@DirhousssiAmine@hgoel1000 If it works with 1e-5 then is it the case that the total update with the smaller learning rate goes out of the representable range in bf16 whereas when we use 1e-5 the update is still representable? By update I mean the product of the learninf rate and gradient
Our latest rerankers consistently outperform LLMs across all setups, delivering larger improvements regardless of the first-stage retriever.
Check out our blog for more insights
https://t.co/ZxPYJW1BTi
It was great to drive this effort — the results are very exciting.
Most works highlight the benefits of using LLMs for reranking, but often rely on results from weak retrieval models. When we pair rerankers with a strong retriever like voyage-3-large, those advantages disappear.
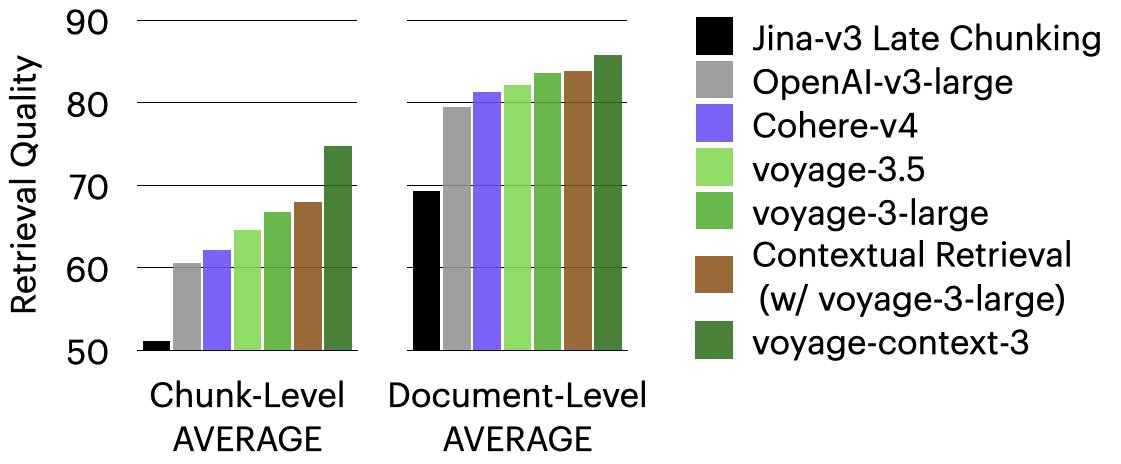
We just launched Voyage-context-3, a new embedding model that gives AI a full-document view while preserving chunk-level precision that offers better retrieval performance than leading alternatives.
When building AI that reads and reasons over documents (such as reports, contracts, or medical records), it’s critical to break those documents into smaller pieces, or “chunks,” while still maintaining an understanding of the big picture. Most systems today lose important context, or require complicated workarounds to stitch it back together.
https://t.co/OcxvTzfXah
Learning output format is easy and quickly saturates the reward — leading to zero advantage and no gradient signal (if there's no KL).
Interesting that this still seems to induce reasoning.
Any hypothesis for why that happens?
@natolambert
Arxiv: https://t.co/S5m3e6VhVQ
Clearly a lot more work is needed to understand what’s really happening with RL and prompting. We hope that our experiments with spurious rewards and spurious prompts, as well as the released code, data, checkpoints, etc. will help with this! 🔍
@shradhasgl Agreed, I think this might be because several runs are needed for RL trainings, as it is high variance. This makes it hard to reproduce the results as well. It would be interesting to see if such observations hold true after averaging over several runs.
https://t.co/2PzTuCMDp1
Agree that we need to remember the high variance of RL, as we push further into long horizon etc!
We developed metrics to help folks track RL reliability -- codebase+paper here: https://t.co/K7PXJwgKL3
📢 Meet voyage-3.5 and voyage-3.5-lite!
• flexible dim. and quantizations
• voyage-3.5 & 3.5-lite (int8, 2048 dim.) are 8% & 6% more accurate than OpenAI-v3-large, and 2.2x & 6.5x cheaper, resp. Also 83% less vectorDB cost!
• 3.5-lite ~ Cohere-v4 in quality, but 83% cheaper.
I love @karpathy , but vibe coding is a waste of time. It is good for tech bros who want to look cool, but besides rare cases, it will not make you deliver your product faster
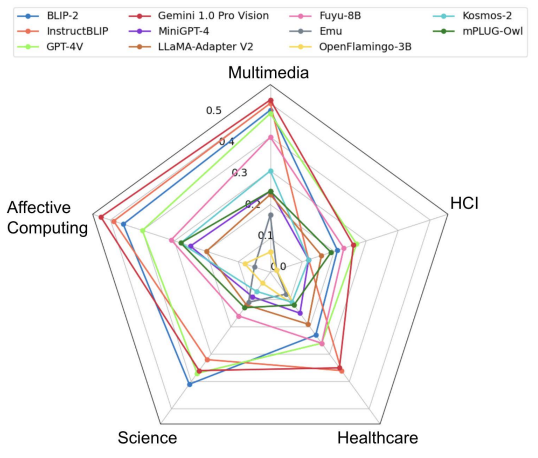
Results from our work HEMM (https://t.co/il5gIR7Q2v) resonate with the findings. Frontier models like GPT-4o struggle on Healthcare tasks, with Vision - Language Medical tasks being more challenging.
1/🧵How do we know if AI is actually ready for healthcare? We built a benchmark, MedHELM, that tests LMs on real clinical tasks instead of just medical exams. #AIinHealthcare
Blog, GitHub, and link to leaderboard in thread!
@percyliang Great insights! In our paper HEMM: Holistic Evaluation of Multimodal Foundation Models (https://t.co/il5gIR7Q2v), we show that even frontier models like GPT-4o aren’t ready for medical tasks yet. Focusing on key Image regions is challenging.
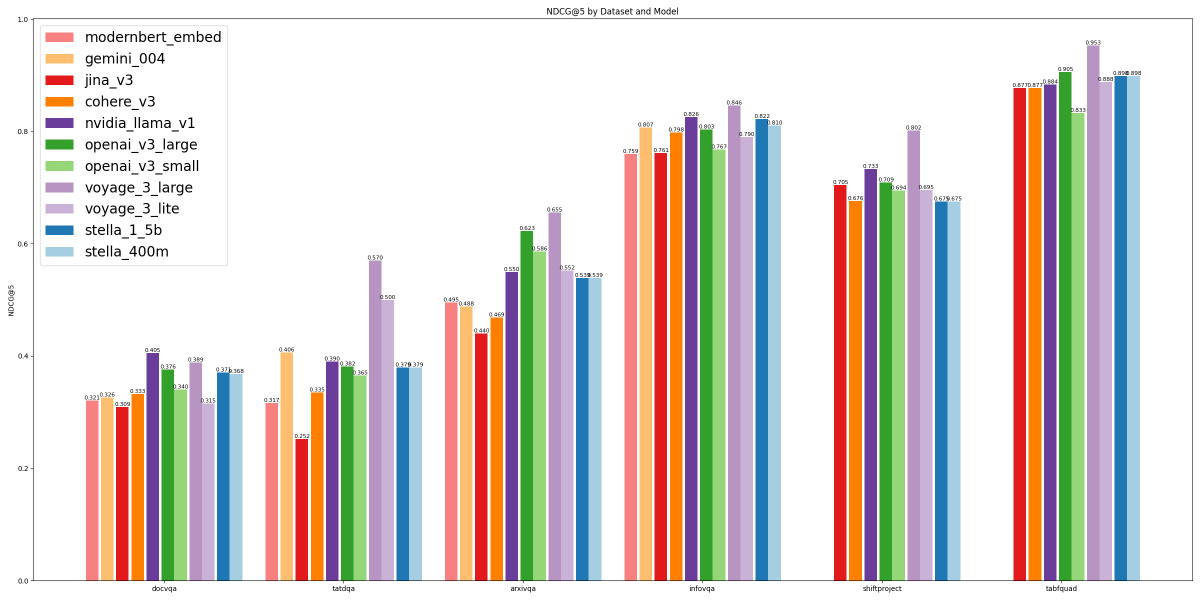
I ran a fresh evaluation of embedding models tuned for semantic retrieval, including the newest models from Voyage, Jina, Cohere, and NVIDIA.
Link in thread.