Today we're introducing the LLM Stats Index.
For 3.2 years, we've tracked every frontier model release. The Index aggregates 200+ benchmark results into a single TrueSkill rating per model, spanning law, healthcare, coding, tool calling, vision, and reasoning.
Across every category and every modality, the leading model on the Pareto Frontier is GPT-5.5 (@OpenAI).
On our trajectories, human-knowledge benchmarks saturate by mid-2027.
Capability has been the primary axis. The field is converging on it. Two more are opening.
The first is efficiency: total task cost is the cleanest proxy we have for intelligence/watt. The second is throughput: inference speed becomes the productivity ceiling once models are cheap and good enough.
We're building the next generation of long-horizon coding, tool use, and long context benchmarks.
If you're working on long-horizon evaluation in real domains, we'd like to chat.
The companies that win the next decade of AI won’t be those that build the best agents. They’ll be the ones whose agents get better over time.
Agents should grow, not just get shipped and maintained.
We're so early. We're building for the long run.
what if your agents could learn from their mistakes, and get better over time?
companies are shipping agents to production at a higher rate than ever, and teams keep running into the same issues:
incorrect tool calls, low prompt adherence, hallucinations, etc
we're closing this loop with @ZeroEval.
A Failure-Focused Evaluation of Frontier Models
Benchmark scores tell you which model is "best on average", but not where they fail.
We reproduced a set of difficult evaluations on seven frontier models to investigate two signals: consistent failures and task-specific advantages.
Our findings:
→ 85.2% average failure rate on Humanity’s Last Exam across all seven models evaluated.
→ 46.2% of Humanity’s Last Exam questions were failed by all seven models under these evaluation conditions.
→ Nearly 80% of engineering problems, including structural analysis, thermodynamics, and control systems, remained unsolved by all models.
Let’s dig deeper (1/8)
How does the Veo 3 family stack up in video generation? 🎬
I ran a series of tests to understand the capabilities of this model lineup.
To my surprise, despite being part of the same family, there are significant differences in how each version approaches and solves the same prompt.
Tested 4 different versions of Google's Veo to see which one handles video generation best:
✅ Veo 3.1
✅ Veo 3.1 Fast
✅ Veo 3.0
✅ Veo 3.0 Fast
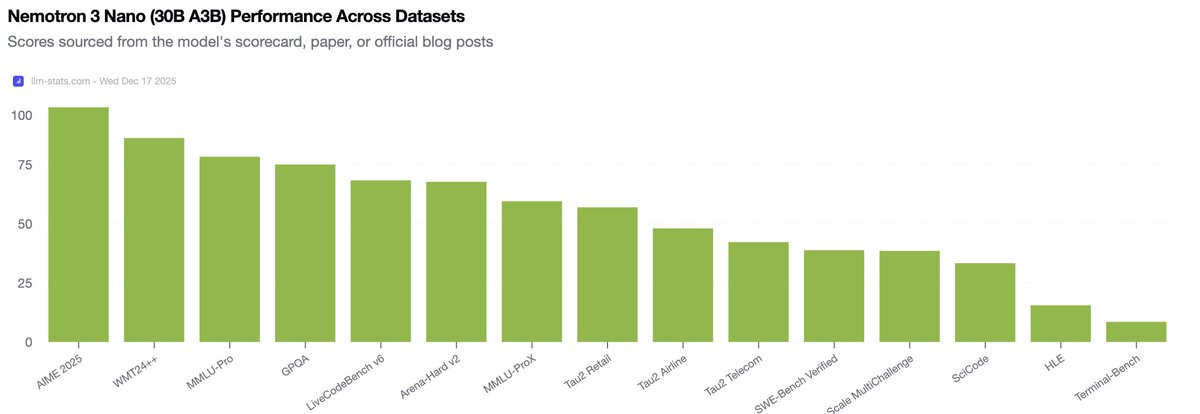
🟩 Nemotron 3 Nano is out:
→ Hybrid Mamba-Transformer architecture: longer context that stays fast and cheap.
→ 31.6B params but only 3.6B active per token: frontier-adjacent performance at fraction of compute.
→ 4x faster inference than Nemotron 2 Nano
→ Open weights available through HF
Info: https://t.co/v4riTy9Dgz
Blog: https://t.co/T2WA0EF5Wv
what if you could teach the ai that powers your products on what's good and what's bad?
after chatting with hundreds of AI co's about prompt engineering, the same things comes up again and again: 95% of them are purely vibe prompting and hate the process.
we just built a new feature for @ZeroEval that lets you improve your prompts through human feedback, powered by @DSPyOSS.
plug into our sdk, give feedback (ui, sdk or api) and generate prompt improvements. as easy as that.
let me show you how it works
LLM Stats is live on Product Hunt 🥳🎉
We're doubling down on independent benchmarking for AI models and bringing transparency and reproducibility to model performance.
Are there any benchmarks you'd like to see or wish existed? Reply below.
https://t.co/ABNNBCrmZd
➡️ ZeroEval / @ZeroEval
If you want AI agents that actually get smarter, this is it!
ZeroEval builds agents that learn from their mistakes. It runs evaluations that train your models to improve over time, no retraining needed.
𝜃 @ZeroEval helps you build reliable AI agents through evaluations that learn from their mistakes and get better over time.
https://t.co/aYaAVMBvZf
Congrats on the launch, @sebcrossa and @pirchavez!