Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
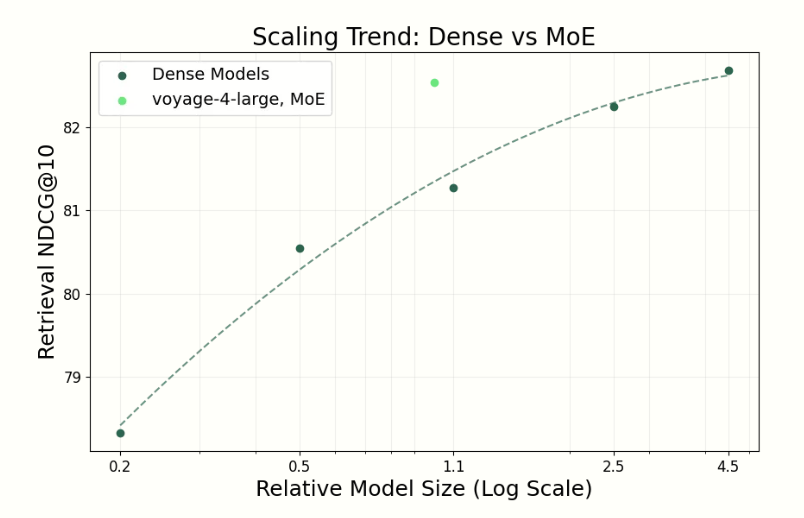
The era of embedding models is evolving. 🚀
With voyage-4-large, we’ve moved to Mixture of Experts (MoE) to shatter the scaling ceiling.
The results: ✅ Massive drop in inference cost and latency ✅ New frontier for retrieval accuracy.
Curious about how we implement MoE embeddings?
Read the full technical breakdown of how we optimized design choices to push the Pareto frontier: https://t.co/HmfYoCoUxH
A few days back, following a long line of excellent proprietary models, @VoyageAI released their 🚨 first ever open-weights embedding model for retrieval 🚨!
It's called voyage-4-nano, it's multilingual, and very efficient.
Details in 🧵
Excited to share that I'm co-founding Inferact with an incredible team! Our mission: grow vLLM as the world's leading AI inference engine💪🏻 We've got many amazing models in our day-0 support pipeline — guess what's coming next?😉
We believe AI research is a special research area AI itself can deliver significant progress. Ronald Fisher laid out the foundation for scientific methods: generating hypothesis (research ideas) and see if you can falsify the hypothesis (execution). Therefore, execution and experiments forms the basis of scientific progress. For mathematics, execution is somewhat special, the chain-of-thoughts of the AI models implicitly carries this through, which explains many progresses in math we are seeing.
For AI research, execution is purely in code, which AI is extremely at. Idea generation is in natural language, which AI can also do, although not calibrated right now. So, the natural design is to hook up "AI AI idea generator" and "AI AI experiment executor" together end-to-end. This is the future paradigm we propose.
We studied two realistic environments: nanoGPT speed run initiated by @kellerjordan0@karpathy, and GRPO math reasoning homework built by Stanford CS336 @stanfordnlp. These two "research environments" cover the salient and realistic research topics: LLM pretraining and LLM posttraining. For GRPO post-training, the algorithm discovered by AI (see details in the paper!) outperforms the highest scoring student solution (https://t.co/63T3F5tPEh). For nanoGPT, human expert are too good to compete yet, but AI does reduce the time-to-loss=3.28 from 35min to 19min (as a reference, human expert is 2min..)
The advantage of AI over human is very simple: AI is tireless. Over the past few month, our wandb log tells us that our AI researcher tries more than 50K research ideas and iteratively learn from the logs of previous experiments. Humans are, of course, more insightful, but simply can't try so many research ideas.
Unfortunately, we didn't close the loop where we apply the posttraining algorithm discovered by AI to obtain a stronger model and deploy that model to improve itself even further. This should just be the beginning of execution-grounded automated AI research. Self-improvement (AI inventing better algorithms to train itself) can be an objective for AI on its own. This is an intrinsically motivated goal for AI.
This is my last project from Stanford. Deeply grateful to @ChengleiSi for pushing it together and to @saurabhsgupta for funding us.
Embedding models are entering a golden era🔥
We’re thrilled to announce voyage-4 series, featuring the first-ever compatible embedding spaces and MoE architecture to deliver an unprecedented cost-quality balance.
https://t.co/yPWetz10Az
Plus, we’re giving back to the community with a new open-weight nano model https://t.co/dFHqM3zjg6
None of this would be possible without the relentless innovation of my team @Yujie_Qian@AkshayGoindani1 and @luo_yuping. Check it out! 🚀
Introducing Lux, the most powerful and fastest Computer Use model, built by OpenAGI Foundation @agiopen_org
Lux outperforms Google Gemini CUA, OpenAI Operator and Anthropic Claude on benchmark with 300 real-world tasks.
Try our developer-friendly SDK to build powerful, real-world applications.
🧵
📜 Paper on new pretraining paradigm: Synthetic Bootstrapped Pretraining
SBP goes beyond next-token supervision in a single document by leveraging inter-document correlations to synthesize new data for training — no teacher needed. Validation: 1T data + 3B model from scratch.🧵
📜 Paper on new pretraining paradigm: Synthetic Bootstrapped Pretraining
SBP goes beyond next-token supervision in a single document by leveraging inter-document correlations to synthesize new data for training — no teacher needed. Validation: 1T data + 3B model from scratch.🧵
@n0riskn0r3ward@spacemanidol@cohere To be honest, I think it’s more or less standard practice to tell people at least how you evaluate and what models you compare with. For example, take a look at LLM release blogposts. That said, transparency is what I’ve been insisting from day one
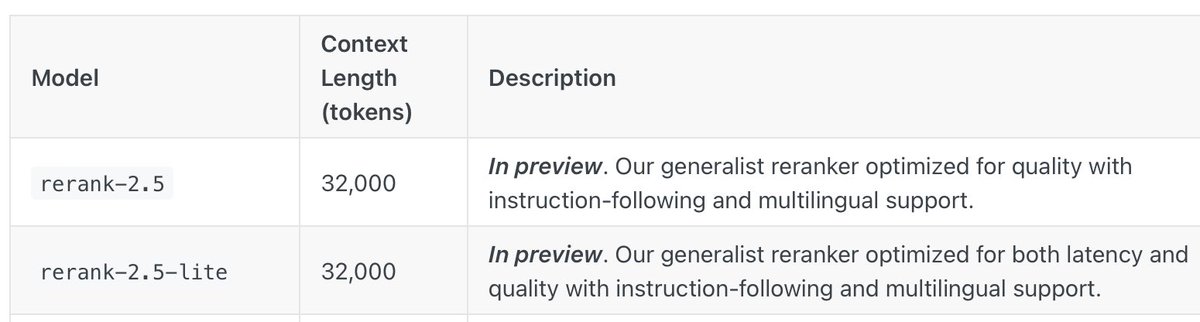
📣 Announcing rerank-2.5 and 2.5-lite: our latest generation of rerankers!
• First reranker with instruction-following capabilities
• rerank-2.5 and 2.5-lite are 7.94% and 7.16% more accurate than Cohere Reranker v3.5
• Additional 8.13% and 7.55% performance gain with instruction
Thanks for the question, but the figure is perfectly reasonable to me and I cannot see why "If you 16x the chunk size, this means you have 16x more chance to retrieve the gold passage in your top 10..." is true🙂
In this figure, voyage-context-3 has a parent document retrieval setting, which means that if you retrieve a chunk inside the ground truth document then you are correct. The model has access to all consecutive chunks in its context window. so naturally when you increase the chunk size you are converging to standard single embeddings that embed the whole document into one vector and lose the benefit of chunking because you compress too many information into very few vectors.
An analogy is a Colbert model (which you are more familiar with than me 🙂). If you change the granularity from per token to per document then you will essentially lose the gain and converge to a standard single embedding.
In comparison, voyage-3-large in this figure cannot see other chunks in the context. that's why when you split the documents to very small chunks it starts to hurt.
Great question! We of course did compare this with late chunking without any training and voyage-context-3 improved a lot. However, as you said, this is a blogpost but not a paper and we didn’t have them in the blogpost. If you are interested, feel free to reach out to [email protected] and we might be able to discuss them with you.