Now that I have started using twitter somewhat regularly, let me take a minute to advertise the RL theory lecture notes I have been developing with Sasha Rakhlin: https://t.co/x16aGvE4tr
🗣️ “Next-token predictors can’t plan!” ⚔️ “False! Every distribution is expressible as product of next-token probabilities!” 🗣️
In work w/ @GregorBachmann1 , we carefully flesh out this emerging, fragmented debate & articulate a key new failure. 🔴 https://t.co/fLgLAjvIUf
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
paper page: https://t.co/vJHkg8dce0
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
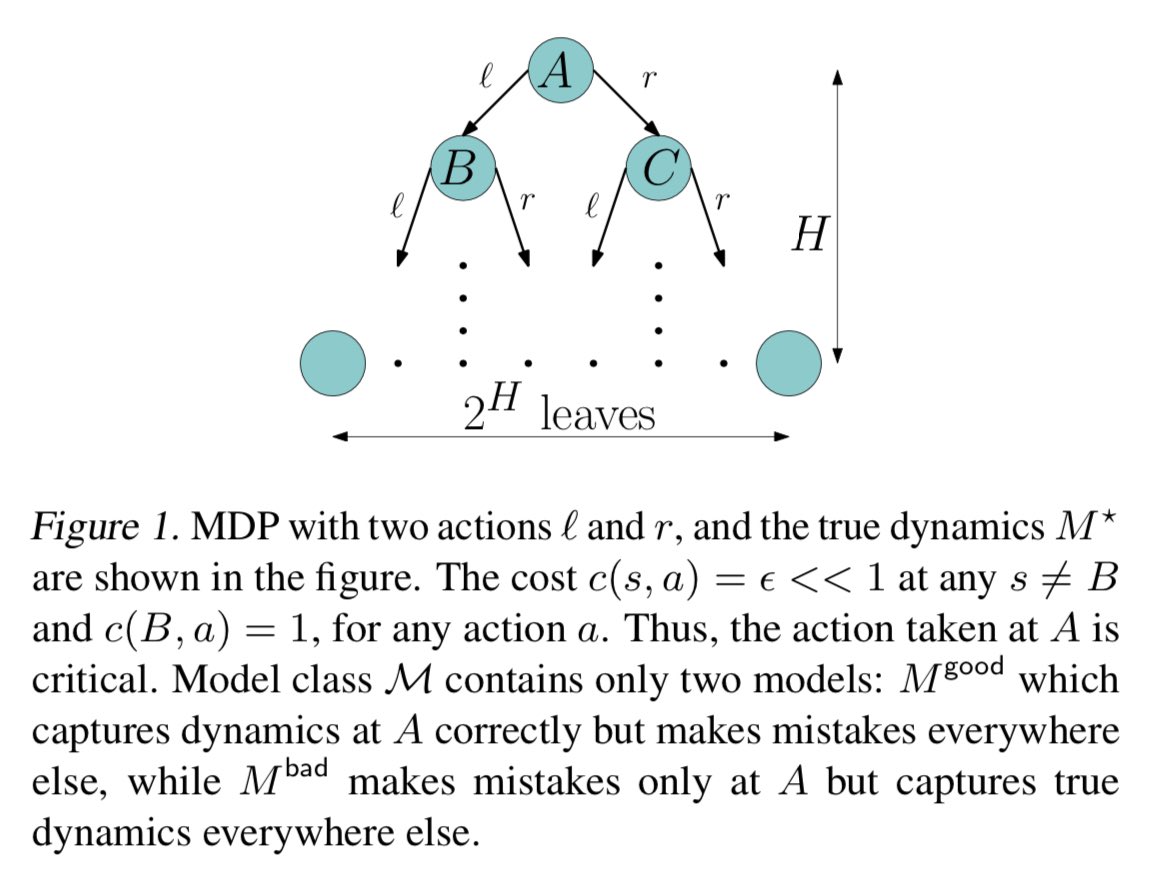
If this has been a long thread, this can be the only tweet to pay attention to the example figure to understand awesomeness of PDAM.
MBPO: O(2^H) computation per iteration, and converges to bad model
LAMPS-MM: O(H) computation per iteration and converges to good model
I'm rarely as excited about a paper as our #ICML2023 paper: we develop an algorithm for doing inverse reinforcement w/o an expensive RL inner loop, providing an *exponential* speedup. Works *extremely* well in practice. Joint work w/ @sanjibac, @zstevenwu, and Drew Bagnell. [1/n]
I am delighted to say that I will be joining the Colorado School of Mines @CSatMines 💻🤖 as an Assistant Professor 👨🏫 this January!
#academia#AcademicTwitter
Why is being laziness a fundamental virtue in both model based RL and IRL? Excited to share our new ICML'23 papers https://t.co/nuqnxMuyes and https://t.co/79pP9SVOn5 that gets at the heart of this question. Check out my talk at my CMU to learn more! https://t.co/ltOQXEFkFT
Our paper on a new (lazy) approach to model-based RL that is both computationally efficient and avoids the objective mismatch problem has been accepted for ICML!
Excited to present it at Honolulu this summer!
https://t.co/ENKppPA6Bk
If this has been a long thread, this can be the only tweet to pay attention to the example figure to understand awesomeness of PDAM.
MBPO: O(2^H) computation per iteration, and converges to bad model
LAMPS-MM: O(H) computation per iteration and converges to good model
























![g_k_swamy's tweet photo. I'm rarely as excited about a paper as our #ICML2023 paper: we develop an algorithm for doing inverse reinforcement w/o an expensive RL inner loop, providing an *exponential* speedup. Works *extremely* well in practice. Joint work w/ @sanjibac, @zstevenwu, and Drew Bagnell. [1/n] https://t.co/WiDkLpWRHL](https://pbs.twimg.com/media/F0iwxSvaAAApt9X.jpg)



















