What if humanoids could manipulate without stopping, using a high-DoF dexterous hand?
🚨We introduce CoorDex, a learning pipeline for continuous dexterous humanoid loco-manipulation — coordinating whole-body motion and high-DoF finger control while the robot is still moving.
This enables a Unitree G1 with a 20-DoF WUJI dexterous hand to:
🤖 grasp and carry a bottle while walking
🚪 open a fridge while stepping backward
🔄 pick up a cube and turn 180°
🔗Project page: https://t.co/SipTif9kZu
📜Paper: https://t.co/cWssYQu4Oh
🧵(1/n)
We just released WatchAct, a benchmark for behavior-grounded robot manipulation (covered in the talk below). The robot has to watch a human video, infer what was done, make a plan, and then execute it. The best VLM (Gemini-3.1-Pro) only reaches 36.8% planning success rate, so still plenty of room for improvement.
Paper: https://t.co/z4COXQIMhh
Project: https://t.co/6CBUWQlEk8
Code: https://t.co/Kl8BO7vqiF
Dataset: https://t.co/IW0NKFUcZj
w/ @baiqil0203@cezhhh@yuffishh@dingmyu
Sharing my CVPR 2026 talk from the Vision for Intelligent Task Assistants workshop: "From Perception to Agency: The Cognitive Stack for Video Task Assistants."
It covers our SVI-Bench project (https://t.co/BAtXqeU5oY) plus a video+robotics project we'll release soon.
w/ @YuluPan_00@mmiemon@Han_Yi_724@mars_su0311@baiqil0203
https://t.co/9hpF28ZpUB
If you're curious about the background that inspires a lot of our group's research on skill learning and video understanding, check out this great piece by UNC Research. It covers some of my journey from being a basketball player to an AI researcher.
https://t.co/rMqTJItpf1
Do Vision-Language-Action Models truly follow your language instructions?
We present When Vision Overrides Language: Evaluating and Mitigating Counterfactual Failures in VLAs. They promise to ground language instructions in robot control, yet in practice, often fail to follow language faithfully.
📄 Paper: https://t.co/Ty79Bp61zT
🌐 Project: https://t.co/bBEsN5jlzH
💡 Highlights
Vision shortcuts and counterfactual failures. When given instructions that lack strong scene-specific supervision, they default to well-learned scene-specific behaviors regardless of language intent.
Counterfactual benchmark. We introduce LIBERO-CF, the first counterfactual benchmark for evaluating language following in VLAs. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs.
Our solution. We propose Counterfactual Action Guidance (CAG), a simple plug-and-play dual-branch inference scheme that strengthens language conditioning without changing pretrained VLA architectures or weights.
Experiments. CAG is effective across multiple dimensions of language grounding, consistently improving both language grounding and task success on under-observed tasks.
#VLA #Robotics #Vision #Language
🤖Real-world Experiments
We study different aspects of language grounding. Each scene is designed with three possible tasks: one well-learned in-domain task with sufficient demonstrations, and two under-observed tasks defined by counterfactual instructions.
Across object recognition, spatial reasoning, goal targeting, out-of-distribution generalization, and long-horizon reasoning, our proposed CAG consistently improves the performance of pi0.5 and reduces counterfactual failures.
[5/6]
my first PI project: we added memory!
this is a step function capabilities unlock: 15 minute long multi-step tasks in novel environments, controlled by text prompting
having run many of the evals, I legit think this is the GPT 2 moment for robotics
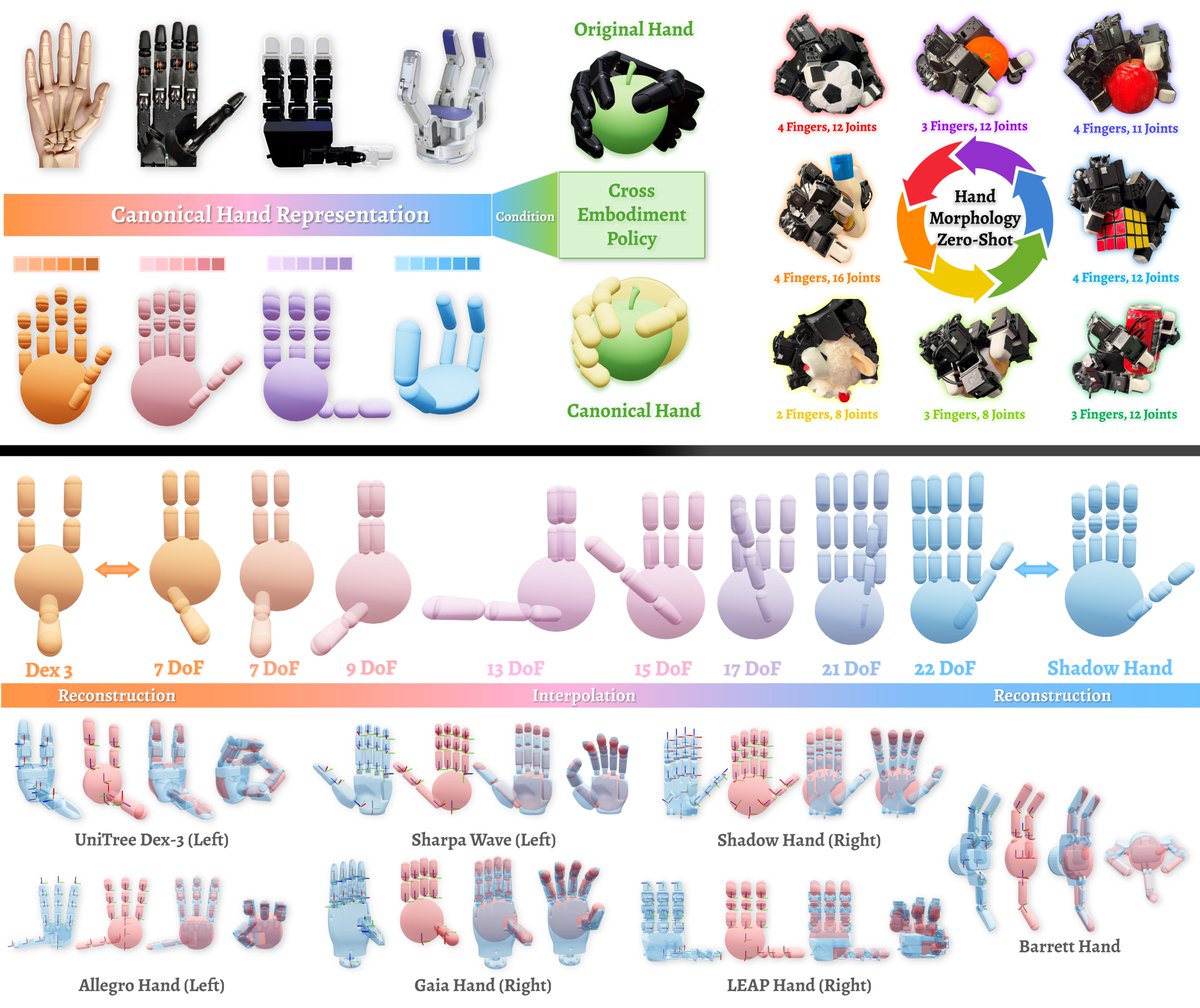
Introducing OHRA (One Hand to Rule Them All) — a canonical representation that unifies diverse dexterous robot hands into a shared space, enabling cross-hand policy transfer and up to 81.9% zero-shot generalization to unseen morphologies
🌐https://t.co/tGDsCKsQ9L
arxiv 2602.16712
Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]
Introducing FOFPred — a language-driven future optical flow prediction framework that enables improved robot control and video generation.
Instead of reacting to motion, FOFPred predicts how motion will evolve — conditioned on natural language.
🌐 Project: https://t.co/Y1Zg1TYY3s
📄 Paper: https://t.co/DjVvaFGGa8
💻 Code: https://t.co/t5fydFQK1P
🤗 Model: https://t.co/u8jGW8usMv
🕹️ Demo: https://t.co/i0OEhzxsmE
🧵[1/3]
What if we can simulate an *interactive 3D world*, from a single image, in the wild, in real time?
Introducing PointWorld-1B: a large pre-trained 3D world model that predicts env dynamics given RGB-D capture and robot actions.
🌐 https://t.co/ShGZm3hAWi
from @Stanford@nvidia
🤖Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
We introduce joint learning with motion image diffusion that enhances VLA models with motion reasoning capabilities.
📄Paper: https://t.co/4J6Mamfmyg
🌐Project: https://t.co/1G1fkZ7HSX
Key Highlights
🧠Our method seamlessly augments VLA models with motion reasoning capabilities, while preserving their real-time inference efficiency.
🔎We present motion image diffusion using a DiT, providing dense pixel-level dynamic supervision that complements sparse action supervision. We show that the optical-flow-based motion images are the most effective representation for joint action-motion learning.
🎯We enhance π-series VLA models to achieve 97.5% average success on LIBERO and 58.0% on RoboTwin.
#VLA #Robotics #Motion





















![yuffishh's tweet photo. 🤖Real-world Experiments
We study different aspects of language grounding. Each scene is designed with three possible tasks: one well-learned in-domain task with sufficient demonstrations, and two under-observed tasks defined by counterfactual instructions.
Across object recognition, spatial reasoning, goal targeting, out-of-distribution generalization, and long-horizon reasoning, our proposed CAG consistently improves the performance of pi0.5 and reduces counterfactual failures.
[5/6]](https://pbs.twimg.com/media/HDADSTgXUAAHPVF.jpg)
![TongPetersb's tweet photo. Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]](https://pbs.twimg.com/media/HClL4cFbEAA3PHP.png)




















