Based on what happened this year at CVPR 2026, it seems that the vision community is making a full swing back to 3D vision. Just to remind young people who just got interested in this subject, my first textbook, written 20 years ago, is probably still the best introduction to this topic: https://t.co/7Ks0wYAKhY
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Following the latest CVPR paper SAMTok: Representing Any Mask with Two Words by @xtl994 , AutoSOTA built on this inspiring work and further improved gIoU to 82.4 (+0.7) using higher MLLM image resolution from 448 to 896. We are grateful to the authors for the strong foundation that made this follow-up possible.
AutoSOTA Project: https://t.co/w3XcHD7hjI
Enhancement Details: https://t.co/t0REzJoRpB
Original paper: https://t.co/Q4QfCmdfwj
#AutoSOTA_LiveCVPR #CVPR2026 #AutoSOTA #AIScientist #AutoResearch #MachineLearning #AcademicX #ResearchAutomation
This may be a controversial take, but I think it needs to be said: the gap between computer vision research in academia and industry is widening with every conference.
A huge fraction of @CVPR papers—especially those that boil down to "we tweaked/fine-tuned/RL'ed large-scale model X to improve on task Y"—will become obsolete with the next model release. That's not where academia creates lasting value. PIs should adapt much faster to this changing reality.
Academia should focus on fundamentally new ideas, new problem formulations, explaining emergent phenomenology, or uncovering blind spots that industry can later solve with scale, compute, and data.
Proud to share our lab’s @MMLabNTU work Log-linear Sparse Attention (LLSA) - a trainable sparse attention mechanism that reduces attention complexity from O(N²) to O(N log N), making diffusion transformers much more efficient.
Also, special shout-out to the first author @zhouyifan1107 for presenting the poster in full costume - truly above and beyond. The level of dedication is impressive! 👏
#CVPR2026 #DiffusionModels #EfficientAI #SparseAttention
Big thanks to @BanghuaZ for sharing so many honest and practical insights.
- Do the right thing at the right time with the right people
- Explore more and make more mistakes
- Let go, and embrace the new wave.
- Be kind
- Have good taste
- etc
https://t.co/Gqt2DbasrH
Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
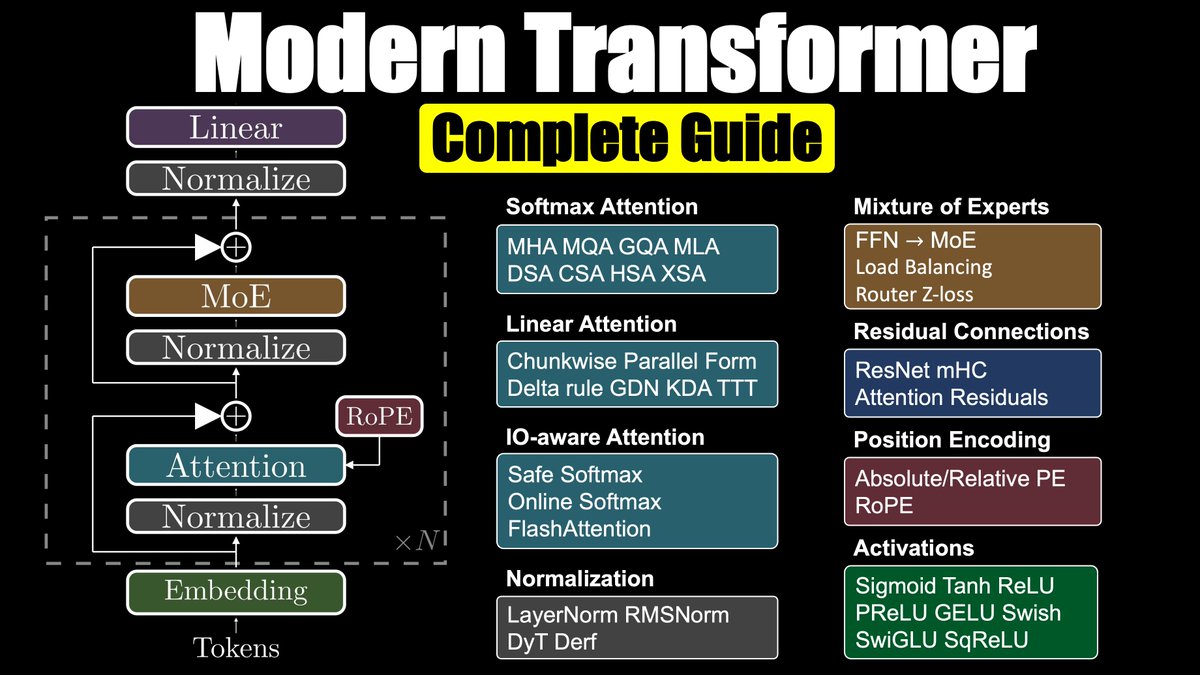
Modern Transformer - Complete Guide
Interested in learning the recent advances in transformers?
After 13 videos, I've finally completed this series!
🥳🥳🥳
Check out the course here:
https://t.co/CsujxlWigC
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
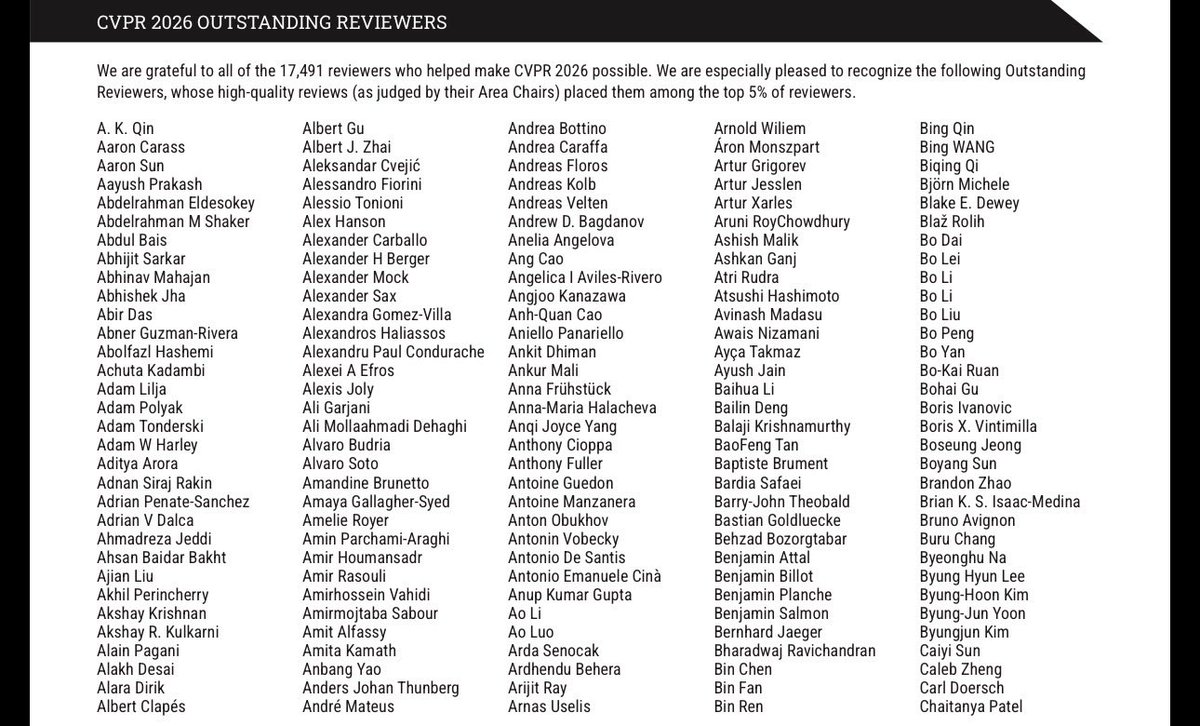
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
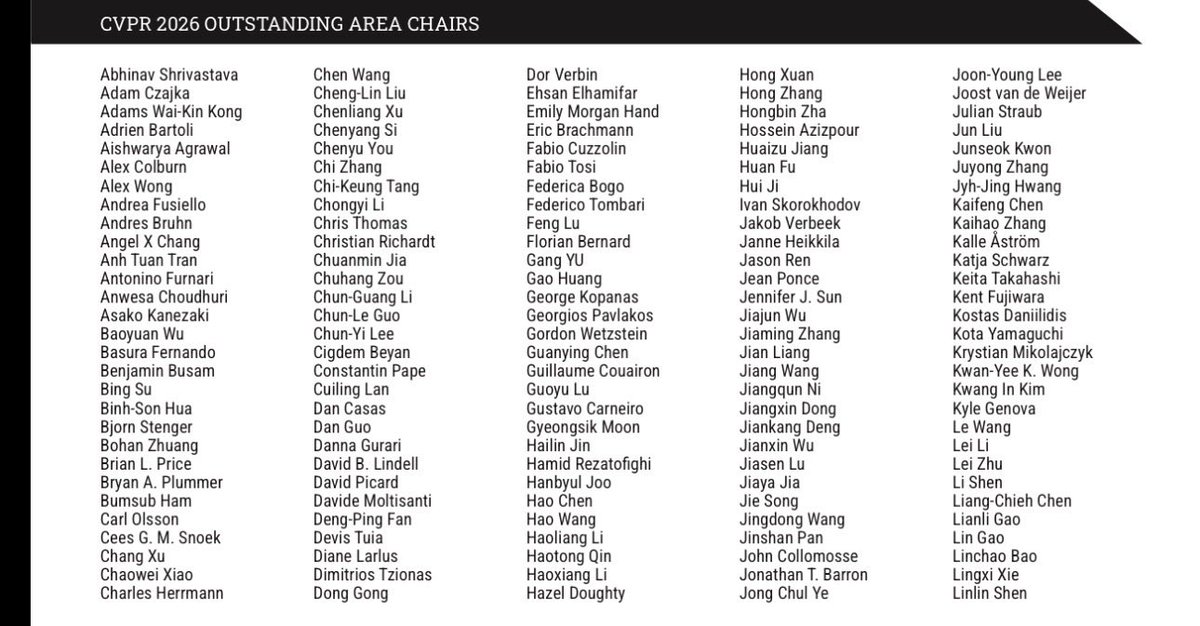
Thank you to all the #CVPR2026 Area Chairs for steering the review process.
We would like to give special recognition to the following Outstanding Area Chairs for their exceptional efforts and leadership.