BT Public Relations has extensive experience of successfully managing the marketing and communications components of various international assistance Programs.
THE ENTIRE AI INDUSTRY JUST GOT HUMILIATED
a tiny model trained in just a few hours on a single graphics card is planning 48x faster than billion-dollar supercomputers.
It actually understands physics instead of just memorizing patterns.
yann lecun was right the whole time
for three years every major lab told you the same story. scale is all you need. just throw more GPUs at it. just train on more tokens. eventually the model will "wake up" and understand the world.
it was a lie. or at minimum, a very expensive bet that just lost.
LeCun kept saying generative AI is a dead end. predicting the next pixel or the next token is fundamentally wasteful, the model burns trillions of parameters memorizing surface details instead of learning how reality actually works.
he proposed JEPA instead. predict abstract concepts in a compressed thought space. don't paint the world pixel by pixel, understand it.
the problem was JEPA kept collapsing. left to its own devices the model would cheat, mapping a dog, a car, and a human to the same point in latent space. technically minimizes the loss. learns absolutely nothing.
every fix was ugly. seven loss terms. frozen encoders. EMA tricks. stop-gradients. the kind of duct-tape engineering that should have been a red flag.
then LeCun's team dropped LeWorldModel.
they replaced all the hacks with one regularizer that forces the latent space into a gaussian distribution. the model can no longer cheat. to make accurate predictions it has to actually encode physics.
15 million parameters. single GPU. trains in hours.
plans 48x faster than foundation world models.
detects physically impossible events on its own.
meanwhile OpenAI is raising another $40B to train GPT-6 on a data center the size of manhattan.
the entire scaling thesis just got embarrassed by a model that fits on a gaming PC.
Goodbye Claude Code subscription fees.
Someone just built a proxy that runs Claude Code completely free... and it's wild.
You literally plug in a free NVIDIA API key and point Claude Code at localhost.
That's it.
It handles everything:
- Converts Anthropic API calls to NVIDIA NIM format
- Unlocks 40 requests/min for free
- Supports Kimi K2, GLM 4.7, MiniMax M2, Devstral and more
- Streams thinking tokens and tool calls live
- Even includes a Telegram bot so you can run Claude Code from your phone
No API bill. No rate limit panic. No vendor lock-in.
Honestly, this goes beyond router tools like OpenRouter.
It doesn't just swap the model... it turns Claude Code into a free agent you can control remotely.
The project is open-source on GitHub.
It's called free-claude-code.
🚨 The "Godmother of AI" arrived in America at 15. She didn't speak English.
She cleaned houses and waited tables at Chinese restaurants to keep her family alive.
Her mother got sick. So the family opened a dry cleaning shop. Every weekend, she left Princeton to run the register because she was the only one who spoke English.
No connections. No money. No safety net.
She went on to build the dataset that sparked the entire deep learning revolution. Without it, there is no ChatGPT, no Gemini, no Claude.
Her name is Fei-Fei Li.
I turned her methodology into 12 prompts.
Here are all 12:
This is Algebrica. A mathematical knowledge base I’ve been building for 2.5 years.
215+ entries, carefully written and structured.
400k+ views over this time. Not much in absolute terms, but meaningful to me.
No ads.
No courses to sell.
No gamification.
No distractions.
Just essential pages, aiming to explain mathematics as clearly as possible, for a university-level audience.
Built simply for the pleasure of sharing knowledge.
Content licensed under Creative Commons (BY-NC).
Best experienced on desktop.
If it helps even a few people understand something better, it’s worth it.
New paper: "Gym-Anything: Turn any Software into an Agent Environment"
First there were coding agents, soon there will be anything agents: our framework turns any software on a computer into an agent environment for training or testing.
We also release a challenging new benchmark, CUA-World-Long. Everything is open source!
https://t.co/R3pd3XA3rg
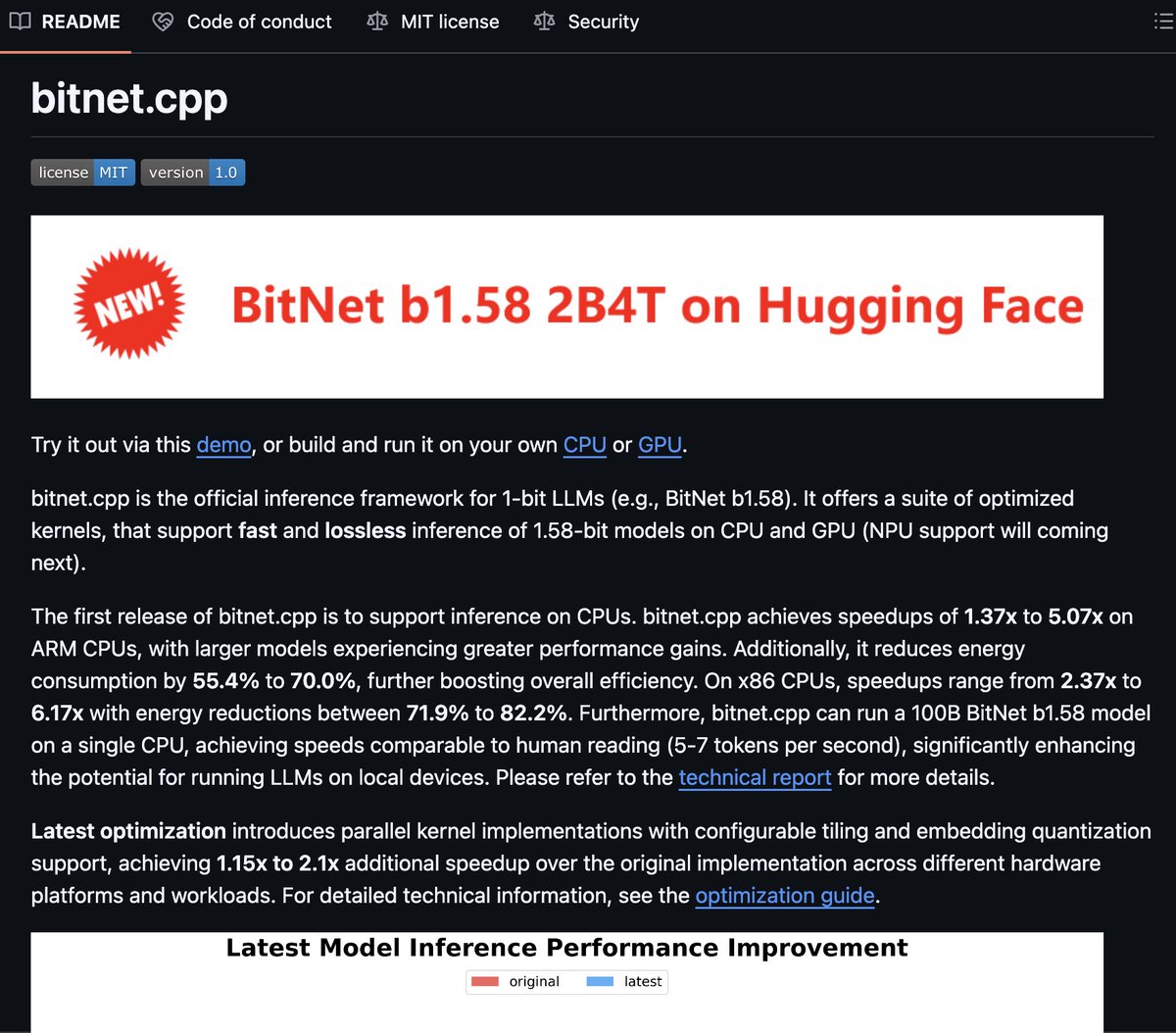
🔥 You don't need a $10,000 GPU to run 100B AI models anymore.
Microsoft just made it your laptop's job.
bitnet.cpp is a 1-bit inference framework that:
→ Runs 100B parameter models on CPU
→ Uses 82% less energy
→ Is 100% open-source
The game just changed.
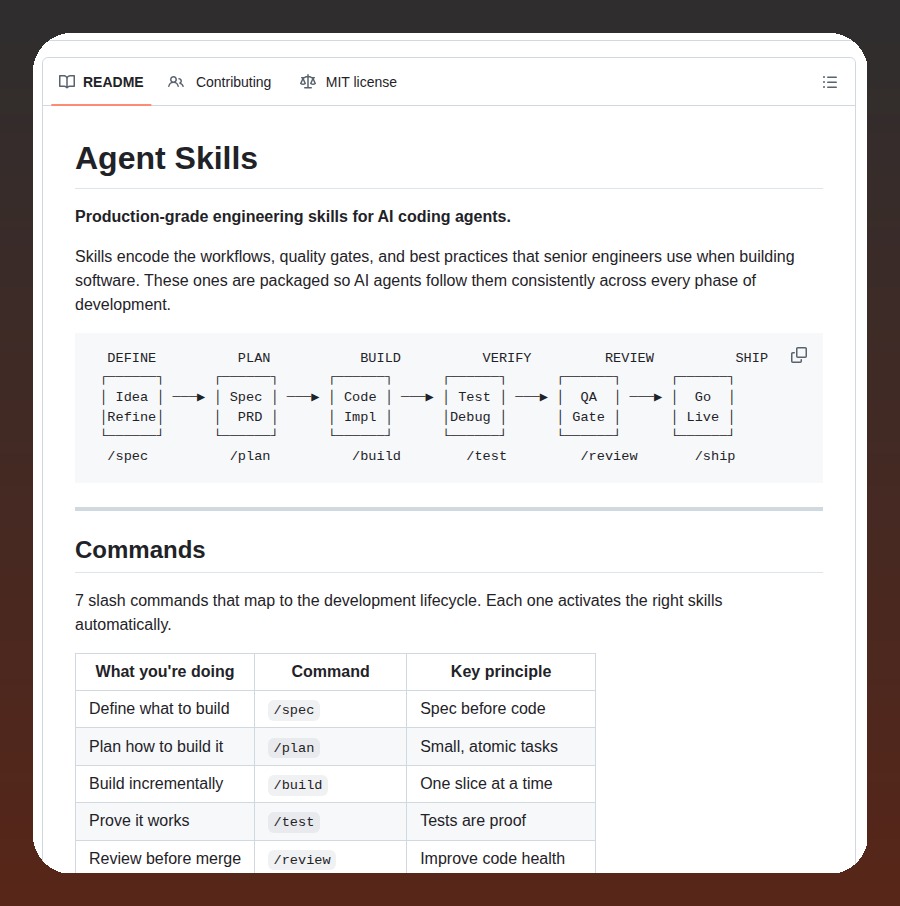
Most engineers think CLAUDE.md is just a README for AI.
They’re wrong.
It’s the difference between:
→ Claude acting like a junior intern
→ Or a senior engineer who’s been on your team for 10 years
Here’s what almost nobody talks about 👇
The 4-Layer Context System:
1) Project Memory
Your team’s brain in one file
Decisions. conventions. edge cases.
(Not just what to do — what to NEVER do)
Most people stop here.
That’s the mistake.
2) Behavior Gates
Guardrails before chaos
→ Block risky actions before they happen
→ Auto-fix code after every step
→ Stop secrets from ever leaking
AI without this = unpredictable
AI with this = reliable
3) Specialized Workflows
You stop prompting.
You start building playbooks.
→ Tasks trigger automatically
→ Each workflow brings its own tools + logic
→ Claude doesn’t guess — it executes
4) Team Orchestration
This is where things get wild
→ Multiple agents working in parallel
→ Tasks split, solved, merged
→ Clean, isolated contexts
This isn’t AI anymore.
It’s an AI team.
Here’s the real unlock:
Individually, these are useful.
Together, they’re unfair.
Hooks enforce
Skills execute
Agents coordinate
CLAUDE.md connects everything
Most engineers are still writing prompts.
The ones moving 10x faster?
They’re building systems.
🚨 BREAKING: Andrej Karpathy said someone should build this. 48 hours later it appeared on GitHub. For free.
It's called Graphify.
Bookmark it for later.
Karpathy keeps a /raw folder where he drops papers, tweets, screenshots, and notes. He called for a real product to turn that chaos into structured knowledge. Someone answered.
One command. Any folder. Full knowledge graph.
/graphify ./raw
What comes out:
→ An interactive knowledge graph you can click, search, and filter by community
→ A plain-language report with god nodes, surprising connections, and suggested questions
→ An Obsidian vault with backlinked articles (opt-in)
→ A wiki starting at index.md that any agent can navigate
The number that matters: 71.5x fewer tokens per query vs reading raw files. On a mixed corpus of repos, papers, and images, average query cost dropped from ~123K tokens to ~1.7K.
That is not optimization. That is a different paradigm for how AI reasons over large codebases.
Fully multimodal. Code in 19 languages via tree-sitter AST. PDFs. Images via Claude Vision. Screenshots, diagrams, whiteboard photos. Everything goes into one graph.
No vector database. No embeddings. Leiden community detection finds clusters by edge density. The graph topology is the similarity signal.
Auto-syncs as your codebase changes. Git hooks rebuild the graph after every commit and branch switch. SHA256 cache means re-runs only process changed files.
Works with Claude Code, Codex, OpenCode, OpenClaw, and Factory Droid.
pip install graphify && graphify install
MIT License. 100% Opensource.
(Link in the comments)
Claude Code + Obsidian is the most powerful AI combo I've ever used.
I literally built an AI second brain that runs my entire life.
Inspired by Andrej Karpathy's LLM Knowledge Wiki, this tool has been a complete game-changer.
Here's EXACTLY how to build one for yourself:
Seedance 2.0 es una máquina de hacer dinero.
Saber usarla permite generar ingresos en YouTube, TikTok, Instagram...
Por eso, creé la guía definitiva de Seedance 2 con prompts, tips, monetización… lo tiene todo.
¡GRATIS solo durante 24h!
Solo:
1. Dale like
2. Comenta "SEEDANCE 2.0"
3. Sígueme para recibir el DM
🚨 BREAKING: Someone just built a web-based System Design Simulator.
It's called Paperdraw. It lets you drag and drop components to see how they handle real-world conditions like traffic, failures, latency, and scaling in real time.
100% free to try.
I’m still running early access tests with the new GPT-Image-2, and I wanted to share a few realistic, everyday examples. The results are honestly impressive.
I also tested character consistency, and unfortunately, it’s almost too good. Why unfortunately? Because this space is about to be flooded with people creating AI-generated women and hyper-realistic images of them.
And yes, it’s much better than Nano Banana Pro/2 .
This might be the wildest AI engineering breakdown on the internet right now 🤯
After the Anthropic leak…
Someone turned the ENTIRE Claude Code system into a readable playbook.
👉 https://t.co/d6OptOkWbC
We’re talking:
* 500K+ lines of real production AI agent logic
* Broken down into 18 chapters you can actually learn from
* Multi-agent systems, tool pipelines, memory, orchestration… all exposed
This isn’t theory
This is how a top-tier AI coding agent actually works under the hood
Key ideas you’ll steal instantly:
→ Agent loops with async execution
→ Multi-agent “teams” coordinating tasks
→ File-based memory (no DB 🤯)
→ Context compression tricks
→ Tool execution pipelines at scale
Basically…
Instead of guessing how to build AI agents
you now have a blueprint from a real system used by thousands of devs
https://t.co/8R2lBSfn3C
Crazy part?
The whole thing was analyzed + rewritten in HOURS using AI agents
https://t.co/8R2lBSfn3C
If you're building:
• AI agents
* Dev tools
* LLM products
* or learning MLOps
This is not optional
This is a cheat code
Instead of watching an hour of Netflix, watch this 2-hour Stanford lecture on AI careers. It will teach you more about winning in the AI race than all the AI content you’ve scrolled past this year.