We've always been excited about self-play unlocking continuously improving agents. Our insight: RL selects generalizable CoT patterns from pretrained LLMs. Games provide perfect testing grounds with cheap, verifiable rewards. Self-play automatically discovers and reinforces reasoning strategies.
We introduce SPIRAL, where models learn reasoning by competing against themselves in games, creating an infinite curriculum without human supervision. Training LLMs with self-play RL on Kuhn Poker improves math reasoning by 8.7% average. Just playing Kuhn Poker improves Minerva Math scores by 18.1 points! 🃏
🔗 Paper: https://t.co/D7b9u4wqSg
🧑💻 Code: https://t.co/TiYyrU8UfH
Project Genie is magical... but we've also been working on some new ways to interact with another player (or agent).
It was super fun to demo this new capability at Google I/O this week, where we enabled attendees to explore worlds with Gemini as a companion. Going forward, we are incredibly excited to see how this can enable Gemini to learn how to interact with humans in embodied environments.
Some examples of interacting with Gemini in real-time within these generated worlds:
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
nice work by @DimitrisPapail and @VaishShrivas!
this work is reinforcing a recent trend that tries to make foundation models jointly predict future states (aka 'world models') and actions instead of actions alone.
we're seeing it in different forms, like World Action Models in embodied agents, or implicit world modeling in Early Experience (https://t.co/5uxJWO8b4m). also some interesting link to on-policy self-distillation.
shared learning here is, there's still rich supervision signals that are underexplored. such signals were hard to exploit in classic ML, but foundation models have made it possible, potentially creating a recursive self-improvement loop.
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
Excited to co-found Recursive (@recursive_si) with an exceptional team in London and SF to create AI that experiments on how to safely improve itself, turning compute into knowledge that accumulates in an open-ended process of endless, automated scientific discoveries.
Sharing our work on full-duplex multimodal models -- real-time interaction that's natural and intuitive without compromising on intelligence.
We started Thinky in part to differentially advance capabilities for human-AI collaboration, which are underemphasized relative to intelligence/autonomy because they're harder to eval.
In the future, we think every AI system will have something like an interaction model as the outer user-facing layer, continually keeping the user informed and learning what they actually want.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
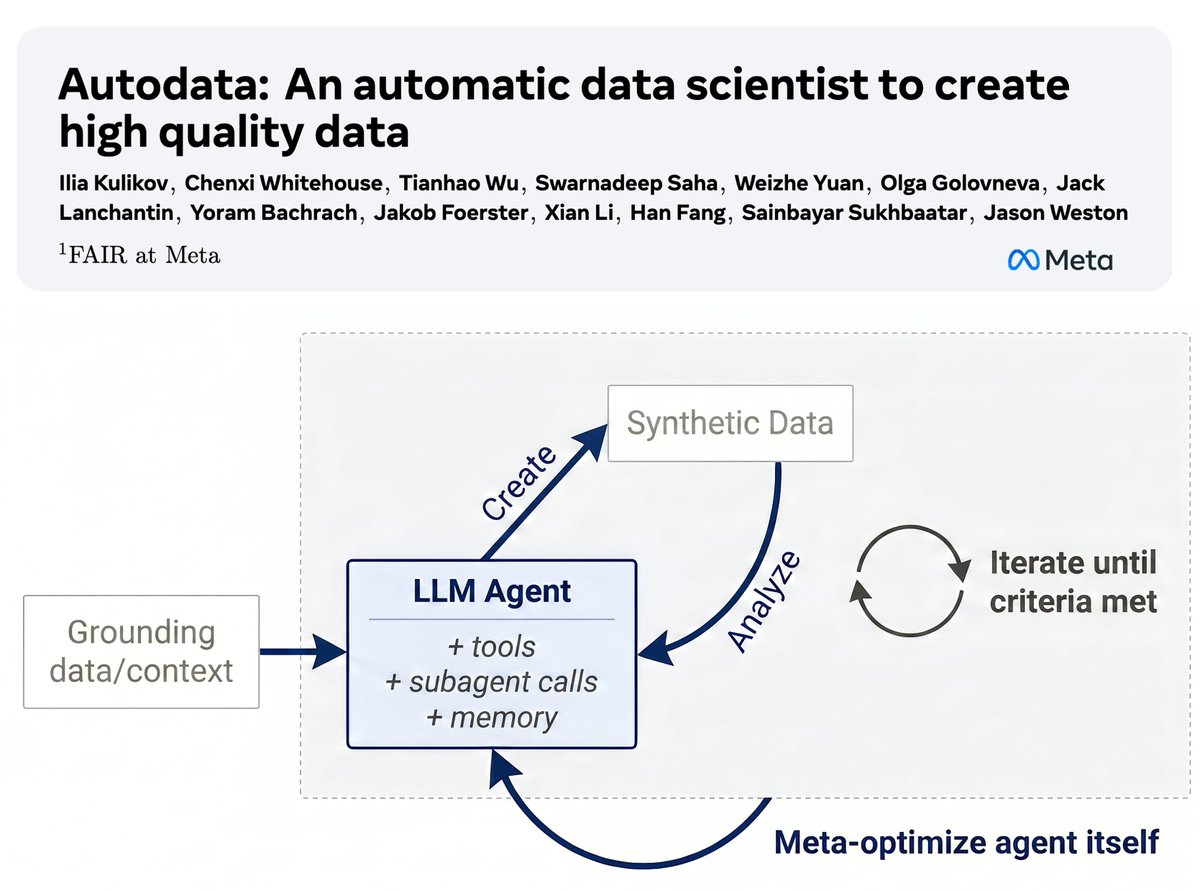
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: https://t.co/vjPvnTYfJx
Introducing Ineffable Intelligence. Led by David Silver, we're assembling the best engineers and researchers in the world to make first contact with superintelligence. We’ll be solving the hardest problems in AI on the way. Come join us.
https://t.co/zUuvPJGmcq
DeepSeek-V4 uses our Hash routing approach developed back in 2021 -- see screenshot of their tech report! (Looks like a great model, congrats!)
Bonus note: our same blogpost (& paper) back in 2021 also introduced 'looped transformers', but we called that staircase & ladder (see screenshot): https://t.co/widkeEXz56
https://t.co/PQLdPKg9PS
DeepSeek-V3: Dec 26, 2024
DeepSeek-V4: Apr 24, 2026
484 days later, we humbly share our labor of love.
As always, we stay true to long-termism and open source for all.
AGI belongs to everyone. ❤️🌍
#DeepSeekV4#AGIforEveryone#OpenSource
Introducing @NeoCognition, the agent lab for specialized intelligence.
Everyone needs experts, but human expertise does not scale.
Backed by $40M seed funding, we build self-learning agents that specialize across domains to make expertise abundant.
🧮 Reasoning over Mathematical Objects 🧮
Our 70-page(!) paper is out on arXiv, as covered by several of our recent blog posts.
We study how to improve reasoning on hard tasks (e.g., math expressions) via:
• better training data (& new evals)
• better reward models (on-policy trained)
• better inference methods (on-policy trained)
📝: https://t.co/ChcQyMDWw1
🔗Learning to Aggregate through Online RL🎯
ParaGator🔀🐊: strong parallel reasoning aggregation
Core claim: aggregation works best when training both stages together:
- LLM generator should produce diverse candidates
- LLM aggregator should synthesize into final answer
ParaGator trains candidate generation with pass@k, and aggregation with pass@1 on-policy, end-to-end.
Stops mode collapse/off-policy mismatch.
Improves math & scientific reasoning. 🚀🏆
Read more in the blog post: https://t.co/FVQ1KjoTLs
🌐Unified Post-Training via On-Policy-Trained LM-as-RM🔧
RLLM = RL + LM-as-RM:
- post-training framework that unifies RL across easy-, hard-to-verify, and non-verifiable tasks.
- trains the LM-as-RM reward model on-policy from the policy’s own outputs, then uses those generative rewards to optimize the policy. 🔗📈
- uses the LLM’s reasoning + instruction-following for higher-quality rewards — boosting performance on all task types. 🚀🤖🏆
Read more in the blog post: https://t.co/50Of5rsanm
🧮New work from @AIatMeta & @LTIatCMU!
LM reasoning benchmarks mostly use simple answers like numbers (AIME) or multiple-choice options (GPQA). But for complex mathematical objects, performance drops sharply.
We propose a set of solutions to solve this:
https://t.co/DCZcnBhztq
🧮 Principia: Training LLMs to Reason over Mathematical Objects 📐
We release:
- PrincipiaBench, a new eval for *mathematical objects* (not just numerical values or MCQ)
- Principia Collection: training data that improves reasoning across the board.
For models to help with scientific and mathematical work, you need to train on such data & test whether they can derive things like equations, sets, matrices, intervals, and piecewise functions.
We show that this ends up improving the overall reasoning ability of your model for all tasks.
Read more in the blog post: https://t.co/2VlT2PIxrX
We've witnessed a crazy concurrent line of work on on-policy self-distillation in LLMs, and I truly believe this is the next paradigm of RL.
Back in 2024, we proposed this exact conceptual shift in our paper, Natural Language Reinforcement Learning (NLRL).
The real breakthrough here isn't just the specific distillation mechanics. It’s that RL is fundamentally shifting away from the traditional "sample -> then filter or amplify" approach. Instead of passively waiting to stumble upon a good action to upweight, the field is moving toward true synthetic language data generation from experience, which enables true continual learning.
You can see this exact recipe playing out across all the recent hit papers:
• RLTF (2602.02482): Text critiques as privileged info
• OPSD (2601.18734): Ground-truth solutions
• SDPO (2601.20802): Runtime errors & execution feedback
• ERL(2602.13949): Self-reflections & demonstrations
Instead of just using a scalar reward to filter bad rollouts, they all use language feedback to explicitly generate a corrected, high-quality trajectory in hindsight, and then distill that competence back into the base policy.
While the specific ways we adapt RL to LLMs are still rapidly evolving, the core vision we outlined in NLRL holds true today: a single scalar is simply too poor of a carrier for credit assignment.
When people talk about "experiential memory" for agents today, they are essentially describing what we framed as a Language Value Function (LVF)—not just RAG over past episodes, but storing the structured, strategy-level "why" behind what worked. And what we called "Language Policy Improvement" is exactly this feedback-aware self-distillation loop we see everywhere now.
Language, not scalars, is the future of RL.
📄 Check out our early exploration of this framework here: https://t.co/k94IQxs8eC