Human intelligence is fundamentally a collective intelligence. We solve complex problems by participating in a vast cultural network that builds upon ideas across generations.
I believe the strongest AI systems will become a collective intelligence, too.
Since we started Sakana AI, our core conviction has been that the most powerful AI systems will be collaborative ecosystems, not isolated monoliths. Evolution innovates under constraints, and the future belongs to systems that explicitly learn how to coordinate collective intelligence.
Today, we are taking a major step toward that future with the launch of Sakana Fugu.
Fugu dynamically orchestrates the world’s best models to tackle complex tasks. We are proving that a well-orchestrated pool of swappable agents can match restricted frontier models like Fable and Mythos.
But Fugu is about more than just performance. I believe that Orchestration Models are the next frontier, beyond bigger models.
Relying on a single company’s model for national infrastructure is a massive risk. As recent export controls have shown, access to top models can disappear overnight.
Collective intelligence is the practical hedge against this concentration of power. Fugu simply routes around vendor restrictions by relying on an entirely swappable agent pool.
I am incredibly proud of our Tokyo team for shipping this. By orchestrating the world’s models, we are delivering the resilient blueprint required for AI sovereignty.
Read our full vision and results here:
https://t.co/EONDdWx5Ld 🐡
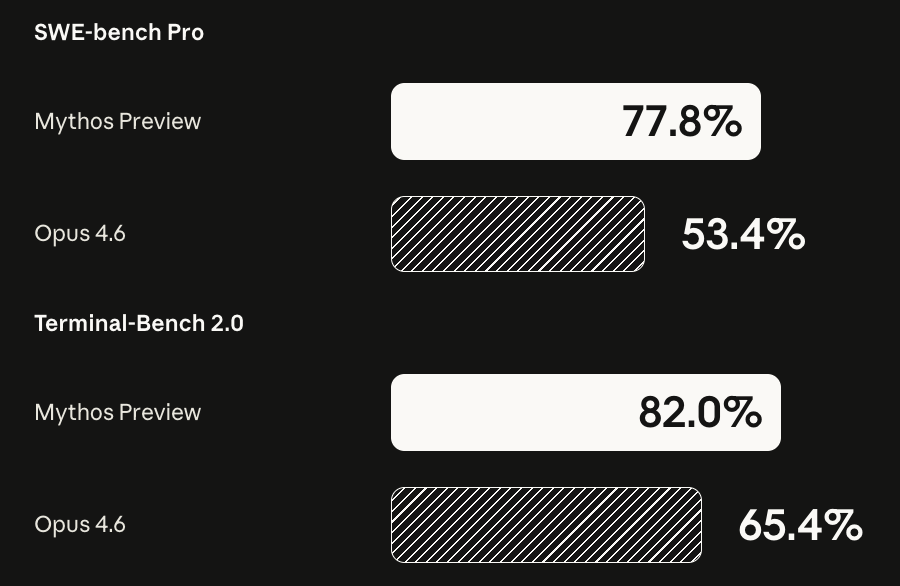
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks.
Read the full blog: https://t.co/2ZJbdWqCUj
Beyond Bigger Models: Why are Orchestration Models the Next Frontier
Progress in AI has been driven largely by giant, monolithic models. But the most powerful systems of the future will be collaborative ecosystems.
Today, this orchestration is no longer just a technical optimization. It has become a geopolitical and operational imperative.
For an organization or a nation, relying on a single company's model for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality.
As we have seen with recent export controls imposed on models like Fable and Mythos, access can disappear overnight.
Collective intelligence is the practical hedge against this concentration of power. Because Fugu orchestrates an underlying pool of swappable agents, it simply routes around vendor restrictions.
By orchestrating the world’s models, we are delivering the resilient blueprint required for true AI sovereignty.
김정호 교수의 분석 핵심은 명확해요. AI 컴퓨팅의 병목은 이제 연산(GPU)이 아니라 데이터 소통(메모리)입니다.
HBM → HBF(2028년경) → HBS까지 수직 적층하는 ‘메모리 타운’이 피지컬 AI 시대의 핵심 인프라가 될 전망.
한국이 여기서 리더십을 유지하면 Musk의 Optimus 같은 자율 로봇 비전 실현에도 결정적 역할을 할 수 있어요. US 견제 리스크는 사실이지만, 기술 격차를 더 벌리는 실행력이 관건입니다.
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
Great to see our collaboration w/ @BostonDynamics unlocking new capabilities! Gemini Robotics-ER 1.6 enables robots like Spot to read complex industrial gauges autonomously. Exciting step toward robots that can understand & operate usefully in the physical world
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
Thank you Jensen and NVIDIA! She’s a real beauty! I was told I’d be getting a secret gift, with a hint that it requires 20 amps. (So I knew it had to be good). She’ll make for a beautiful, spacious home for my Dobby the House Elf claw, among lots of other tinkering, thank you!!
AI가 AI를 개선하기 시작했다
안드레 카파시가 3일 전 자리를 비웠다.
에이전트한테 일을 맡기고. 지켜보지도 않고
자러 가버렸다
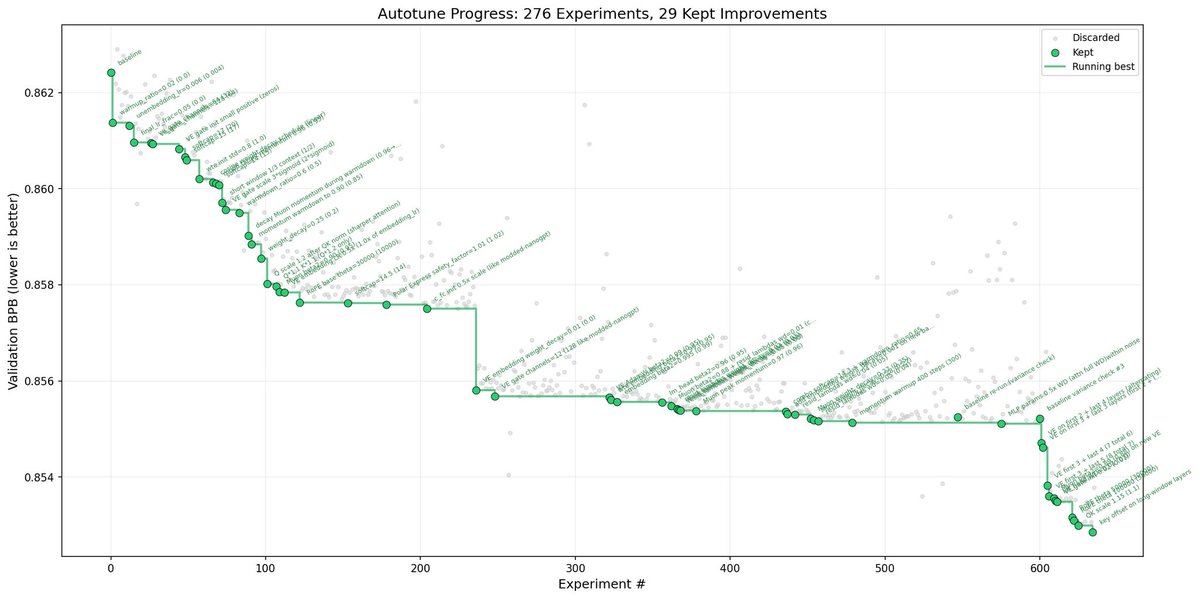
48시간 후 돌아왔을 때, 에이전트는 700번의 실험을 혼자 마쳤다. 그리고 20가지 개선사항을 찾아냈다.
카파시는 무슨 일을 시켰나?
카파시는 "nanochat"이라는 자신의 LLM 훈련 프로젝트를 갖고 있다. 그리고 AI 모델을 얼마나 빠르고 효율적으로 훈련시킬 수 있는지 경쟁하는 리더보드가 있다. 지표는 "GPT-2 수준 모델을 만드는 데 걸리는 시간". 카파시의 기존 기록은 2.02시간이었다.
그가 에이전트한테 시킨 건 단순했다. "https://t.co/apy1suKq4b 파일을 수정해봐. 5분짜리 미니 훈련 돌려봐. 결과가 나아지면 유지하고, 나빠지면 버려. 반복해."
에이전트는 그걸 700번 했다.
결과: 2.02시간 → 1.80시간. 11% 개선했고 새 리더보드 기록을 세웠다
에이전트가 발견한 것들
카파시 본인이 "오류"라고 인정한 것들이 포함됐다.
QK 정규화에 스케일 승수가 빠져있었다. 어텐션이 너무 분산돼 있었다. Value 임베딩에 정규화가 전혀 적용되지 않고 있었다. Banded attention 파라미터가 너무 보수적으로 설정돼 있었다. AdamW 베타값이 잘못 설정돼 있었다. 가중치 감쇠 스케줄, 네트워크 초기화도 개선됐다.
이게 흥미로운 이유는 카파시가 세계 최고의 AI 연구자라는 거다. 매일 이런 걸 손으로 직접 튜닝해왔다. 근데 에이전트가 그가 놓친 것들을 찾아냈다.
카파시가 포스트에 글하나를 남겼다.
"Who knew early singularity could be this fun?"
지금까지 AI 연구의 공식은 이랬다.
사람이 아이디어를 낸다 → 구현한다 → 결과를 확인한다 → 논문을 읽는다 → 새 아이디어를 낸다.
카파시는 20년간 이걸 반복했다. "내 일상의 핵심"이라고 했다.
그 사이클을 에이전트가 통째로 가져갔다.
에이전트는 실험 결과를 보고 다음 실험을 계획했고, 실패한 실험에서 배웠다. 성공한 방향을 강화했다. 사람이 개입하지 않았다.
카파시의 결론은 더 무겁다:
"All LLM frontier labs will do this. It's the final boss battle."
모든 최전선 AI 연구소가 이걸 할 것이다. 이게 마지막 전투다.
"마지막 전투"가 무슨 뜻인가
에이전트 스웜을 만든다. 작은 모델을 튜닝하게 한다. 가장 유망한 아이디어를 더 큰 모델로 끌어올린다. 사람은 가장자리에서 선택적으로 개입한다.
이게 작동하면 어떤 일이 벌어질까?
AI가 스스로를 개선한다. AI가 더 좋아지면 더 잘 AI를 개선한다. 그게 또 더 잘 개선한다.
카파시는 이걸 "autoresearch"라고 부른다. 630줄짜리 파이썬 코드. 오픈소스. 지금 GitHub에 있다.
나는 지난번 포스트에서 "카파시가 터미널을 닫고 에이전트에 맡겼다"고 썼을 때
나는 그게 새 시대의 시작이 아닐까? 라고 쓴적이 있다.
그리고 정확히 그 일이 계속 벌어졌다.
그는 2일 동안 자리를 비웠다. 에이전트가 700번의 실험을 했다. 그가 놓쳤던 버그를 찾았다. 20년 경력자가 수동으로 튜닝하지 못한 것들을 개선했다.
이건 AI가 "도움을 주는" 이야기가 아니다. AI가 연구자의 역할을 대신한 이야기다.
Andrej Karpathy는 OpenAI 공동창업자다. 테슬라 AI 책임자였다. AI 분야에서 그가 하는 말은 곧 트렌드가 된다.
그가 "에이전트한테 맡겼다"고 말하는 순간, 수십만 명이 따라한다. 이미 autoresearch 깃헙에 수천 개의 스타가 달렸다.
하지만 진짜 포인트는 다른 곳에 있다.
카파시가 20년을 해온 일을 에이전트가 이틀에 했다. 그리고 더 잘했다는 것이다
이건 개발자들의 이야기가 아니다. 이건 우리 모두의 이야기다.
당신이 20년 동안 반복해온 일이 있다면 에이전트가 그걸 보고 있지는 않을까?
출처: Andrej Karpathy X 포스트 (@karpathy, 2026.3.7~3.9), https://t.co/weLGHoDNLM, https://t.co/kI4boUjUMU, Hacker News, Reddit r/LocalLLaMA
Ten years ago, AlphaGo’s legendary match in Seoul heralded the start of the modern era in AI. Its famous ‘Move 37’ signaled to us that AI techniques were ready to tackle real-world problems in areas like science - and ideas inspired by these methods are critical to building AGI
세상에서 가장 중요한 석사 논문을 쓴 사람
1937년, 미시간 출신의 스물한 살짜리 대학원생이 MIT에서 석사 논문 하나를 제출했다.
논문 제목은 거창했다. "A Symbolic Analysis of Relay and Switching Circuits" 릴레이와 스위칭 회로의 기호 분석.
아무도 주목하지 않았다. 교수들은 대충 읽었고, 대충 그렇구나 하고 통과시켰고, 대충 넘어갔다.
하지만 역사는 다르게 기록했다.
수십 년 뒤, 이 논문은 "역사상 가장 중요한 석사 논문"으로 불리게 됐다. 전기 스위치와 수학적 논리를 연결한 이 아이디어가 디지털 컴퓨팅 전체의 이론적 기반이 됐기 때문이다.
그 스물한 살짜리 이름은 Claude Elwood Shannon이었다.
노이즈 속에서 신호를 찾은 사람
1948년 섀넌은 벨 연구소에서 또 다른 논문을 발표했다.
"A Mathematical Theory of Communication"
Scientific American은 이것을 "정보화 시대의 마그나카르타"라 불렀다. 전기공학자 Robert Gallager는 "디지털 시대의 청사진"이라 했다.
이 논문에서 섀넌은 정보를 수학으로 정의했다.
그 당시 과학계 에서는 정보는 추상적인 것이었다. 의미도 없고 측정할 수 없는 것으로 여겨졌다. 그리고 인포메이션이라는 용어도 이때 쯤 나오게 된다.
섀넌은 달리 봤다. 정보는 불확실성의 감소다. 당신이 몰랐던 것을 알게 되는 순간 그것이 정보다. 그리고 그 양은 정확하게 계산할 수 있다.
그는 이것을 엔트로피(entropy)라고 불렀다. 물리학에서 빌려온 개념이었지만 의미는 완전히 달랐다.
그리고 그 단위를 비트(bit)라고 이름 붙였다. 비트코인, 비트, 연산 우리가 알고 있는 비트 말이다.
0 아니면 1
지금 당신이 읽고 있는 이 텍스트. 당신 손 안의 스마트폰. 인터넷의 모든 데이터. 인공위성의 통신. 전부 섀넌이 1948년에 정의한 비트의 흐름으로 귀결이 된다.
그는 혼자서, 서른두 살에, 디지털 세계의 언어를 발명했다.
그의 취미는 복도에서 외발자전거를 타는 것이였다.
섀넌의 동료들은 그를 회상할 때 항상 같은 장면을 떠올린다.
벨 연구소 복도. 수학 증명으로 가득한 칠판 옆을 외발자전거를 타고 지나가는 남자. 동시에 공 네 개를 저글링하면서.
그는 로켓 추진 프리스비를 발명했다. 마음을 읽는 기계를 만들었다. 미로를 스스로 탈출하는 전자 쥐 "Theseus"를 만들어 인공지능의 원형을 시연했다. 투자자들이 몰려올 것을 예측해 주식으로 재산을 모으기도 했다.
그는 천재였다. 하지만 우리가 아는 천재의 이미지 어둡고 고독하고 비장한 와는 달랐다.
섀넌은 발명을 즐거워했다.
발명은 그에게 장난이었다. 수학은 놀이였다. 연구실은 놀이터였다. 그는 문제를 풀기 위해 연구하는 게 아니라 궁금해서 연구했다.
그리고 그 즐거움이 세상을 바꿨다.
섀넌은 세상을 바꿀 논문을 썼다. 하지만 그는 세상을 바꾸려고 쓴 게 아니었다. 그냥 궁금했다. "정보를 수학으로 표현할 수 있을까?" 그 질문이 즐거웠다고 한다.
그 즐거움이 1948년의 논문이 됐다. 그 논문이 디지털 혁명의 기반이 됐다.
섀넌은 2001년 2월 24일, 84세로 세상을 떠났다. 알츠하이머로 인한 합병증이었다. 하지만 그가 남긴 것은 사라지지 않았다. 오히려 계속 커지고 있다.
지금 당신이 이 글을 읽는 데 도움을 준 것이 있다.
요약하고, 분석하고, 설명하고, 글을 쓰는 세계 최고의 AI 모델
그 AI 모델의 이름은 @claudeai 다.
@AnthropicAI 의 공식 입장을 Wikipedia는 이렇게 기록하고 있다.
"It is named after Claude Shannon, who pioneered information theory."
"수학자 클로드 섀넌에게 경의를 표하기 위해, Anthropic이 선택한 이름이다."
섀넌은 1948년에 비트를 발명했다. 정보를 수학으로 정의했다. 그 정의 위에 컴퓨터가 나오고, 인터넷이 나오고, 스마트폰이 나왔다.
그리고 그 모든 것의 위에 지금의 AI가 나왔다..
세상에서 가장 중요한 석사 논문을 쓴 스물한 살짜리. 복도에서 외발자전거를 탄 천재. 정보를 수학으로 만든 남자.
그의 이름은 클로드였다.
그리고 그 이름은 아직 살아있다.
출처: Claude Shannon Wikipedia / IEEE Information Theory Society / Scientific American "Father of Information Theory" / IEEE Spectrum "Tinkerer, Prankster" / Reddit r/ClaudeAI "Why is it named Claude?" (2024-07) / Wikipedia Claude (language model)
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
💬 저도 모르게 한 학기 분량의 학습을 48시간으로 압축하는 방법을 발견하게 됐어요.
MIT 대학원생이 자신의 NotebookLM 활용 방식을 보여줬는데, 처음엔 그냥 정리를 잘하는 사람이라고만 생각했죠. 그런데 그가 한 번도 공부한 적 없는 분야의 자격시험을 통과하는 걸 직접 목격했어요.
그가 정확히 어떻게 했는지 공유할게요.
첫째, 교재 한 권을 올리지 않았어요.
교재 6권, 논문 15편, 그리고 해당 주제와 관련해 찾을 수 있는 모든 강의 스크립트를 업로드했죠.
그리고 NotebookLM에 딱 하나의 질문을 던졌어요.
> "이 분야의 모든 전문가가 공유하는 핵심 멘탈 모델 5가지는 무엇인가요?"
"요약해줘"도 아니고, "이 주제를 설명해줘"도 아니었어요.
멘탈 모델. 교수들이 수년에 걸쳐 쌓는 그 사고 체계 말이에요.
그런데 다음 단계가 진짜 충격이었어요.
이렇게 이어서 물었거든요.
> "이제 이 분야에서 전문가들이 근본적으로 의견이 갈리는 세 가지 지점을 보여주고, 각 입장의 가장 강력한 논거를 설명해주세요."
20분 만에 그 분야 전체의 지적 지형도가 완성됐어요.
논쟁의 핵심, 학계의 합의, 아직 열린 질문들까지.
대부분의 학생들은 그 논쟁이 무엇인지 파악하는 데만 한 학기를 쓰거든요.
그리고 그 다음, 제가 한 번도 본 적 없는 방식을 꺼냈어요.
이렇게 물은 거예요.
> "이 주제를 깊이 이해한 사람과 단순히 암기한 사람을 구별할 수 있는 질문 10가지를 만들어주세요."
이후 6시간 동안 그 질문들에 소스 자료를 활용해 직접 답변했어요. 틀린 답변이 나올 때마다 이렇게 후속 질문을 던졌죠.
> "왜 이게 틀렸는지, 그리고 제가 놓친 게 뭔지 설명해주세요."
48시간이 지났을 때, 그는 지도교수와 대화를 나눌 수 있는 수준이 되어 있었어요.
도구가 달라진 게 아니에요. 질문이 달라진 거예요.
대부분의 사람들은 NotebookLM을 멋진 형광펜 정도로 사용해요.
이 학생들은 해당 주제에 관한 모든 것을 읽은 개인 튜터처럼 활용하고 있었죠.
한 학기와 48시간의 차이는 콘텐츠의 양이 아니에요.
어떤 질문을 던져야 하는지를 아는 것, 그게 전부예요.
안드레이 카파시의 Agentic Coding 원칙을 누군가 Skills로 만들어서 VS Code 플러그인으로 배포했네요. 👍 댓글에 github 주소도 남깁니다.
[사용 방법]
설치 후 명령 팔레트(Ctrl+Shift+P / Cmd+Shift+P)를 엽니다.
- Karpathy 규칙: 프로젝트에 추가(.cursor/rules) — .cursor/rules/ 파일에 alwaysApply: true로 가이드라인을 추가합니다(Cursor 사용 시 권장).
- Karpathy 규칙: .cursorrules에 추가(레거시) — 프로젝트 루트의 .cursorrules 파일에 추가합니다.
[이 스킬의 4가지 원칙]
1) 코딩 전 생각하기 — 추측하지 말고, 장단점을 명확히 파악하고 불분명한 점은 질문하세요.
2) 단순성 우선 — 최소한의 코드만 작성하고, 불필요한 기능이나 추상화를 배제하세요.
3) 정밀한 수정 — 필요한 부분만 수정하고, 관련 없는 코드는 "개선"하지 마세요.
4) 목표 중심 실행 — 성공 기준을 정의하고 (테스트 등을 통해) 검증하세요.
[Tesla Korea 채용공고 - AI Chip Design Engineer]
Tesla에서 세계 최고 수준의 대량 생산 AI 칩 개발에 함께할 인재를 찾습니다.
해당 프로젝트는 향후 세계에서 가장 높은 생산량을 기록할 AI 칩 아키텍처 개발을 목표로 합니다.
📌 모집 직무
AI Chip Design Engineer
📌 지원 방법
아래 내용을 포함하여 [email protected] 이메일 지원
- 본인이 해결했던 가장 어려운 기술적 문제 3가지

























![ShonerStyle's tweet photo. 안드레이 카파시의 Agentic Coding 원칙을 누군가 Skills로 만들어서 VS Code 플러그인으로 배포했네요. 👍 댓글에 github 주소도 남깁니다.
[사용 방법]
설치 후 명령 팔레트(Ctrl+Shift+P / Cmd+Shift+P)를 엽니다.
- Karpathy 규칙: 프로젝트에 추가(.cursor/rules) — .cursor/rules/ 파일에 alwaysApply: true로 가이드라인을 추가합니다(Cursor 사용 시 권장).
- Karpathy 규칙: .cursorrules에 추가(레거시) — 프로젝트 루트의 .cursorrules 파일에 추가합니다.
[이 스킬의 4가지 원칙]
1) 코딩 전 생각하기 — 추측하지 말고, 장단점을 명확히 파악하고 불분명한 점은 질문하세요.
2) 단순성 우선 — 최소한의 코드만 작성하고, 불필요한 기능이나 추상화를 배제하세요.
3) 정밀한 수정 — 필요한 부분만 수정하고, 관련 없는 코드는 "개선"하지 마세요.
4) 목표 중심 실행 — 성공 기준을 정의하고 (테스트 등을 통해) 검증하세요.](https://pbs.twimg.com/media/HCS6leibEAU8y-d.jpg)






























