Senior Research Scientist at @Google Research, working on usable theory and algorithms for Reinforcement Learning, Generative Optimization, and Robotics
LLM has been struggling to solve search and optimization at scale when feedback is stochastic. We propose a simple solution, POLCA, using text embedding with “provable” guarantee. Excited to see the first theoretically correct work of LLM optimization. Kudos to @XuanfeiRen
🚀 How can we make LLM-based optimization stable and scalable when the feedback signal is stochastic?
Introducing POLCA: a framework for robust, scalable stochastic generative optimization.
Paper: https://t.co/xgdjISRxtE
Code: https://t.co/9TRuyvxVcf
🧵👇 1/
Looking for Google research student researcher (PhD student) to work on LLM and agent related learning.
Preferred background: RL/game theory, agentic system, LLM training.
Candidate will work closely with me and @allenainie
Email me if you are interested. 😀
I have served as AC for NeurIPS every year since 2020. Just declined (with messages adapted from @xuanalogue). At least the organizers owe the community an explanation why they are the only major ML venue adopting such a policy.
Too close to home?
Junior researcher: I’m publishing papers at NeurIPS, my students are happy, but my chair says I’m “not impactful enough.” I don’t know what that means.
Senior researcher: What did you tell them you accomplished last year?
Junior: 3 top-tier papers, a new theoretical result on regret bounds, and an invited talk.
Senior: And what did they hear?
Junior: That I published 3 papers?
Senior: They heard “I added to the publication count, but didn’t bring in grants or visibility for the department.”
Junior: But regret bounds are impactful!
Senior: To who?
Junior: To… theorists?
Senior: Your chair spends 20 minutes a month justifying your position to the dean. Can they use regret bounds to argue for funding?
Junior: …probably not.
Senior: What external metrics did your work move?
Junior: One collaboration, one best paper award, and some citations. We don’t really track grant impact.
Senior: There’s the problem. Half your contributions are invisible by design.
Junior: But theory is necessary. The field would break without it.
Senior: I believe you. The dean doesn’t care.
Junior: That seems unfair.
Senior: It is unfair. It’s also how academia works. Chairs get grilled on grants, rankings, and prestige, not the long-run stability of ML theory.
Junior: So what should I do?
Senior: Reframe. “Secured $500K in funding to explore foundational algorithms” sounds better than “proved a tighter regret bound.”
Junior: But I don’t have that funding.
Senior: Then you’re fighting academic reality without weapons.
Junior: I don’t have time to write grants and still publish.
Senior: Most junior faculty don’t. That’s the trap — you get judged on impact but don’t get impact resources.
Junior: So what do I do?
Senior: Acknowledge the game is rigged, then play it anyway.
Junior: Meaning?
Senior: Build collaborations that attract funding. Tie your theory to hot applied areas. Translate your results into language deans understand.
Junior: That feels political.
Senior: Everything above a certain level is political. The choice isn’t political vs pure. It’s visible vs irrelevant.
Junior: What if my chair still doesn’t care?
Senior: Then you’ve learned your chair doesn’t know how to evaluate theory. That’s a different problem — one you solve by finding a better environment.
Junior: This is harder than just proving good theorems.
Senior: Proving good theorems is table stakes. Surviving academia while proving good theorems — that’s the actual job.
Kicking off #RLC2025 with our Workshop on Programmatic Reinforcement Learning! This workshop explores how programmatic representations can improve interpretability, generalization, efficiency, and safety in RL.
🔄 We were nominated for Oral+top 1 in the MATH-AI workshp at #ICML!
🚨Why? ≈46 % of GitHub commits are AI-generated—but can we verify them correct?
📢 VeriBench challenges agents; turn Python into Lean code!
🧵1/14
📃 Paper: https://t.co/QPCxg5lKM4
Our #ICML2025 Programmatic Representations for Agent Learning workshop will take place tomorrow, July 18th, at the West Meeting Room 301-305, exploring how programmatic representations can make agent learning more interpretable, generalizable, efficient, and safe! Come join us!
Our #ICML2025 Programmatic Representations for Agent Learning workshop will take place tomorrow, July 18th, at the West Meeting Room 301-305, exploring how programmatic representations can make agent learning more interpretable, generalizable, efficient, and safe! Come join us!
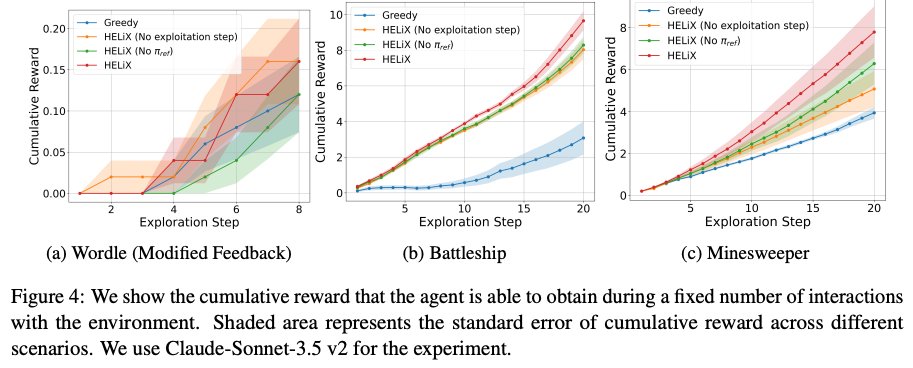
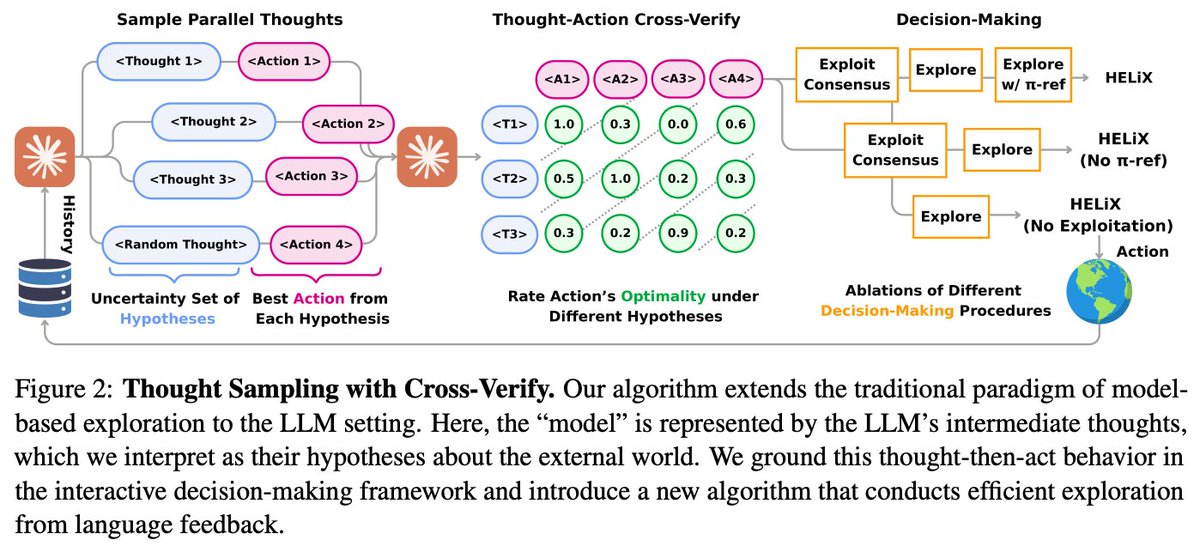
Provably Learning from Language Feedback
TLDR: RL theory can help us do better inference-time exploration with feedback.
Work done with @wanqiao_xu, @ruijie_zheng12, @chinganc_rl, @adityamodi94, @adith387
📰 https://t.co/Zi3EwmX98R
📍EXAIT Best Paper/Oral Sat 8:45-9:30 am
Super excited about this work done by our former intern @wanqiao_xu . We show Learning from Language Feedback (LLF) with LLM can be formally studied with provable no-regret learning algorithms. This result builds a foundation toward new theories for LLM learning and optimization.
Decision-making with LLM can be studied with RL! Can an agent solve a task with text feedback (OS terminal, compiler, a person) efficiently? How can we understand the difficulty? We propose a new notion of learning complexity to study learning with language feedback only. 🧵👇
Decision-making with LLM can be studied with RL! Can an agent solve a task with text feedback (OS terminal, compiler, a person) efficiently? How can we understand the difficulty? We propose a new notion of learning complexity to study learning with language feedback only. 🧵👇
Check out this new optimization framework (https://t.co/sN6E1jWl4n) by #DataRobot that can automatically search for "Pareto-optimal" solutions for agentic workflows. It's built on our LLM generative optimization framework #Trace. Excited to see more applications of #Trace! 😎
We're organizing workshops on Programmatic Representation for Agent Learning at the upcoming #ICML2025 and #RLC2025. We welcome contributions using programs as policies, reward functions, skill libraries, task generators, environment models, etc., and more! See you soon!😀
The RLC accepted workshops list is out (link in next tweet)!
Programmatic RL
Causal RL
RL and videogames
Inductive biases and RL
and returning from last year: RL beyond rewards, finding the frame, and RL in practice!