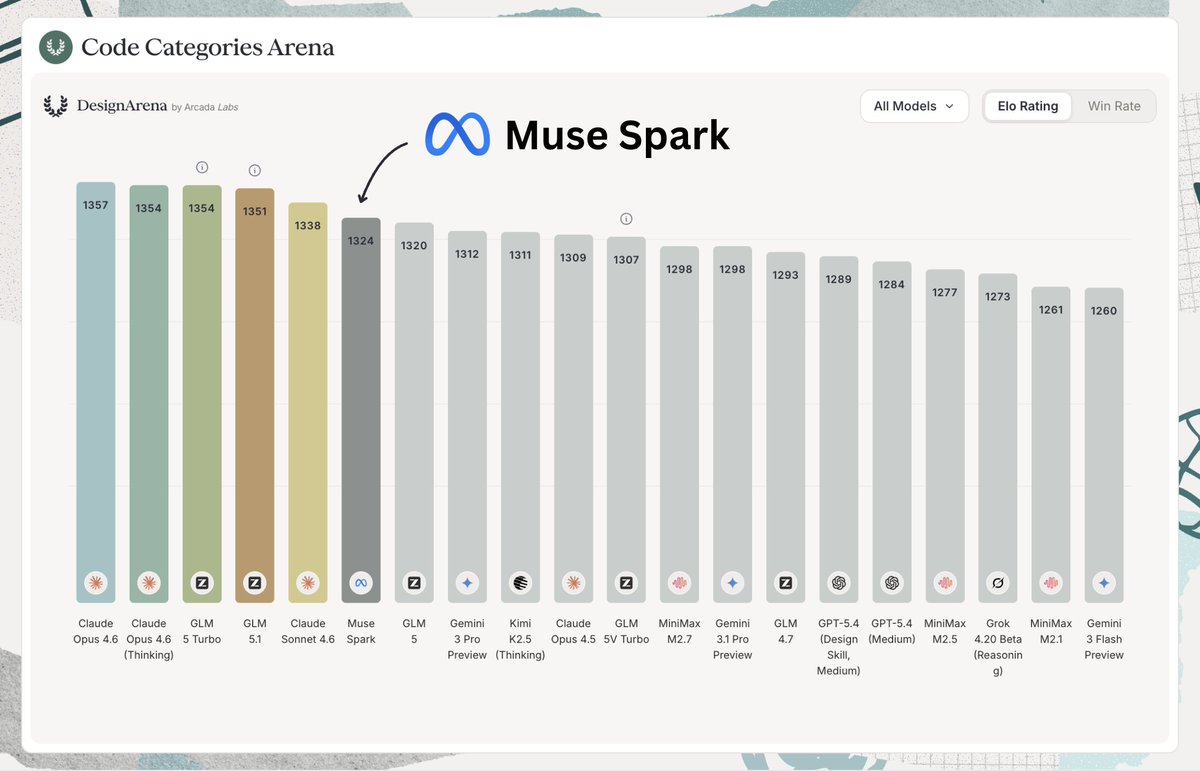
Muse Spark debuts at #7 in the Code Arena - making @AIatMeta the #3 lab right behind @AnthropicAI’s Claude Sonnet 4.6 and @Zai_org’s GLM-5.1, surpassing Gemini-3.1-Pro and GPT-5.4.
Code Arena evaluates agentic coding on real-world tasks - building live websites and apps, ranked by users on real workflows. Huge congrats to @AIatMeta on this impressive milestone!
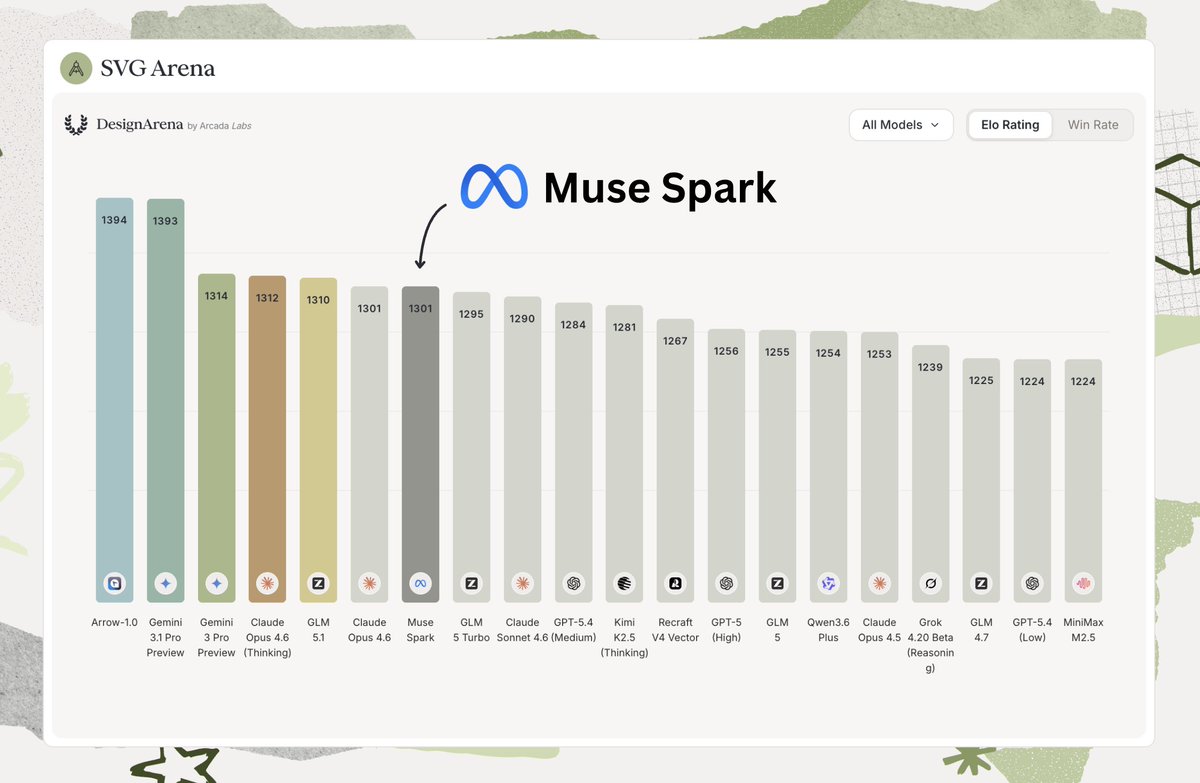
BREAKING: Muse Spark by @Meta is #7 on SVG Arena with an Elo of 1301!
This is in the same performance band as Claude Opus 4.6 by @AnthropicAI and GLM 5 Turbo by @Zai_org
Congrats to the @AIatMeta team on the launch!
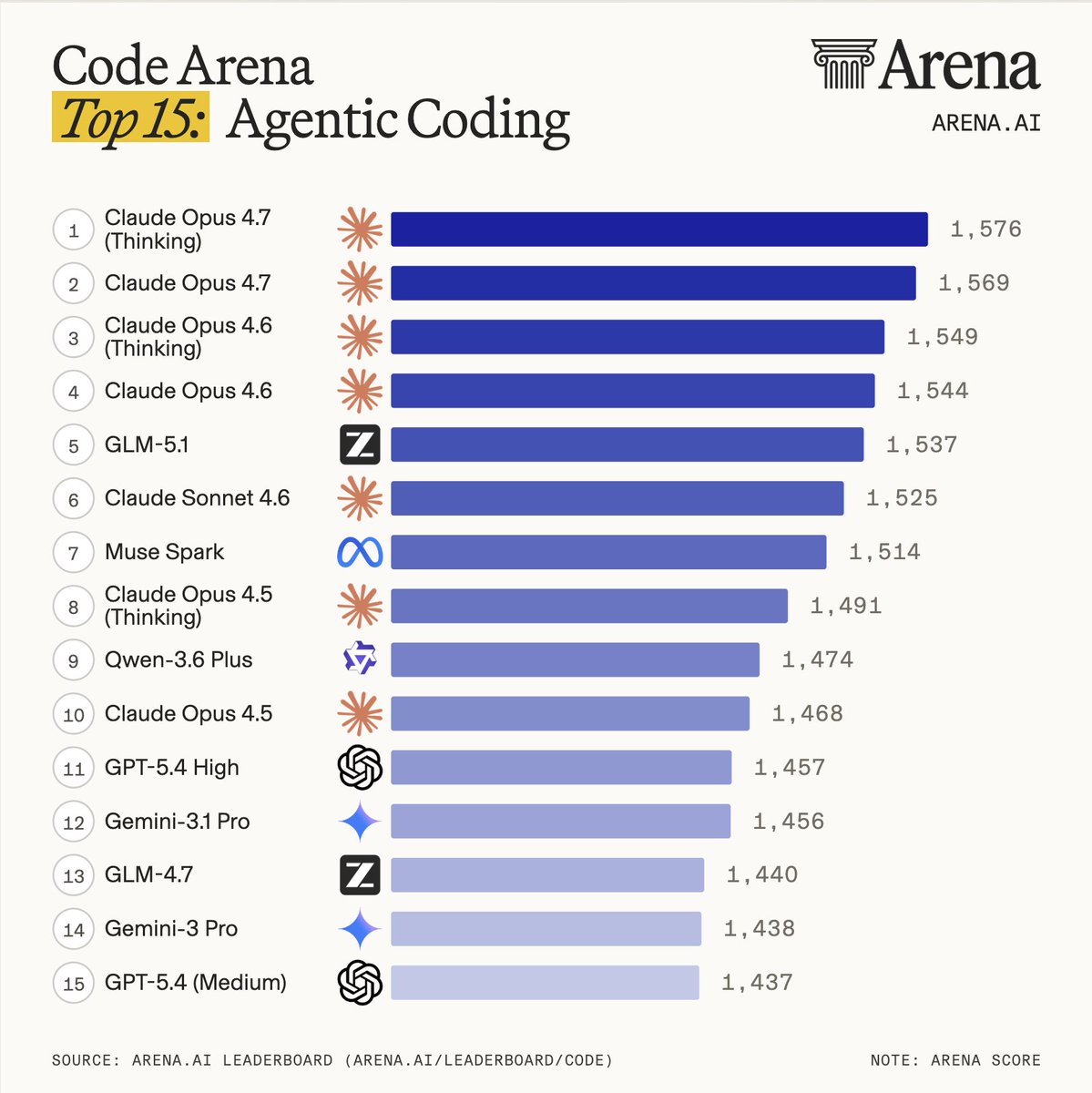
BREAKING: Muse Spark by @Meta is #6 overall on Design Arena with an Elo of 1324!
This is the single biggest improvement we've seen on Design Arena to date, with a jump of 103 positions and 374 Elo points
Huge congrats to the @Meta team on the launch!
After MORE THAN A YEAR, Meta finally released a model that passes the Hexagon Test and I’m not gonna lie this is weirdly emotional 🥹
sorry guys but history had to be documented!!
Ok this is actually pretty impressive and I truly didn't see any model doing this before or being able to do it to this extent.
When I asked Muse Spark from Meta to convert this image into code, it cut out the assets from the screens so it could use them correctly!
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
Training on issue-solving only does NOT guarantee transfer to other tasks.
🎨Introducing Hybrid-Gym - synthetic training tasks for generalization (https://t.co/IrqQszPEYm)
+25.4% on SWE-Bench / +7.9% on SWT-Bench / +5.1% on Commit-0 with NO issue-solving / test-gen/... training
I was laid off by Meta today. As a Research Scientist, my work was just cited by the legendary @johnschulman2 and Nicholas Carlini yesterday.
I’m actively looking for new opportunities — please reach out if you have any openings!
What if LLMs knew when to stop? 🚧
HALT finetuning teaches LLMs to only generate content they’re confident is correct.
🔍 Insight: Post-training must be adjusted to the model’s capabilities.
⚖️ Tunable trade-off: Higher correctness 🔒 vs. More completeness 📝
with @AIatMeta 🧵
How to construct repo-level coding environments in a scalable way?
Checkout RepoST: an automated framework to construct repo-level environments using Sandbox Testing (https://t.co/jlLXPacQE9)
Models trained with RepoST data can generalize well to other datasets (e.g., RepoEval)
📢My New Paper: Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder
TLDR: We proposed to use features from SAEs as a measure for data diversity&complexity and proved it's effectiveness on data selection for LLM tuning.
https://t.co/4yD89OYHf4
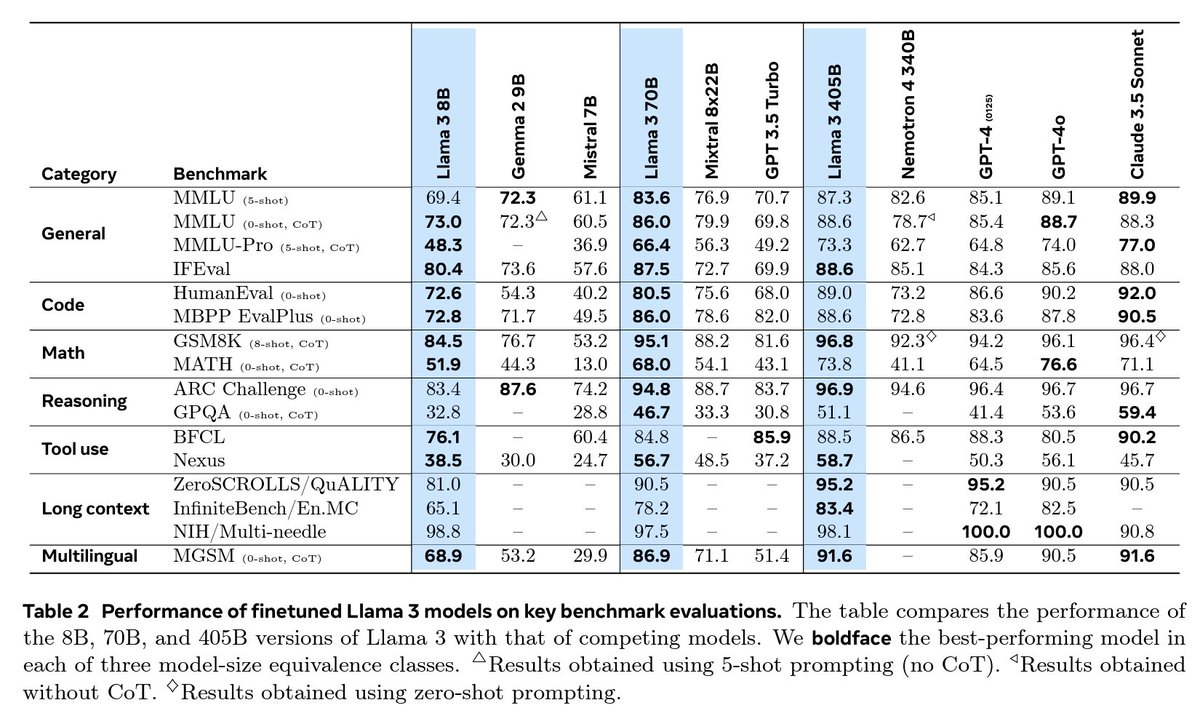
Among the most impressive aspect of the Llama 3.1 release is the accompanying research paper! Close to 100 pages of deep knowledge-sharing on LLMs like we havn't seen very often recently
What a treat!
It covers everything, pretrainining data, filtering, annealing, synthetic data, scaling laws, infrastructures, parallelism, training recipees, post-training adaptation, tool-use, benchmarking, inference strategies, quantization, vision, speech, videos...
Mind-blown! Maybe the single paper you can read today to join the field of LLM from zero right to the frontier
Read it here and feel the open-science https://t.co/nANpZtiP0s
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet.
Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context window and improved support for 8 languages among other improvements. Llama 3.1 405B rivals leading closed source models on state-of-the-art capabilities across a range of tasks in general knowledge, steerability, math, tool use and multilingual translation.
The models are available to download now directly from Meta or @huggingface. With today’s release the ecosystem is also ready to go with 25+ partners rolling out our latest models — including @awscloud, @nvidia, @databricks, @groqinc, @dell, @azure and @googlecloud ready on day one.
More details in the full announcement ➡️ https://t.co/hhJoLm5eLV
Download Llama 3.1 models ➡️ https://t.co/rRjvmxqCTC
With these releases we’re setting the stage for unprecedented new opportunities and we can’t wait to see the innovation our newest models will unlock across all levels of the AI community.
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3 models — in the coming months we expect to introduce new capabilities, longer context windows, additional model sizes and enhanced performance + the Llama 3 research paper for the community to learn from our work.
More details ➡️ https://t.co/nFll4exicO
Download Llama 3 ➡️ https://t.co/Ps0OAHt0RR
Introducing 🌈 Rainbow Teaming, a new method for generating diverse adversarial prompts for LLMs via LLMs
It's a versatile tool 🛠️ for diagnosing model vulnerabilities across domains and creating data to enhance robustness & safety 🦺
Co-lead w/ @sharathraparthy & @_andreilupu