@sirbayes Super clever idea to make smaller LLMs reliable in TextArena!
Quick question: do you plan to open-source the code?
Would love to try it out and build on it.
Thanks!
Great question! Two main lenses:
1. Systems: most prior frameworks share the similar conceptual loop but are tightly coupled, so changing one component often requires rewriting the system.
2. Algorithmic: many existing methods rely on fixed strategies/parameters even though the search dynamics change over time.
That motivated a modular framework + adaptive algorithms that can adjust (AdaEvolve), or even evolve the evoler (EvoX) itself!
Tired of debugging LLMs by reading the extremely long chain of thoughts?
We built Landscape of Thoughts (LoT) to transform complex thoughts into intuitive visual maps to help you understand model behaviors.
Paper and findings in 🧵
1/10
https://t.co/6K2Kj2L9EX via @YouTube
There are traditionally two types of research: problem-driven research and method-driven research. As we’ve seen with large language models and now AlphaEvolve, it should be very clear now that total method-driven research is a huge opportunity.
Problem-driven research is nice because you have a consistent and specific goal. The goal is usually virtuous, so it feels good to have a mission and identity. However, it just doesn’t work due to The Bitter Lesson. Basically everything in classical NLP (machine translation, summarization, chatbots) lost to simple scaling. ChatGPT is a prime example—it used nothing from chatbot research and certainly wasn’t the intended end goal of OpenAI’s 2022 research program, but was a huge hit because someone (John Schulman et al) figured out the right way to package large language models as a product.
Method-driven research feels less stable because you’re constantly searching for problems and you have to be opportunistic. But I believe AI will allow method-driven research to dominate progress in most fields of science, one-by-one. The latest method (or “hammer”), as we’ve seen in AlphaEvolve, is ruthless search and optimization against a reward function (whether this requires RL or not is a separate discussion). Things that problem-driven researchers have been trying to solve for a long time like the kissing number problem will become nails hit by the hammer. Eventually the hammer will become bigger, stronger, and more general and will hit more and more nails.
So a very important meta-skill for the next decade will be knowing how to create the right environments to use The Hammer. Ironically, the problem-driven researchers, who by definition are experts in a specific problem, are well-positioned to create these environments. If, that is, they can put down their egos and pick up the hammer.
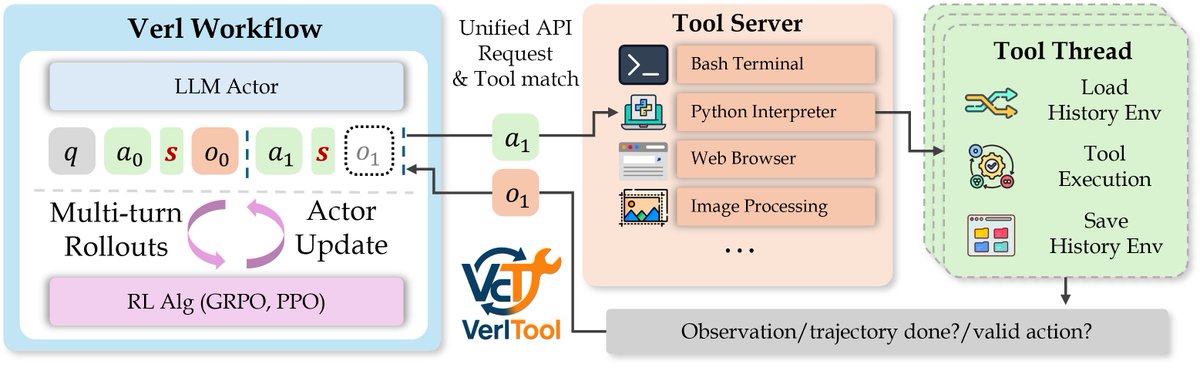
Introducing VerlTool - a unified and easy-to-extend tool agent training framework based on verl.
Recently, there's been a growing trend toward training tool agents with reinforcement learning algorithms like GRPO and PPO. Representative works include SearchR1, ToRL, ReTool, and ToolRL. While these achieve impressive performance, their training codes are either not fully open-sourced or too difficult to modify and customize with new tools, creating unexpectedly high engineering costs for the community when exploring new ideas.
To address these issues and reduce engineering overhead, we propose verl-tool.
Key Features:
1. 🔧 Complete decoupling of actor rollout and environment interaction - We use verl as a submodule to benefit from ongoing verl repo updates. All tool calling is integrated via a unified API, allowing you to easily add new tools by simply adding a Python file and testing independently.
2. 🌍 Tool-as-environment paradigm - Each tool interaction can modify the environment state. We store and reload environment states for each trajectory. For each training, you can launch
3. ⚡ Native RL framework for tool-calling agents - verl-tool natively supports multi-turn interactive loops between agents and their tool environments.
4. 📊 User-friendly evaluation suite - Launch your trained model with OpenAI API alongside the tool server. Simply send questions and get final outputs with all interactions handled internally.
We've successfully reproduced ToRL results using our verl-tool framework, demonstrating its correctness and demonstrating comparable performance on mathematical benchmarks.
VerlTool is an active ongoing project! We aim to incorporate more tools covering a wide range of use cases and expect they can be trained together in a single framework. Suggestions and contributions are highly welcomed!
Check out our GitHub: https://t.co/gmhic1BVPU
More details: 👇 (0/4)