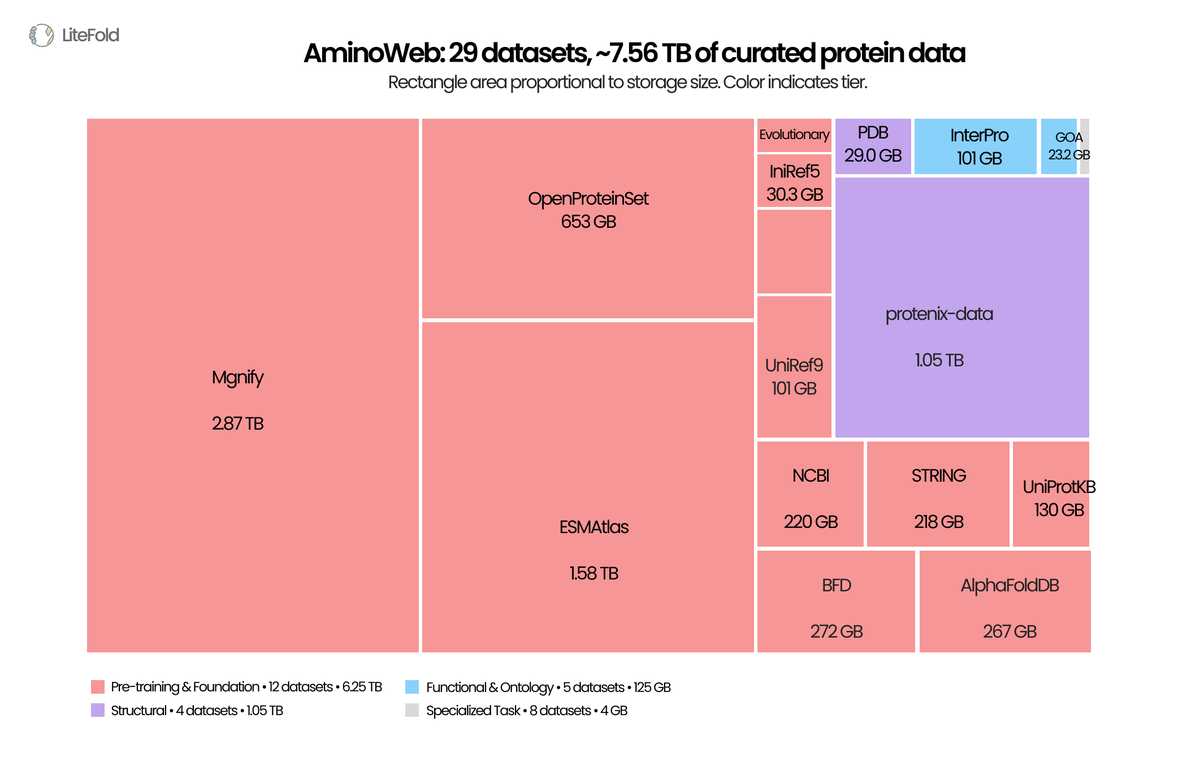
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: https://t.co/elQ7pzpNkG
Read the release blogpost: https://t.co/28yFU2m9Jc
➿Looped Diffusion Language Models
Looping has landed in dLLMs, and it is surprisingly effective! Accelerates training convergence 3.34x, improves GSM8K accuracy +8.5% on the same data, and enables test-time depth scaling. Check out our LoopMDM paper for more details!
Stop using Whisper for ASR !
open sourcing Mega-ASR — the first full-scenario SOTA industrial-grade ASR model, built for the audio nobody else can crack: far-field, reverb, electrical hum, device noise, the real-world mess.
beats open + closed SOTA by 10–30% on real-world benchmarks. the harder the audio is for humans, the bigger the lead.
I'm joining Carnegie Mellon's CS Department (and HCII by courtesy) as an assistant professor in Fall 2027!
I'll be recruiting PhD students next cycle. If you're interested in AI systems or human-AI collaboration, list me in your application. Stay tuned for more about my new lab!
There is a lot of hype around continual learning, but what is it and how do we evaluate it?
With our new continual learning bench we sought to answer both of these questions. We developed a new methodology for designing continual learning tasks and a growth-based learning metric to isolate continual learning.
Have you experienced models (agent loops) rapidly improving on your tasks? Do you have tasks that could benefit from continual learning? Let us know.
Hiring: Research Intern @ MaruthLabs
We are looking for a Research Intern to join us for a 3-month internship focused on pushing the boundaries of high-performance Small Language Models (SLMs).
The Role:
• Research & Experimentation: You will be given access to 0.5x H100 GPU compute to test and iterate on your own research ideas.
• Scaling Up: Upon reaching your research milestones, you will be granted access to an 8x H100 node for a full-scale training run.
• Integration: Successful experiments and optimizations will be integrated directly into our core model training pipelines.
Requirements:
• Strong proficiency in Python and a deep understanding of Transformer architectures.
• A research-oriented mindset with an interest in SLMs, efficiency, and context-length expansion.
• Degree is not a barrier: We value proof of work, GitHub contributions, and technical curiosity over formal credentials.
Details:
• Stipend: ₹15,000 per month.
• Duration: 3 Months (Extendable).
• Location: Remote.
How to Apply:
Interested candidates should send their CV and a brief outline of a research idea they would like to explore on an H100 to [email protected].
#MaruthLabs #LLM #Research #Hiring #MachineLearning #SLM
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10+ frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)
it's been a crazy journey:
• quit my $125k/yr job at cisco
• $250k funding by ef
• moved to sf
• now working with folks at google
you can do anything u put ur mind to
exam question from my ML prof: "why does a model overfit a distribution?" wrote bias-variance tradeoff, even cited andrew ng's course notes. he marked it 0/5 saying "i haven't taught this so it doesn't happen"
I worked with 3 PhD researchers and college professors teaching ML in Pune colleges.
They don't even know the difference between softmax and sigmoid, and all they want is to get a PhD so they can become HOD of the CS department.
I worked with them, explained each part, and earned 2x my MSc fees. I also helped them create an ML curriculum.
In my batch, I'm the only one working in ML. Other students hate ML and mostly work in Angular/Node.js jobs. Even in my practical lab exams, my professors couldn't understand how I coded KNN. They just nodded their heads and looked confused.
Sad reality of most PhD researchers in India.
We are publishing our second deep dive today as a follow-up post on SLAM and VIO in egocentric tracking. We go deep into the sensor tradeoffs b/w global shutter and rolling shutter and their implications on SLAM / VIO - specifically how the way the camera reads each frame can introduce significant tracking errors before our SLAM pipeline even starts processing.
We break down why global shutter is the obvious fix but the wrong default, the physics of why rolling shutter dominates every consumer device, and where the fundamental limits lie.
Addressing some of the most asked questions:
1. We want to collaborate with you! I received many questions from folks asking to contribute tasks or helping with adding other models + harnesses. We are figuring out a structured way to contribute and will announce it soon!