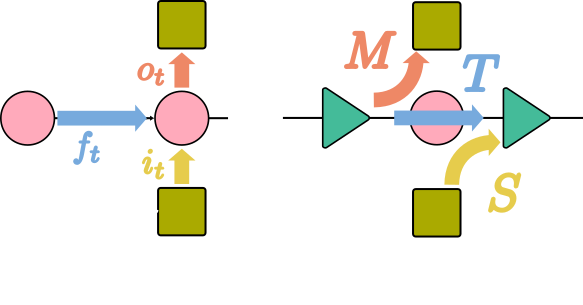
This is what we have been working on for the last few months. Advent of architectures like xLSTM open new frontiers of efficiency for generative models. The xLSTM not only provides constant memory consumption with increasing context length, but is extremely fast at inference.
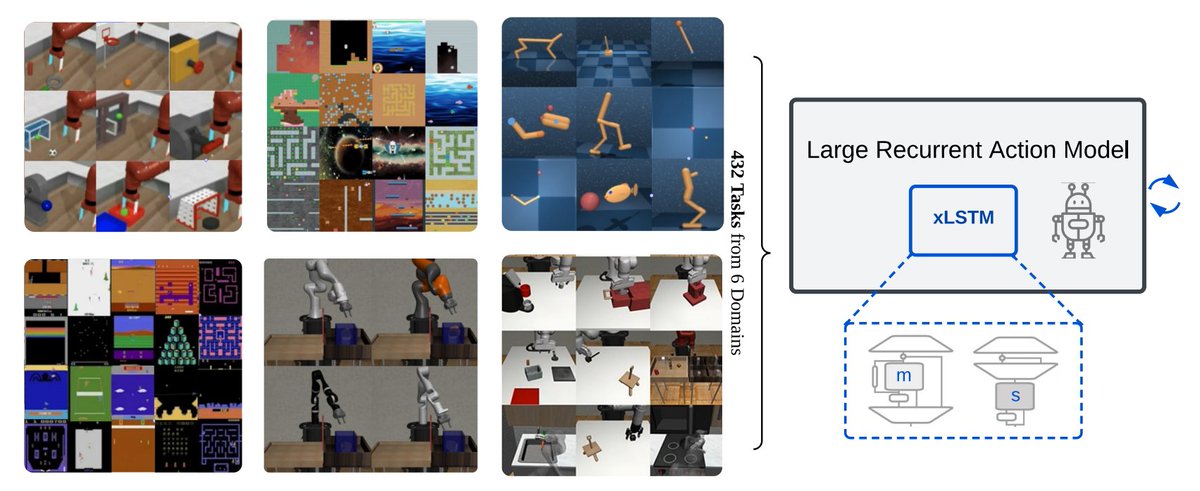
Transformers can be slow for real-time applications like robotics. We study if modern recurrent architectures, like xLSTM and Mamba, can be faster alternatives. Experiments on 432 tasks show that they compare favourably in terms of performance and speed 🎃 https://t.co/4RUDRich35
Check out https://t.co/UEPjVrCACL. It’s your constant AI research companion.
Read any PDF with the AI as your partner.
✍️Highlight and annotate your reading
🤖Ask powerful AI models questions
🗂️Organize your reading into folders
🌐Find new papers via conversation search
Ever wondered how linear RNNs like #mLSTM (#xLSTM) or #Mamba can be extended to multiple dimensions?
Check out "pLSTM: parallelizable Linear Source Transition Mark networks". #pLSTM works on sequences, images, (directed acyclic) graphs.
Paper link: https://t.co/nU7626uHWK
#Eka initiative is looking for your contributions to curate the List of websites in the Native Indian Languages. The majority of Indic websites are missing from existing corpora like CC.
Please fill out this form to add URLs in your native language: https://t.co/cxlUsvn2rv
Yesterday, we shared the details on our xLSTM 7B architecture. Now, let's go one level deeper🧑🔧
We introduce
⚡️Tiled Flash Linear Attention (TFLA), ⚡️
A new kernel algorithm for the mLSTM and other Linear Attention variants with Gating.
We find TFLA is really fast!
🧵(1/11)
📢🔔I am excited to share the details on our optimized xLSTM architecture for our xLSTM 7B model!🚨
We optimized the architecture with two goals in mind:
- Efficiency (in Training and Inference)
and
- Stability
🧵(1/7)
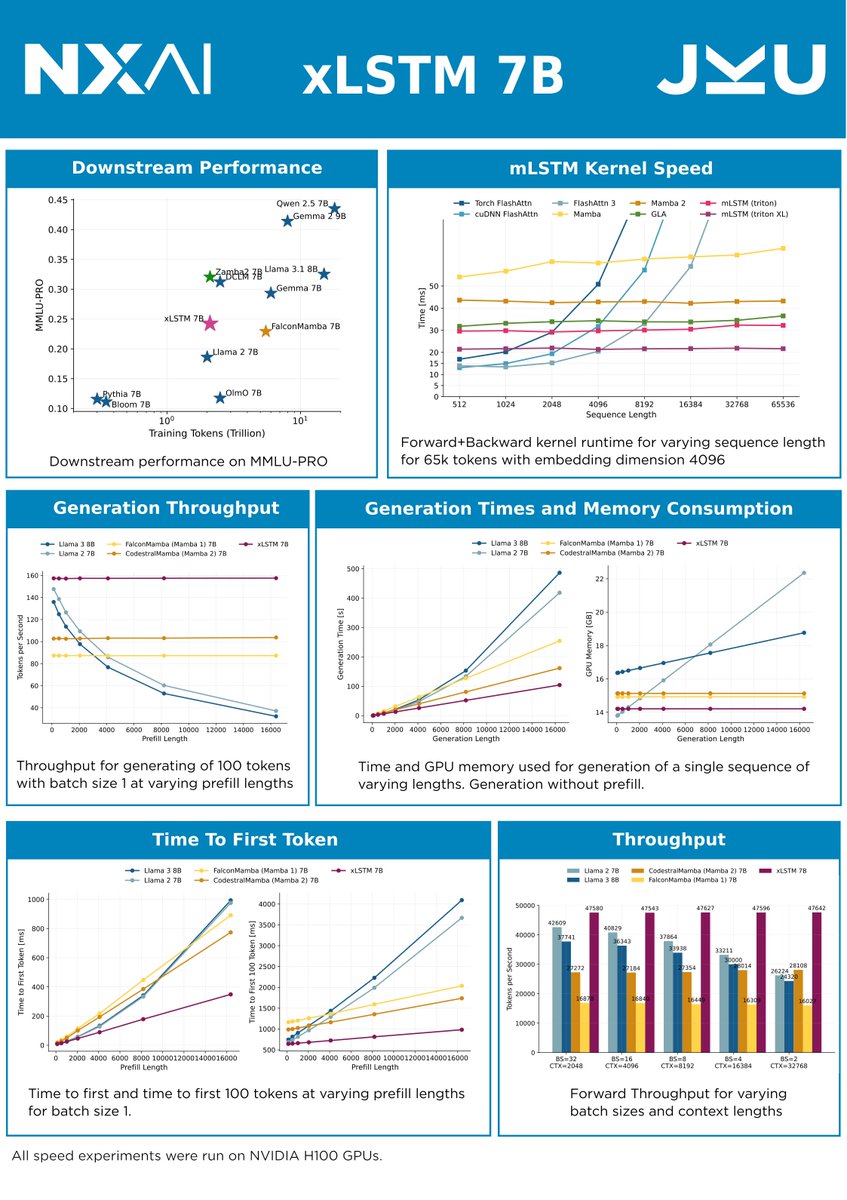
Check out our latest work on scaling up xLSTM to 7B parameters and 2.3T tokens, with all open training data, open training protocol and open training code. Nice team work! 💪💪
Join Our Research Team in Linz!
We are looking for 5 PostDocs and 10 PhDs in Machine Learning working on xLSTM, NLP, robustness, learning theory.
Deadline: 04/20/25.
More details: https://t.co/FLcOWZJzPQ
#MachineLearning#DeepLearning#ResearchOpportunities#PhDPositions
Everything old is new again.
Mamba/ssm folks should really google their "new idea + lstm" please. About a decade ago, people have tried a shitton of things with lstms. Nothing wrong with retrying with modern tools, but ack the past.
This is not the first such case I see btw.
𝗡𝗲𝘄 𝗣𝗮𝗽𝗲𝗿 𝗔𝗹𝗲𝗿𝘁: Rethinking Uncertainty Estimation in Natural Language Generation 🌟
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper 👇https://t.co/hOEhuWloqN
Thrilled to announce two new developments at JKU and NXAI that are released today:
- We scaled xLSTM to 7B parameters: https://t.co/jJqQk2HFvq
- For the people caring about state tracking capabilities, there's the new FlashRNN library: https://t.co/zirQOaR6Wv
We are excited to introduce Bio-xLSTM! TLDR: we extend xLSTM to genomic, protein and molecular domains and find that it is a proficient generative model, learns rich representations and can perform in-context learning.
Bio-xLSTM: Generative modeling, representation and in-context learning of biological and chemical sequences
xLSTM also shines for DNA, proteins and small molecules -- can handle large-range interactions and huge context!
P: https://t.co/kvd9gdrM7C
xLSTM as large recurrent action model. xLSTM has the potential to enter the field of robotics as it is much faster than transformers at inference. xLSTM can close the reality-gap by online learning in applications like robotics, self-driving, automated production systems. Cool.
A LARGE RECURRENT ACTION MODEL: xLSTM enables Fast Inference for Robotics Tasks
In robotics & embodied AIs, very fast inference is needed which is prohibitive for Transformers. xLSTM is well suited because of its recurrent inference mode.
P: https://t.co/JnGsGFxXIJ
Graph distillation compresses massive graph datasets into tiny versions that train GNNs as effectively as the original.
But current methods have a huge problem..
They require training on the full data first—which defeats the whole purpose!
Enter Bonsai(https://t.co/holnYG4SVq)
Deep Ensembles are widely used to improve the performance of Deep Learning models. But beware, they can have profound impact on group fairness ⚖️ We analyzed why it happens and what can be done about it 🧵👇