Research Scientist @GoogleDeepMind
Discussing RL, memory, openendedness, continual learning,automated science
ex-IMO(Canada)
ex-neuroscientist
Views are my own
From our team at @GoogleDeepMind: we ask, as an LLM continues to learn, how do new facts pollute existing knowledge? (and can we control it)
We investigate such hallucinations in our new paper, to be presented as Spotlight at @iclr_conf next week.
Happy that my friends (and former Google DeepMinders) @edwardfhughes and @LouisKirschAI
have launched their new startup @inherent_labs! No doubt they are going to solve self improvement 🧙♂️
For a sampler of their vision, check out this talk (https://t.co/n0pTPB0Yay) by @edwardfhughes on the AI of the future, simply sublime~
We’re excited to introduce Inherent, a lab designed from scratch to build AI agents that discover new knowledge.
The coming era of machine-driven scientific inquiry demands a new kind of research institution and a new kind of AI.
To achieve our mission, we live within the experiment, recursively self-improving the entire research organisation. We investigate questions including:
- What does ‘AI taste’ look like in the sciences, and how can we build an institution that embraces this new aesthetic of discovery?
- What new kinds of human-machine teaming will make the most of AI that can truly innovate?
- How can we build recursive self-improvement at the collective level that continually increases human agency over outcomes?
We have just closed a $50m seed round led by @IndexVentures and @radicalvcfund, with participation from other outstanding investors including NVentures (@nvidia's venture capital arm), @buildexante, Metaplanet, Macroscopic, @MythosVentures, Charlie Songhurst, @chalfs, @jluan, @dwarkesh_sp, @Thom_Wolf, @j_foerst and @maxjaderberg. We are advised by @matthewclifford.
Inherent is a Public Benefit Corporation headquartered in London.
Everybody is talking about recursive self-improvement (RSI) and meta learning. Here is my old 2020 talk about this [1]. It has aged well. Example: humans still define the starts & ends of trials of many modern meta learners. My RSI systems since 1994 LEARN to (re)define them [2]!
[1] Meta Learning Machines in a Single Lifelong Trial (talk for workshops at ICML 2020 and NeurIPS 2021, based on earlier talks since 1994). Abstract: the most widely used machine learning algorithms were designed by humans and thus are hindered by our cognitive biases and limitations. Can we also construct meta learning algorithms that can learn better learning algorithms so that our self-improving AIs have no limits other than those inherited from computability and physics? This question has been a main driver of my research since I wrote a thesis on it in 1987 [2]. Here I summarize our work on meta reinforcement learning with self-modifying policies in a single lifelong trial (since 1994), and mathematically optimal meta-learning through the self-referential Gödel Machine (since 2003). Many additional publications on meta-learning since 1987 can be found in the RSI overview [2].
[2] J. Schmidhuber (AI Blog, 2020-2025). 1/3 century anniversary of first publication on recursive self-improvement (RSI) and meta learning machines that learn to learn (1987). For its cover I drew a robot that bootstraps itself. 1992-: gradient descent-based neural meta learning. 1994-: meta reinforcement learning with self-modifying policies. 1997: meta RL plus artificial curiosity and intrinsic motivation. 2002-: asymptotically optimal meta learning for curriculum learning. 2003-: mathematically optimal Gödel Machine. 2020-: new stuff!
Every developer has an IDE. Researchers never had one.
We don’t need another research agent, but a full stack workstation powered by AI.
Today we're launching Orchestra @orch_research, the world's first Research IDE 🔬🧵
Excited to be hosting at the @thought_channel Conference on the Mathematics of Neuroscience and AI in Rome! https://t.co/TDlo4WIsGf
With @RMBattleday, @jcrwhittington, and others!
Submit an abstract to this awesome conference!
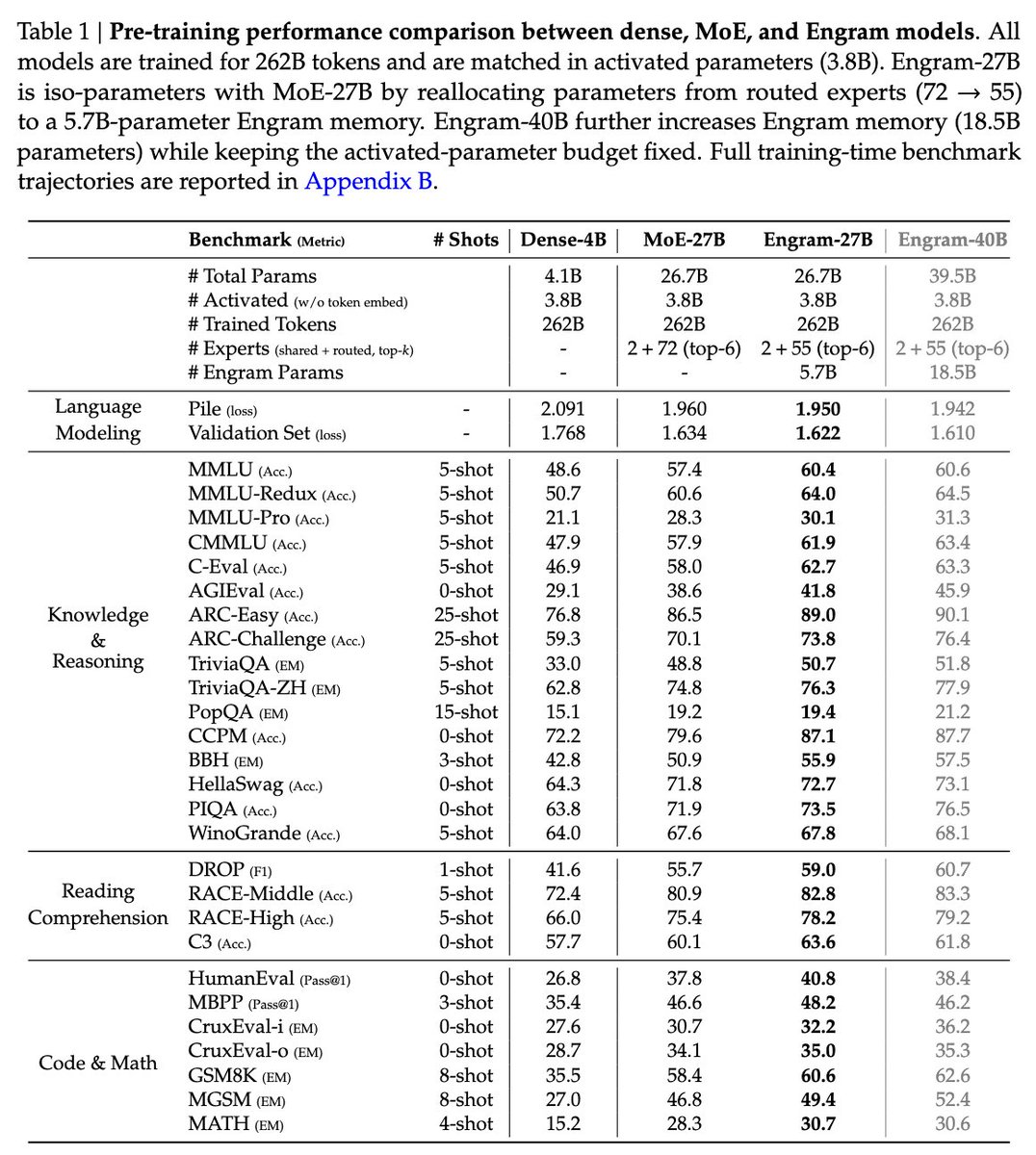
DeepSeek's Engram succeeds where others failed in this endeavor to replace a transformer's crappy FFN with a symbolic-ish lookup table. And in the process, it reveals what I think is a truly gorgeous, monumental even, paradigm shift in our understanding of transformer capability 🌹 🚨
To begin the story, explicitly replacing an FFN with a symbolic lookup table fails catastrophically (desirable as it may be, rather than wasting training compute to do this through FFN layers) because language explodes, guaranteeing collisions and polysemy that a rigid lookup cannot resolve.
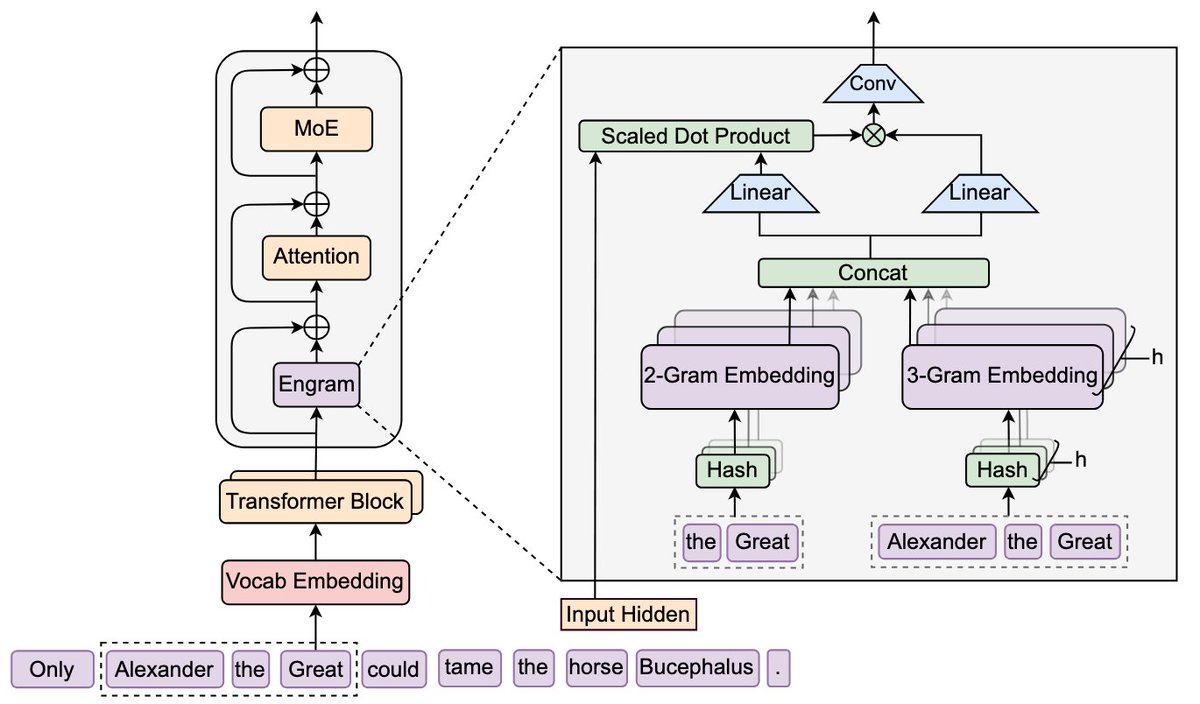
Engram's cool solution to this relies on 3 complementary ingredients:
1) Learnable "Superposition" Embeddings. Because the table is co-trained rather than fixed, the optimizer learns a dense vector that mathematically represents a "superposition" of multiple concepts. It minimizes the global loss for all colliding inputs simultaneously rather than storing a single rigid value. Therefore, even though collisions are guaranteed, you can learn the superposition of the most useful memories.
2) Context-Aware Gating. This seems to be a further "fail-safe" that makes this learned hashing viable, via the dynamic gate $\alpha_t$. Even after you have retrieved the memory, it forces the backbone to check the retrieved memory against the current semantic context; if the hash returns noise (a collision) or irrelevant polysemy, the gate snaps shut ($\alpha ~ 0$), effectively filtering the signal.
3) it is placed in a middle layer: If you place it at Layer 0, you force the model to decide how much to trust the memory before it has read the rest of the sentence. But if you place it in a middle layer, it can then use its Gate ($\alpha_t$) in a way that is not simply a dictionary but rather a context-dependent memory.
And here is the crux:
this study reveals a monumental critical inefficiency in modern architecture: standard Transformers waste valuable sequential depth and attention capacity ... effectively simulating ... static lookup tables for local patterns.
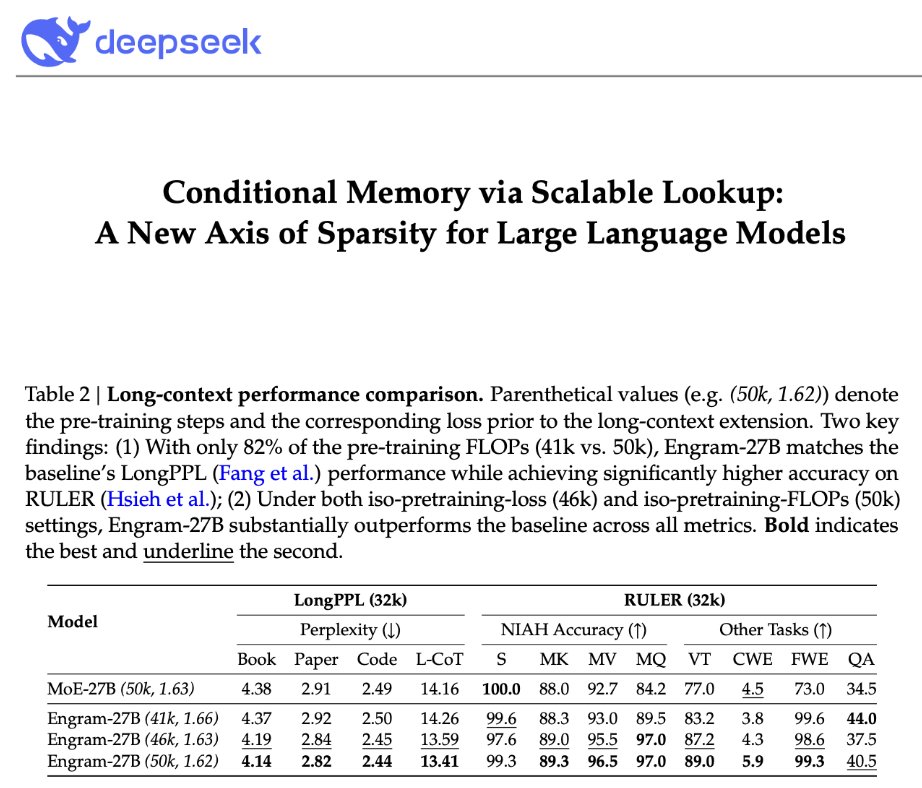
The authors demonstrate that if one simply offloads these trivial dependencies to the Engram module, the model stops "polluting" its attention heads with basic dictionary work ( it really is basic 2-3 token dictionary work), and -- makes it suddenly able to perform signficantly better on very long context tasks. It is almost as if a burden had been relieved!
Crucially - this offloading was achieved not through expensive semantic retrieval, but via "dumb," deterministic hash lookups. This compels us to ask:
Have we been over-engineering memory by assuming retrieval must be semantic?
If a 'fractured' lexical lookup can outperform deep neural computation, should future architectures abandon the expensive vector database paradigm in favor of massive, dumb hash tables? (provided we have a smart context-aware filtering)
Let me know, friends, what you think! 🧙♂️
DeepSeek is back!
"Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models"
They introduce Engram, a module that adds an O(1) lookup-style memory based on modernized hashed N-gram embeddings
Mechanistic analysis suggests Engram reduces the need for early-layer reconstruction of static patterns, making the model effectively "deeper" for the parts that matter (reasoning)
Paper: https://t.co/vHcxXW9cBv
@yoyu0203 brings up an interesting question (below) whether something can be additionally done for long phrase as well. Ie if we’re going to reform memory, might as well reform it wholly.
Curious what others think
@yoyu0203 Thanks! That’s my intuition as well. But it seems that’s all that’s needed, ie a simple mechanism to relieve the burden of short phrase lookup frees the attention to do better long context management, resulting in performance gains over lost in the middle phenomena
How to build an LLM agent setup with true open endedness is a bitterly difficult question, and to date, most setups from the various AI Scientists (Sakana's, Alpha Evolve, the various Godel machines, etc.) have built subsets of necessary ingredients but no one yet has them all. 🚨
These setups (to date) can almost always be framed as resource competition, e.g. the mutation / selection algorithms in all the above examples are competition for CPU cycles , on the basis of their fitness in solving static tasks.
But this beautiful work by @akarshkumar0101@risi1979@hardmaru and others on DRQ sharply reminds us of the most important missing ingredient: agent-agent interaction to affect each other's survival. When it's just resource competition, there really isn't direct interaction - each individual does its own thing and tries to be fit. But with interaction, you get offensive actions, parasitisms, collective defense, etc.
This then results in the fitness Landscape itself being dynamic: The fitness landscape shifts constantly ("Red Queen" dynamics), forcing continuous adaptation rather than convergence to a static peak.
The dynamic landscape comes with its own pandoras box of complications, which brings DRQ second trick: to harness this chaos without spiraling into "Rock-Paper-Scissors" cycles, they introduce a history-based fitness function:
w_{t} = argmax}_w E[Fitness(w; w_0 .. w_t-1})]
By forcing the new agent w_t to defeat the entire lineage of ancestors ($w_0 \dots w_{t-1}$) simultaneously, the system creates an inescapable "ratchet" that demands generalist robustness.
###############################
Even still, it seems to me this story is far from over.
At the end of the day, even their setup gets convergent evolution (which, don't get me wrong, is a super interesting result) -- despite infinite coding freedom, diverse lineages independently converge onto a "Universal Attractor" phenotype.
The true novelty, never ending, never converging, as seen in real biological and cultural evolution, as @kenneth0stanley and @joelbot3000 have talked about, is still elusive in LLM agentic systems.
Curious, friends, for your thoughts! 🧙♂️
Check out our new Digital Red Queen work!
Core War is a programming game where assembly programs fight against each other for control of a Turing-complete virtual machine.
We ask what happens when an LLM drives an evolutionary arms race in this domain.
We find that as you run our DRQ algorithm for longer, the resulting programs become more generally robust, while also showing evidence of convergence across independent runs - a sign of convergent evolution!
@0xjasper I like this intuition! What do you mean by higher order objectives? Do you mean things like adaptability, complexity etc?
And their perhaps implicit relation to causal discovery?
Fundamentally, what really is the difference between an RLM and S={context folding, Codex, Claude Code, Terminus, agents, etc.}?
This is the last and most important RLM post I'll make for a while to finally answer all the "this is trivially obvious" from HackerNews, Reddit, X, etc. I know there's a lot of noise rn, but this is the one thread I'd rly ask you not to skip!
For a while I didn't have a super clear answer to this. and no, it's NOT that:
1. CC sub-agents are user-defined while the LM defines the sub-agent in RLMs. this is a minor difference that I suspect Anthropic will phase out at some point
2. Coding scaffolds use a file system while the original paper uses a Python REPL. In fact, FS is a REPL.
3. RLMs offload context into a variable. CC / Codex implicitly do this by saving to files, and yes, I know that people have been doing this for time
But I think after some long convos with @lateinteraction@zli11010 and @ChenSun92, I can articulate a lot better that all of these things are important but are missing what actually matters.
RLMs enable **symbolic recursion** -- this means the RLM can spawn recursive calls embedded in symbolic logic. In simple terms, the recursive LM call lives inside the REPL. While for CC / Codex, the sub-agent call is spawned directly as a tool by the main model. This is a subtle difference but extremely significant.
Consider the following example. Say I want my agent to ingest 1M files and find a function I'm looking for.
1. The CC model will hopefully sequentially launch 1M JSON-like sub-agent tool calls per file in its main context, get the answer for each (maybe save to a file), and return.
2. The RLM will write a for-loop / parallel map over each sub-agent call to open each file, save to a var / file, and grab the answer.
The problem here is that we rely on Opus 4.5 to perform a programmatic action (launch 1M sub-agent calls) without the guarantee that it'll actually do it. Now maybe it's good enough to do this, but consider a nastier task, where we want to launch sub-calls only for files satisfying some weird property P (this is quite common for say looking at databases or complicated monorepos). In fact, all tool calls are launched this way, which is fundamentally limiting (we already write code to programmatically perform operations (e.g. search if XYZ)!
The tldr; here is that the REPL and sub-calling tool being *separate* is not a good thing. It's such a subtle / simple point but it lends itself extremely well to more robust / programmatic model reasoning through training. Beyond the fact that CC / Codex are trained specifically for coding tasks, this minor difference leads to a whole class of new solutions that RLMs can solve.
(Thanks to @zli11010 for this point) From a PL perspective, the way Codex / CC handle sub-agents is almost *silly*. If we think of the REPL that the RLM uses as a "language" or sorts, sub-calling should be a feature of this language. It shouldn't be separate, and is strictly less expressive than the RLM design.
Hope this clears things up, happy to answer more questions but I plan on updating the paper to articulate this better and make things clearer :)


















![ChenSun92's tweet photo. How to build an LLM agent setup with true open endedness is a bitterly difficult question, and to date, most setups from the various AI Scientists (Sakana's, Alpha Evolve, the various Godel machines, etc.) have built subsets of necessary ingredients but no one yet has them all. 🚨
These setups (to date) can almost always be framed as resource competition, e.g. the mutation / selection algorithms in all the above examples are competition for CPU cycles , on the basis of their fitness in solving static tasks.
But this beautiful work by @akarshkumar0101 @risi1979 @hardmaru and others on DRQ sharply reminds us of the most important missing ingredient: agent-agent interaction to affect each other's survival. When it's just resource competition, there really isn't direct interaction - each individual does its own thing and tries to be fit. But with interaction, you get offensive actions, parasitisms, collective defense, etc.
This then results in the fitness Landscape itself being dynamic: The fitness landscape shifts constantly ("Red Queen" dynamics), forcing continuous adaptation rather than convergence to a static peak.
The dynamic landscape comes with its own pandoras box of complications, which brings DRQ second trick: to harness this chaos without spiraling into "Rock-Paper-Scissors" cycles, they introduce a history-based fitness function:
w_{t} = argmax}_w E[Fitness(w; w_0 .. w_t-1})]
By forcing the new agent w_t to defeat the entire lineage of ancestors ($w_0 \dots w_{t-1}$) simultaneously, the system creates an inescapable "ratchet" that demands generalist robustness.
###############################
Even still, it seems to me this story is far from over.
At the end of the day, even their setup gets convergent evolution (which, don't get me wrong, is a super interesting result) -- despite infinite coding freedom, diverse lineages independently converge onto a "Universal Attractor" phenotype.
The true novelty, never ending, never converging, as seen in real biological and cultural evolution, as @kenneth0stanley and @joelbot3000 have talked about, is still elusive in LLM agentic systems.
Curious, friends, for your thoughts! 🧙♂️](https://pbs.twimg.com/media/G_PzKknbcAAJCUI.jpg)





























